
Python将博客内容html导出为Markdown格式
作者:DriverWon
Python将博客内容html导出为Markdown格式,通过博客url地址抓取文章,分析并提取出文章标题和内容,将内容构建成html,再转换为Markdown文件
一、为什么要搞?
有一部分博客文章需要搬家,逐个手动CV复制粘贴不仅效率低下,还容易出错,而且还面临格式调整的问题。为了简化这一流程,这里尝试使用Python来自动化处理,确保文章内容的准确性和一致性。
二、准备如何搞?
通过博客url地址抓取文章,分析并提取出文章标题和内容,将内容构建成html,再转换为Markdown文件。
在文章新家导入生成的Markdown文件。
三、说搞咱就搞!
抓取文章
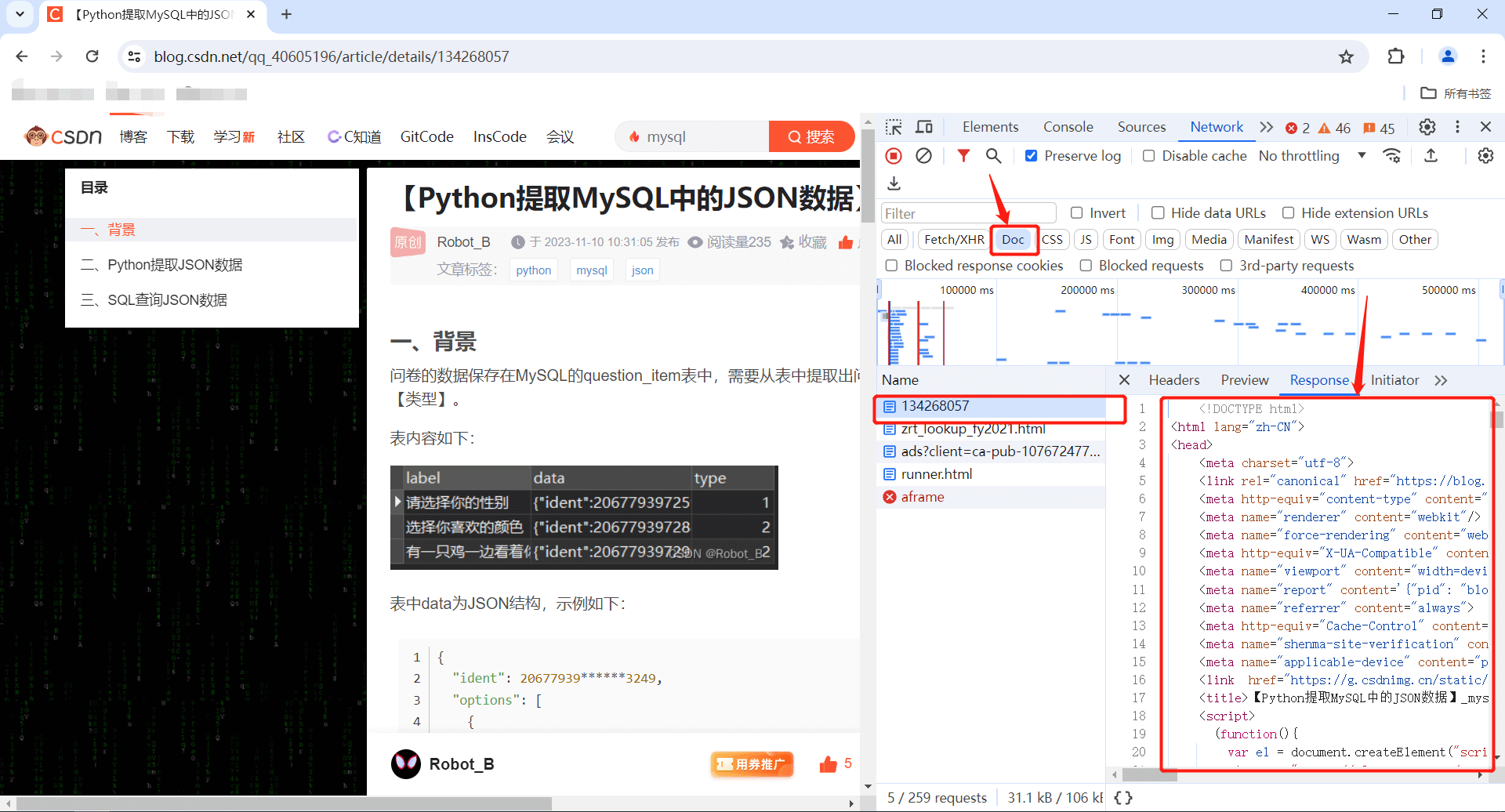
在浏览器中(Google Chrome)输入博客网页地址,并F12打开开发者工具
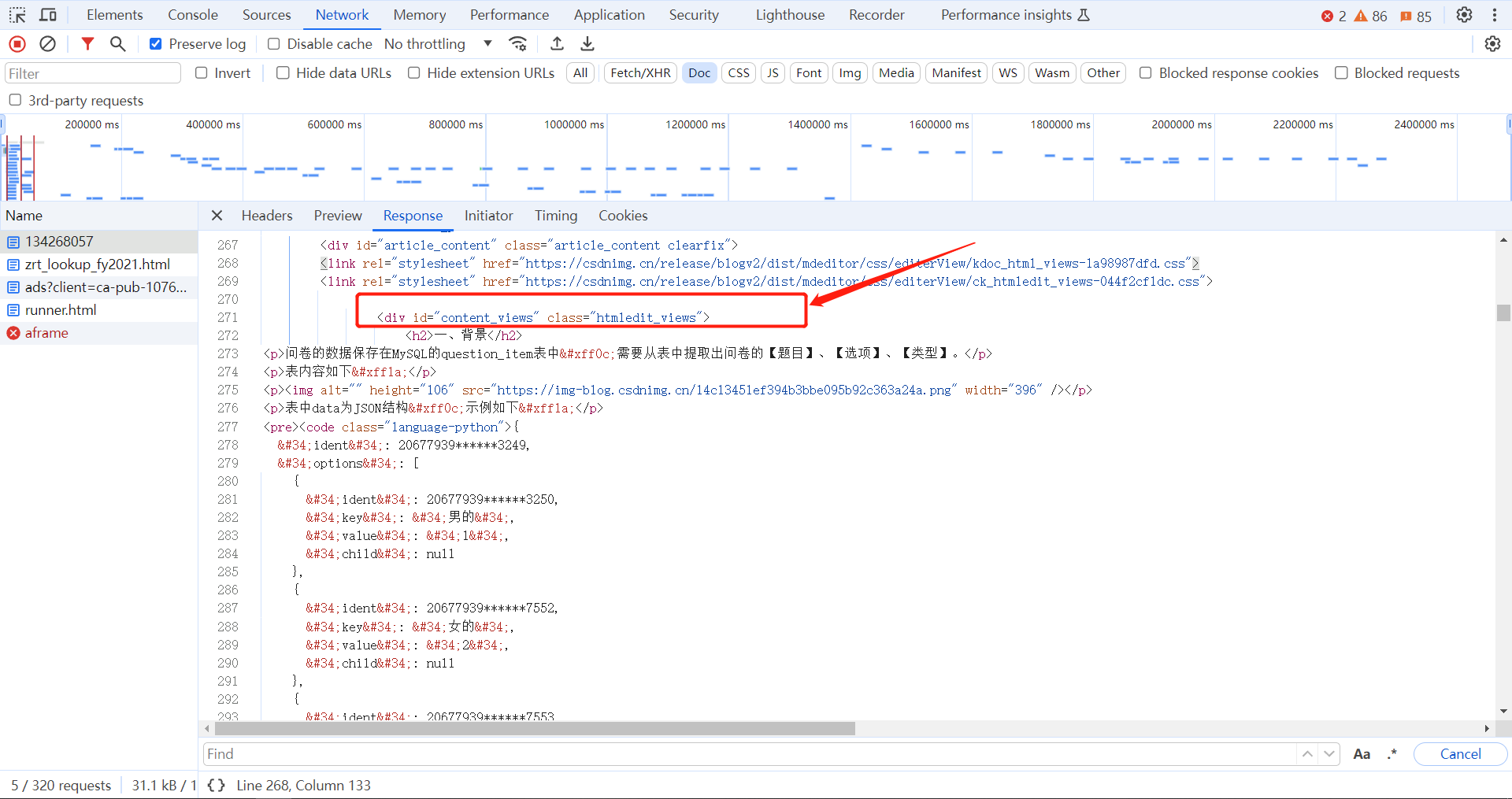
