
Python实现快速提取Word表格并转Markdown
作者:Python测试之道
一、为什么需要这个工具
在测试工作中,我们常遇到这样的场景:
- 需求文档是Word格式,但需要将表格数据提取出来生成测试用例
- 手动复制粘贴效率低且易出错
- 大模型需要结构化数据输入,但Word表格格式复杂
本文提供一套零基础可操作的代码方案,帮助测试工程师3分钟内完成表格提取与转换,直接对接自动化测试或大模型。
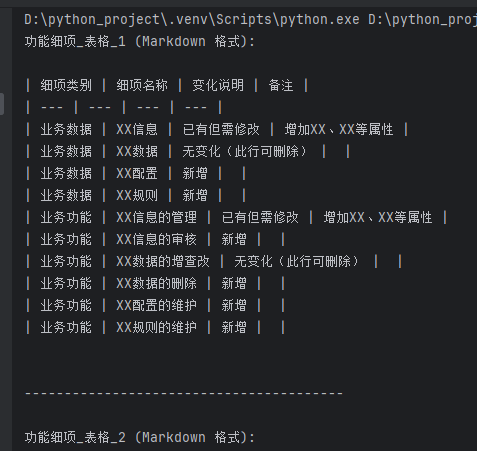
二、代码实战:三步搞定表格提取
第一步:安装依赖
pip install python-docx
注意:
- 如果提示权限问题,可在命令前加 sudo(Linux/macOS)或以管理员身份运行命令行(Windows)。
- 如果文档包含复杂格式(如合并单元格),需确保 python-docx 版本 ≥ 0.8.11。
第二步:核心代码解析
1. 标题检测:精准定位目标段落
def is_heading_enhanced(paragraph):
# 标题特征:样式名称含关键词 + 字体加粗 + 字体足够大
style_name = (paragraph.style.name or "").lower()
if "标题" in style_name or "heading" in style_name:
return True
try:
font = paragraph.style.font
return (font.size.pt >= 14 and font.bold) if font.size else False
except:
return False
关键点详解:
样式名称匹配:
- 优先检查标题样式名称是否包含 标题(中文)或 heading(英文),如 Heading 1、标题1。
- 这一设计能快速定位到文档中明确标记的标题段落。
格式兜底判断:
- 字体大小:标题通常比正文大,这里设置阈值为14pt(可调整)。
- 加粗要求:标题一般需要加粗,确保格式一致性。
- 如果段落样式名称未包含关键词,但满足格式条件,也会被识别为标题。
异常处理:
使用 try-except 捕获字体信息缺失的异常,避免程序崩溃。
2. 表格抓取:按文档顺序提取
def get_tables_under_heading(doc_path, target_title):
from docx import Document
doc = Document(doc_path)
target_tables = []
found = False
for element in doc.element.body.iter():
if element.tag.endswith('p'): # 段落
par = Paragraph(element, doc)
if target_title in par.text and is_heading_enhanced(par):
found = True
elif found and is_heading_enhanced(par): # 遇到新标题停止
break
elif element.tag.endswith('tbl') and found: # 表格
table = Table(element, doc)
data = [[cell.text.strip() for cell in row.cells] for row in table.rows]
target_tables.append(data)
return target_tables
实战技巧详解:
文档元素遍历:
- 通过 doc.element.body.iter() 直接遍历Word文档底层元素,确保段落和表格的顺序与实际文档一致。
- element.tag.endswith('p') 和 element.tag.endswith('tbl') 分别识别段落和表格的XML标签。
双重标记机制:
- found 标记:当找到目标标题后,标记为 True,开始收集后续的表格。
- 新标题终止:一旦遇到新标题(同样满足标题检测条件),立即停止收集,避免误取其他章节的表格。
数据提取:
使用列表推导式逐行提取表格内容,cell.text.strip() 去除单元格中的多余空格。
3. 转换Markdown:结构化输出
def to_markdown(table_data):
if not table_data:
return ""
headers = table_data[0]
md = f"| {' | '.join(headers)} |\n"
md += f"| {' | '.join(['---']*len(headers))} |\n"
for row in table_data[1:]:
md += f"| {' | '.join(row)} |\n"
return md
效果示例:
| 用户角色 | 创建权限 | 删除权限 | 修改权限 |
|----------|----------|----------|----------|
| 管理员 | 是 | 是 | 是 |
| 普通用户 | 否 | 否 | 是 |
细节说明:
表头与分隔符:第一行数据作为表头,用 --- 分隔表头与数据行。
空表格处理:如果输入表格为空,直接返回空字符串,避免错误。
兼容性:适用于大多数表格,但若表格包含合并单元格,需额外处理(见后续优化建议)。
