
Pandas中数据合并的实现
作者:浮云H
本文介绍了使用Pandas库进行数据合并,包括堆叠合并和主键合并,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
一、数据合并
1.堆叠合并数据
1)横向堆叠:用concat()函数
当axis=1时,concat做行对齐,然后将不同列名称的两张或多张表合并。当两个表索引不完全相同时,可以使用join参数选择是内连接还是外连接。在内连接的情况下,仅仅返回索引重叠部分;在外连接的情况下,则显示索引的并集部分数据,不足的地方使用空值填补。
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3'], 'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']}, index=[0, 1, 2, 3])
df2 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'], 'D': ['D2', 'D3', 'D6', 'D7'], 'F': ['F2', 'F3', 'F6', 'F7']},
index=[2, 3, 6, 7])
result = pd.concat([df1, df2], axis=1, join='inner')
print(result)结果:
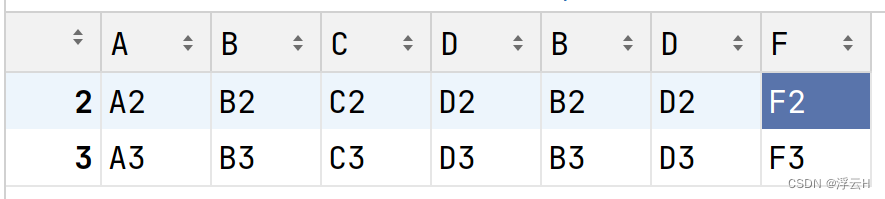
result = pd.concat([df1, df2], axis=1, join='outer') print(result)
结果:
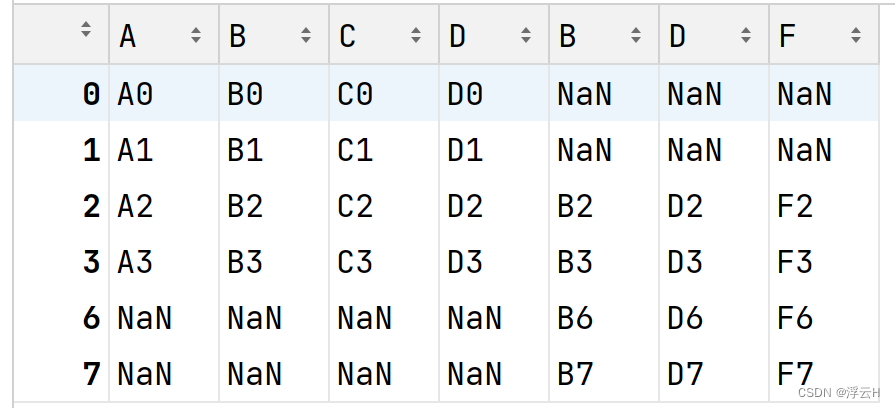
2)纵向堆叠:用concat()函数和append()函数
使用concat()函数时,在默认情况下,即axis=0时,concat做列对齐,将不同行索引的两张或多张表纵向合并。在两张表的列名并不完全相同的情况下,可以使用join参数:取值为inner时,返回的仅仅是列名的交集所代表的列;取值为outer时,返回的是两列名的并集代表的列。
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3'], 'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']}, index=[0, 1, 2, 3])
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'], 'B': ['B4', 'B5', 'B6', 'B7'], 'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']}, index=[4, 5, 6, 7])
df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'], 'B': ['B8', 'B9', 'B10', 'B11'], 'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']}, index=[8, 9, 10, 11])
frames = [df1, df2, df3]
result = pd.concat(frames, axis=0)
print(result)结果:
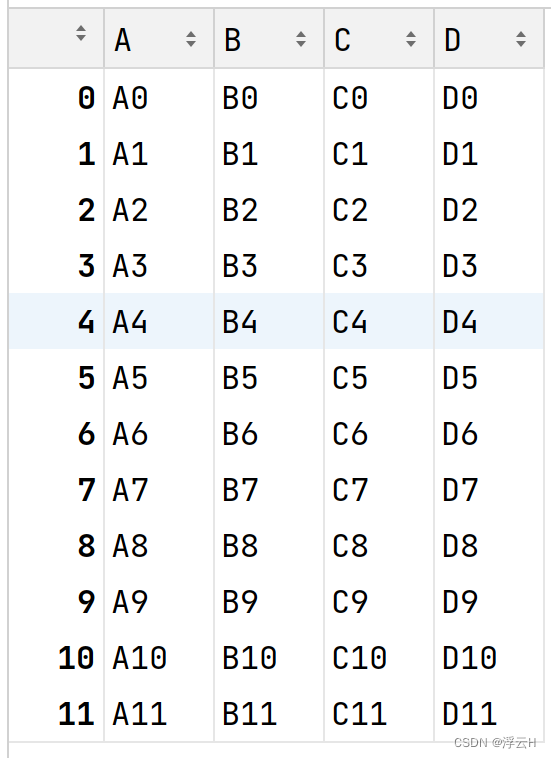
append()函数实现纵向表堆叠有一个前提条件,即两张表的列名需要完全一致。但是append应该是用不了了。
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3'], 'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']}, index=[0, 1, 2, 3])