选中Doc,在Response中看到响应结果是html文档
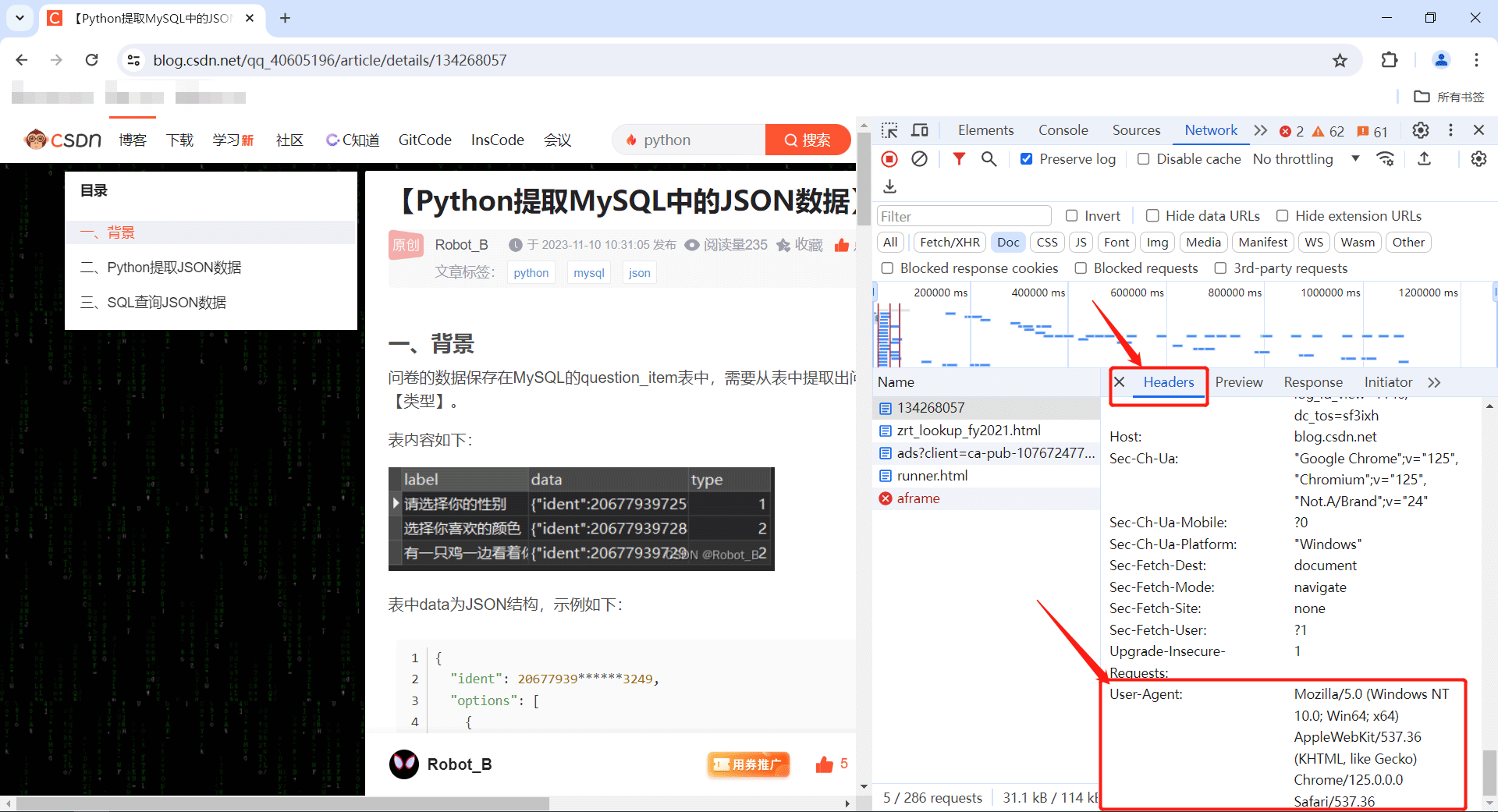
在Headers中复制出User-Agent,以便模拟浏览器的请求
Python代码
requests模拟浏览器抓取文章
import requests
blog_url = 'https://blog.csdn.net/qq_40605196/article/details/134268057'