
python中pandas.read_csv()函数的实现
作者:程序员洲洲
本文主要介绍了python中pandas.read_csv()函数的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
前言
在Python的数据科学和分析领域,Pandas库是处理和分析数据的强大工具。
pandas.read_csv()函数是Pandas库中用于读取CSV(逗号分隔值)文件的函数之一。
本文中洲洲将进行详细介绍pandas.read_csv()函数的使用方法。
一、Pandas库简介
pandas是一个Python包,并且它提供快速,灵活和富有表现力的数据结构。
这样当我们处理"关系"或"标记"的数据(一维和二维数据结构)时既容易又直观。
pandas是我们运用Python进行实际、真实数据分析的基础,同时它是建立在NumPy之上的。
总的来说Pandas是一个开源的数据分析和操作库,用于Python编程语言。它提供了高性能、易用的数据结构和数据分析工具,是数据科学、数据分析、机器学习等众多领域中不可或缺的工具之一。
其主要特点有:
- DataFrame和Series:Pandas的核心是DataFrame和Series两种数据结构。DataFrame是一个二维标签化数据结构,你可以将其想象为一个Excel表格,而Series则是一维的标签化数组。
- 易用性:Pandas提供了大量的方法和功能,使得数据清洗、处理和分析变得简单直观。
- 高性能:Pandas在内部使用Cython或C语言编写,以提高性能,特别是在处理大型数据集时。
- 自动和显式的数据处理:Pandas能够自动处理大量数据,同时允许用户显式地控制数据处理的细节。
- 时间序列分析:Pandas提供了对时间序列数据的丰富支持,包括时间戳的自动处理和时间序列窗口函数。
- 数据聚合:Pandas能够轻松地对数据进行聚合操作,如求和、平均、最大值、最小值等。
