
Python如何实现删除pdf空白页
作者:去追风,去看海
这篇文章主要为大家详细介绍了如何使用Python实现删除pdf空白页以及批量删除扫描PDF中的空白页,文中的示例代码简洁易懂,需要的小伙伴可以了解下
python 删除pdf 空白页
环境
python == 3.10
PyPDF2 ==3.0.1
安装
pip install PyPDF2
流程
将空白页和内容页读取出来,看看内部结构有什么不同
以此为依据,遍历整个PDF 文件,标记处有内容的页面,写入到另外一个PDF文件。
python 代码
# 每一个页都是一个字典对象,看第一层没区别
# 参考文章中 第一层 keys 一样, 但是 /Resources下结构有所不同,空白页没有"/XObject"键
# 我的第一层keys 不一样, 但是 /Resources下结构一样
# 另外 PyPDF2 版本不一样,各个模块有更新,自己看源码进行更新,或者根据报错提示进行更新
from PyPDF2 import PdfReader, PdfWriter
def remove_pdf_blank_pages(path):
pdfReader = PdfReader(open(path, 'rb'))
writer = PdfWriter()
pages = len(pdfReader.pages)
# blank = pdfReader.pages[1]
# full = pdfReader.pages[2]
#print('*'*10)
#print(blank.keys())# dict_keys(['/Type', '/Parent', '/Resources', '/MediaBox', '/Contents'])
#print(full.keys())# dict_keys(['/Type', '/Parent', '/Resources', '/MediaBox', '/Annots', '/Tabs', '/StructParents', '/Contents'])
#print(blank['/Resources'])
#{'/Font': IndirectObject(600, 0, 139632281578944), '/XObject': {'/Im553': IndirectObject(553, 0, 139632281578944), '/Im7': IndirectObject(7, 0, 139632281578944)}, '/ProcSet': ['/PDF', '/Text', '/ImageC', '/ImageI', '/ImageB']}
#print(full['/Resources'])
#{'/Font': IndirectObject(600, 0, 139632281578944), '/XObject': {'/Im553': IndirectObject(553, 0, 139632281578944), '/Im7': IndirectObject(7, 0, 139632281578944)}, '/ProcSet': ['/PDF', '/Text', '/ImageC', '/ImageI', '/ImageB']}
#print('*' * 10)
for i in range(pages):
page = pdfReader.pages[i]
# if "/XObject" in page["/Resources"].keys() or "/Font" in page["/Resources"].keys():
# writer.add_page(page)
if "/StructParents" in page.keys() or "/Tabs" in page.keys() or "/Annots" in page.keys():
writer.add_page(page)
writer.write(open(path, 'wb'))
使用Python批量删除扫描PDF中的空白页
对于经常看扫描PDF资料的人来说,经常会碰到如下问题:
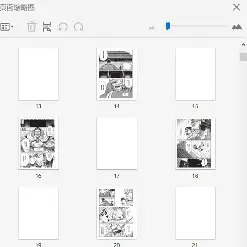
PDF缩略图
因为一些格式转换的原因,一些空白页时不时的出现,而且规律不定,一会是偶数页码一会是奇数页码,逐个选中删除的话,对于几百页的文档,非常费时。
百度搜索删除PDF空白页,得到的是一个要收费的工具,有了Python就可以利用免费开源库轻松解决。
先安装 PyPDF2库,在Powershell 或CMD命令行模式安装PyPDF2
Install PyPDF2
流程
将空白页和内容页读取出来,看看内部结构有什么不同,以此为依据,遍历整个PDF 文件,标记处有内容的页面,写入到另外一个PDF文件。
该文件中17页为空白页,18页为内容页:
from PyPDF2 import PdfFileReader, PdfFileWriter path=r"D:\ebook\PDF\test.pdf" reader = PdfFileReader(open(path, 'rb')) """ 注意PyPDF2中页码从0开始 """ blank= reader.getPage(16) full = reader.getPage(17)
每一个页都是一个字典对象,看第一层没区别
blank.keys() Out[24]: dict_keys(['/Type', '/Contents', '/Parent', '/Resources', '/MediaBox']) full.keys() Out[25]: dict_keys(['/Type', '/Contents', '/Parent', '/Resources', '/MediaBox'])
经查发现/Resources下结构有所不同,空白页没有"/XObject"键:
blank['/Resources']
Out[26]: {'/ExtGState': {'/Opa0': {'/Type': '/ExtGState', '/CA': 1}}}
full['/Resources']
Out[27]:
{'/ExtGState': {'/Opa0': {'/Type': '/ExtGState', '/CA': 1},
'/Opa1': {'/Type': '/ExtGState', '/ca': 1}},
'/XObject': {'/Image0': {'/BitsPerComponent': 8,
'/Height': 1130,
'/Filter': ['/DCTDecode'],
'/ColorSpace': '/DeviceRGB',
'/Type': '/XObject',
'/Subtype': '/Image',
'/DL': 434222,
'/Width': 792}}}
所以对于有”/XObject“键的,就是有图像的页面。同时发现一些只有文字没图像的页面,还有"/Font" 键,于是将有这两个键的页面标记,然后写入第二个PDF文件即可:
from PyPDF2 import PdfFileReader, PdfFileWriter
path = r"D:\ebook\PDF\test.pdf"
path_output = r"D:\ebook\PDF\output.pdf"
reader = PdfFileReader(open(path, 'rb'))
writer = PdfFileWriter()
pages = pdfReader.getNumPages()
for i in range(pages):
page = reader.getPage(i)
if "/XObject" in page["/Resources"].keys() or "/Font" in page["/Resources"].keys():
writer.addPage(page)
writer.write(open(path_output, 'wb'))到此这篇关于Python如何实现删除pdf空白页的文章就介绍到这了,更多相关Python删除pdf空白页内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!