第三步:调用代码(5分钟上手)
def main():
doc_path = "需求文档_v2.0.docx" # 替换为你的文档路径
target_title = "功能权限矩阵" # 替换为目标标题
# 提取表格
tables = get_tables_under_heading(doc_path, target_title)
# 输出Markdown
for idx, table in enumerate(tables, 1):
print(f"--- 表格{idx} ---\n")
print(to_markdown(table))
print("\n-------------------\n")
if __name__ == "__main__":
main()
执行步骤:
- 将代码保存为 extract_tables.py。
- 修改 doc_path 和 target_title 为实际文档路径和标题。
- 运行 python extract_tables.py,即可在控制台看到Markdown格式的表格。
三、常见问题与解决方案
Q1:检测不到标题
可能原因:
- 标题样式名称不符合 标题 或 heading 关键词。
- 标题字体大小或加粗格式未达标。
解决方案:
1.检查标题样式:
- 在Word中右键标题段落 → 选择「段落样式」,确认样式名称是否包含关键词。
- 例如:将样式改为「标题 1」或「Heading 2」。
2.手动调整格式判断:
# 在 is_heading_enhanced 中,降低字体大小要求 return (font.size.pt >= 12 and font.bold) if font.size else False
Q2:表格提取不完整
可能原因:
- 表格与标题不在同一章节,中间有其他标题阻隔。
- 文档中存在多个同名标题,代码只提取第一个。
解决方案:
强制遍历所有表格:
# 移除遇到新标题停止的逻辑 # 删除以下代码: elif found and is_heading_enhanced(par): break
精确匹配标题:
如果标题文本唯一,可直接使用 par.text.strip() == target_title 完全匹配。
Q3:Markdown格式混乱
可能原因:
单元格内容包含换行符或特殊符号。
解决方案:
清理数据:
# 在提取单元格时去除换行符
cell.text.strip().replace('\n', ' ')
手动调整:
将输出结果复制到Markdown编辑器(如Typora),通过可视化界面调整格式。
四、真实场景应用案例
场景1:生成接口测试用例
# 提取"接口参数表"后,直接生成测试用例模板
table_data = get_tables_under_heading("接口文档.docx", "接口参数表")[0]
for row in table_data[1:]:
param, type_, example = row
print(f"测试点:{param}参数为{example}时,接口应返回{type_}类型")
输出示例:
测试点:user_id参数为123时,接口应返回int类型
测试点:username参数为"admin"时,接口应返回str类型
场景2:自动化测试数据生成
# 将表格数据写入CSV文件供测试框架读取
import csv
tables = get_tables_under_heading("测试数据.docx", "登录用例数据")
with open("test_data.csv", "w", newline="") as f:
writer = csv.writer(f)
for table in tables:
writer.writerows(table)
五、代码扩展与优化建议
1. 支持多级标题
def get_tables_under_heading(doc_path, target_title, level=1):
# 新增参数:level表示标题层级(如1级标题)
# 在is_heading_enhanced中增加层级判断
if f"heading{level}" in style_name:
return True
2. 处理合并单元格
def extract_cell(cell):
# 处理合并单元格时的空值
if cell.text.strip():
return cell.text.strip()
else:
return "[合并单元格]"
3. 日志记录与错误提示
import logging
logging.basicConfig(level=logging.INFO)
def main():
try:
tables = get_tables_under_heading(...)
except FileNotFoundError:
logging.error("文档路径错误,请检查文件是否存在!")
六、总结
通过这套方案,你可以:
- 快速定位文档中指定标题的表格
- 自动化输出结构化Markdown数据
- 无缝对接测试用例生成、自动化测试脚本等下游流程
立即尝试:
- 将代码保存为extract_tables.py。
- 替换文档路径和标题。
- 运行代码,查看输出结果。
以上就是Python实现快速提取Word表格并转Markdown的详细内容,更多关于Python提取Word转Markdown的资料请关注脚本之家其它相关文章!