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'], 'B': ['B4', 'B5', 'B6', 'B7'], 'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']}, index=[4, 5, 6, 7])
result = df1.append(df2)
print(result)结果:
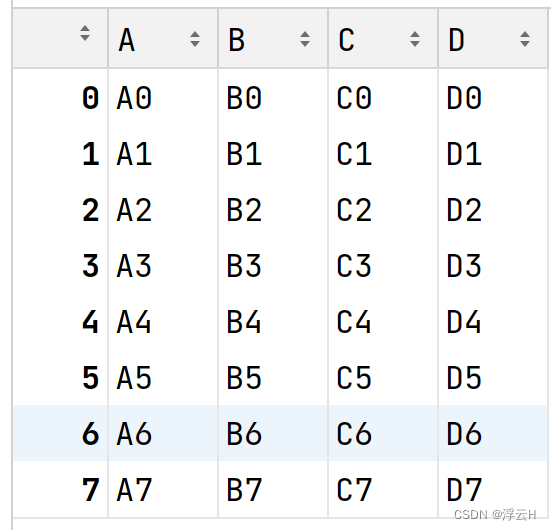
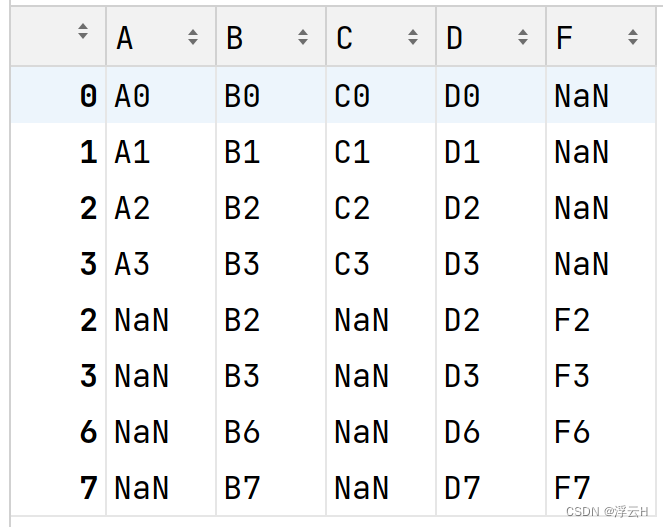
df2 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'], 'D': ['D2', 'D3', 'D6', 'D7'], 'F': ['F2', 'F3', 'F6', 'F7']},
index=[2, 3, 6, 7])
result = df1.append(df2)
print(result)结果:
2.主键合并数据
使用merge()函数和join()函数
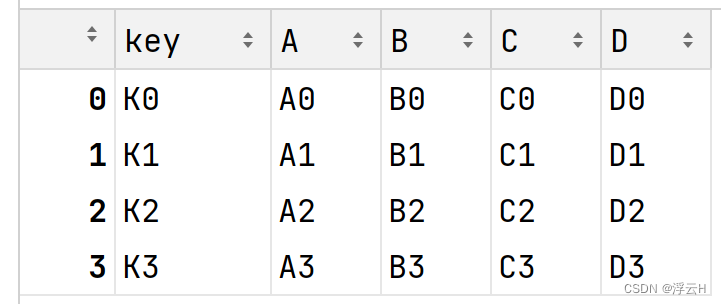
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'], 'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'], 'C': ['C0', 'C1', 'C2', 'C3'], 'D': ['D0', 'D1', 'D2', 'D3']})
result = pd.merge(left, right, on='key')
print(result)结果:
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'], 'key2': ['K0', 'K1', 'K0', 'K1'], 'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'], 'key2': ['K0', 'K0', 'K0', 'K0'], 'C':['C0', 'C1', 'C2', 'C3'],
'D':['D0', 'D1', 'D2', 'D3']})
result = pd.merge(left, right, on=['key1', 'key2'])
print(result)结果:
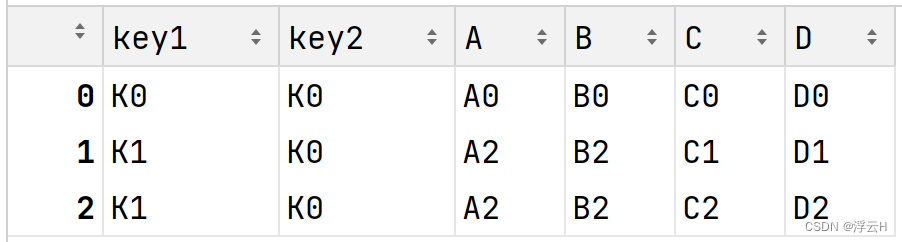
解释是如何合并的:
第一行(‘K0’, ‘K0’, ‘A0’, ‘B0’, ‘C0’, ‘D0’):
left中的第一行(‘K0’, ‘K0’, ‘A0’, ‘B0’)与right中的第一行(‘K0’, ‘K0’, ‘C0’, ‘D0’)在key1和key2上都有匹配,所以它们被合并在一起。
第二行和第三行(‘K1’, ‘K0’, ‘A2’, ‘B2’, ‘C1’, ‘D1’ 和 ‘K1’, ‘K0’, ‘A2’, ‘B2’, ‘C2’, ‘D2’):
left中的第三行(‘K1’, ‘K0’, ‘A2’, ‘B2’)与right中的第二行和第三行(‘K1’, ‘K0’, ‘C1’, ‘D1’ 和 ‘K1’, ‘K0’, ‘C2’, ‘D2’)在key1和key2上都有匹配,所以它们被合并在一起。由于right中有两行与left的第三行匹配,所以结果中有两行合并后的数据。
left中的第四行(‘K2’, ‘K1’, ‘A3’, ‘B3’)和
right中的第四行(‘K2’, ‘K0’, ‘C3’, ‘D3’):- 这两行在
key1上匹配,但在key2上不匹配(left是’K1’,right是’K0’)。由于内连接只保留完全匹配的行,所以这行不会被包括在结果中。
- 这两行在
到此这篇关于Pandas中数据合并的实现的文章就介绍到这了,更多相关Pandas 数据合并内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!