- 数据重塑:Pandas提供了灵活的数据重塑功能,包括合并、分割、转换等。
- 数据输入输出:Pandas支持多种数据格式的输入输出,包括CSV、Excel、SQL数据库、JSON等。
常用的功能如下:
- 数据清洗:处理缺失值、数据过滤、数据转换等。
- 数据合并:使用concat、merge等函数合并多个数据集。
- 数据分组:使用groupby进行数据分组并应用聚合函数。
- 数据重塑:使用pivot_table、melt等函数重塑数据。
- 时间序列功能:使用date_range、resample等函数处理时间序列数据。
- 绘图功能:Pandas内置了基于matplotlib的绘图功能,可以快速创建图表。
二、CSV文件
CSV(Comma-Separated Values)文件是一种简单的文件格式,用于存储表格数据,其中每个字段通常由逗号分隔。
CSV文件可以被大多数的电子表格软件和数据库软件以及多种编程语言读取。
2.1 常用参数
- path:文件路径或文件对象。
- sep:字段分隔符,默认为逗号,。
- header:列名行的索引,默认为0。
- index_col:用作行索引的列名。
- usecols:需要读取的列名列表或索引。
- dtype:列的数据类型。
2.2 全部参数
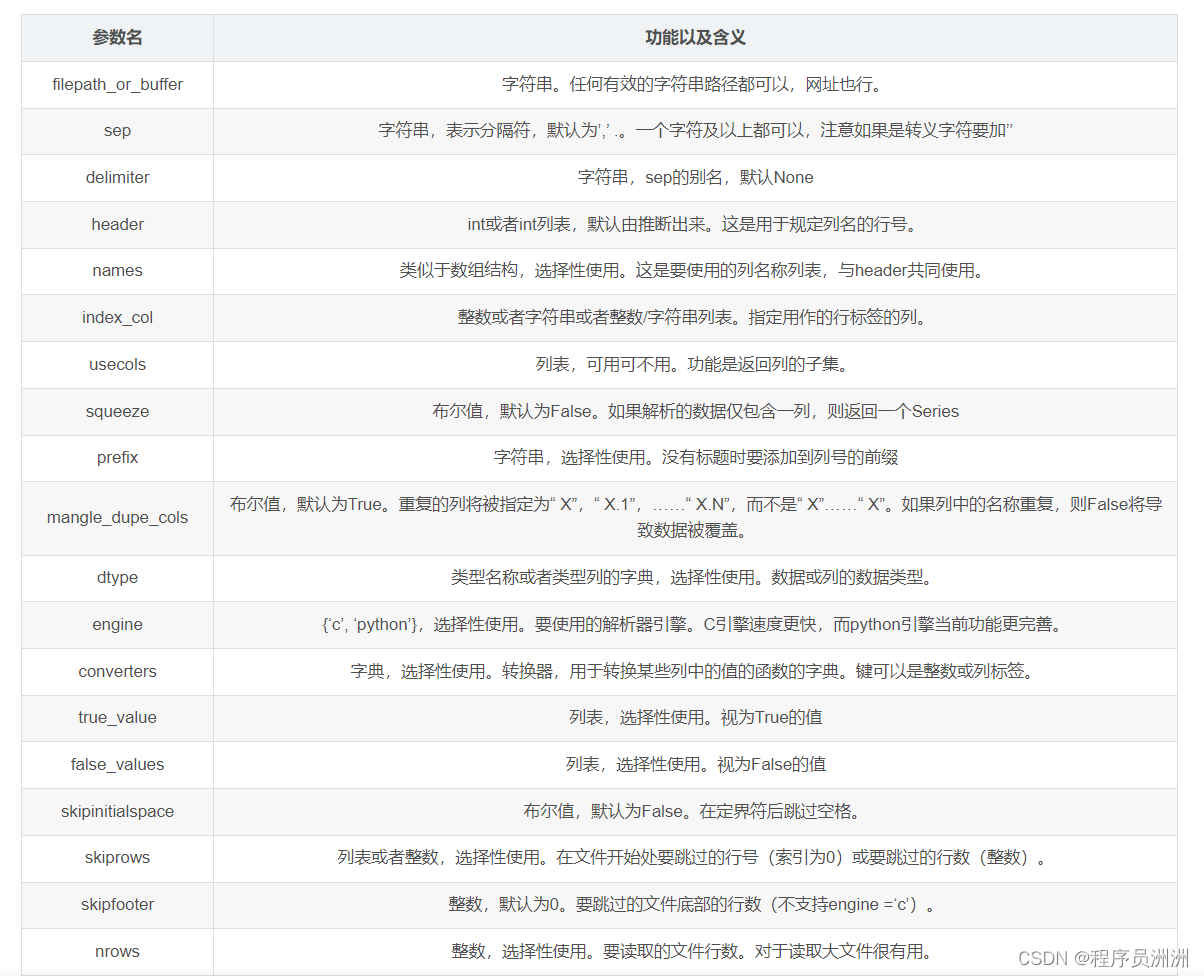
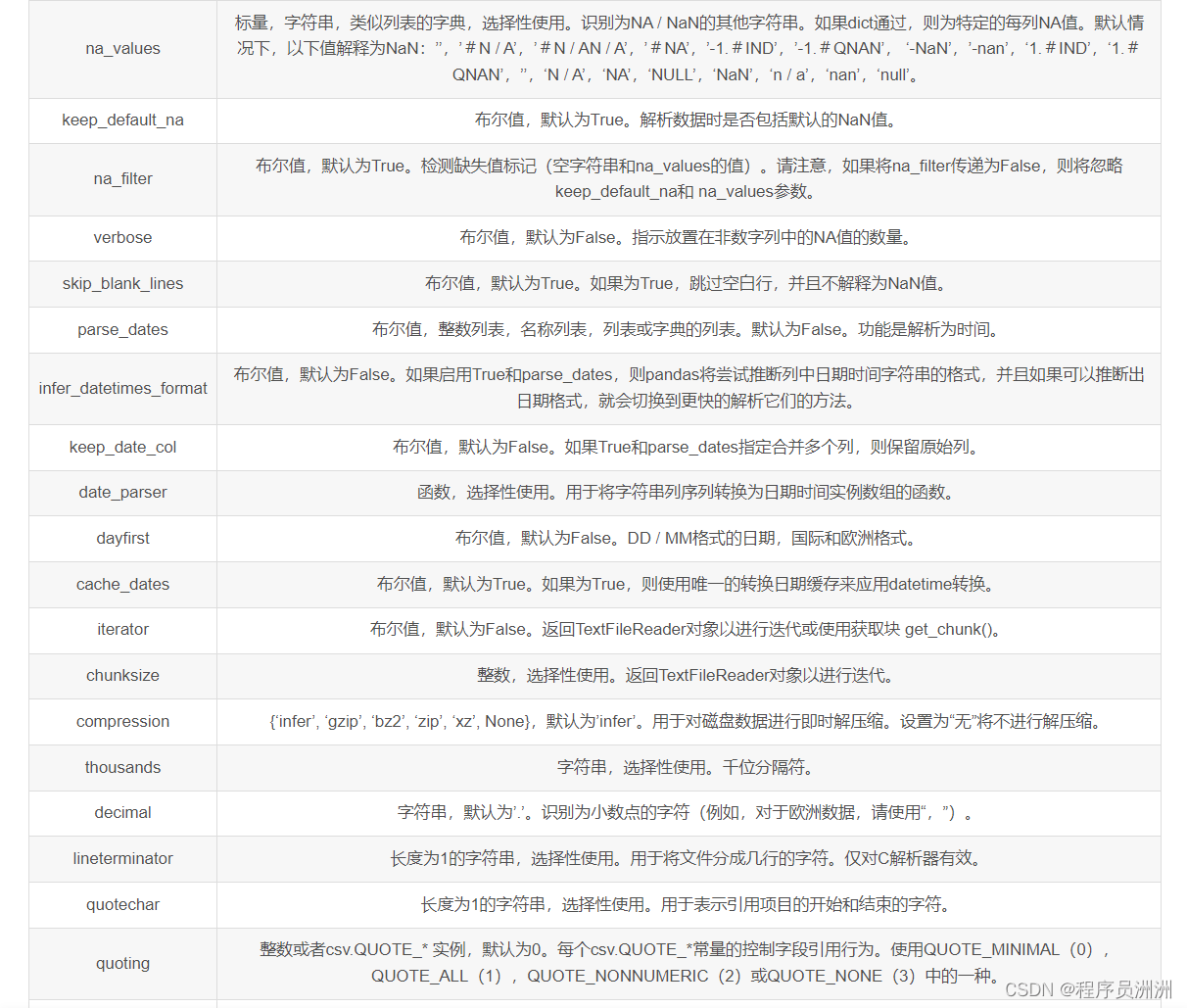

三、实战代码
3.1 自定义分隔符
如果CSV文件使用制表符作为分隔符:
df = pd.read_csv('data.tsv', sep='\t')
3.2 指定列名和数据类型
指定列名和列的数据类型:
df = pd.read_csv('data.csv', names=['Name', 'Age', 'Occupation'], dtype={'Age': int})
忽略列,只读取特定的列:
df = pd.read_csv('data.csv', usecols=['Name', 'Occupation'])
3.3 处理缺失的数据
CSV文件中可能包含缺失数据,pandas.read_csv()提供了参数来处理这种情况:
df = pd.read_csv('data_with_missing.csv', header=None)
df = df.replace('', pd.NA) # 将空字符串替换为NA
df = df.dropna() # 删除包含NA的行
3.4 读取大文件
对于大文件,可以使用chunksize参数分块读取:
chunk_size = 1000 # 每块1000行
chunks = pd.read_csv('large_data.csv', chunksize=chunk_size)
for chunk in chunks:
process(chunk) # 对每块进行处理
四、注意事项
- 文件路径:确保提供正确的文件路径,如果文件不在相同的目录下,需要提供相对或绝对路径。
- 编码问题:如果文件包含特殊字符或非ASCII字符,可能需要指定encoding参数,例如encoding=‘utf-8’。
- 数据类型转换:在读取数据时,Pandas可能无法自动识别数据类型,这时可以通过dtype参数指定。
- 性能考虑:对于非常大的CSV文件,考虑使用分块读取或优化数据处理流程以提高性能。
- 日期时间列:如果CSV文件包含日期时间数据,可以使用parse_dates参数将列解析为Pandas的datetime类型。
到此这篇关于python中pandas.read_csv()函数的实现的文章就介绍到这了,更多相关python pandas.read_csv()内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!