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'}
res = requests.get(url=blog_url, headers=headers)
print(res.text)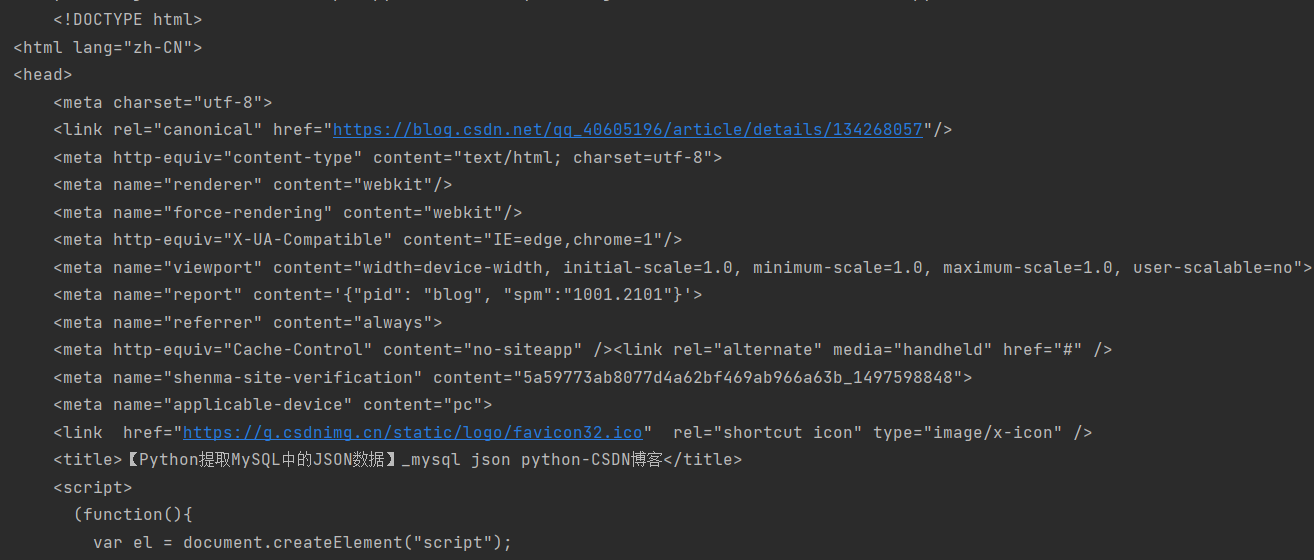
可见Python抓取结果和浏览器中的响应结果一致
提取内容
分析响应结果html
标题在articleContentId中
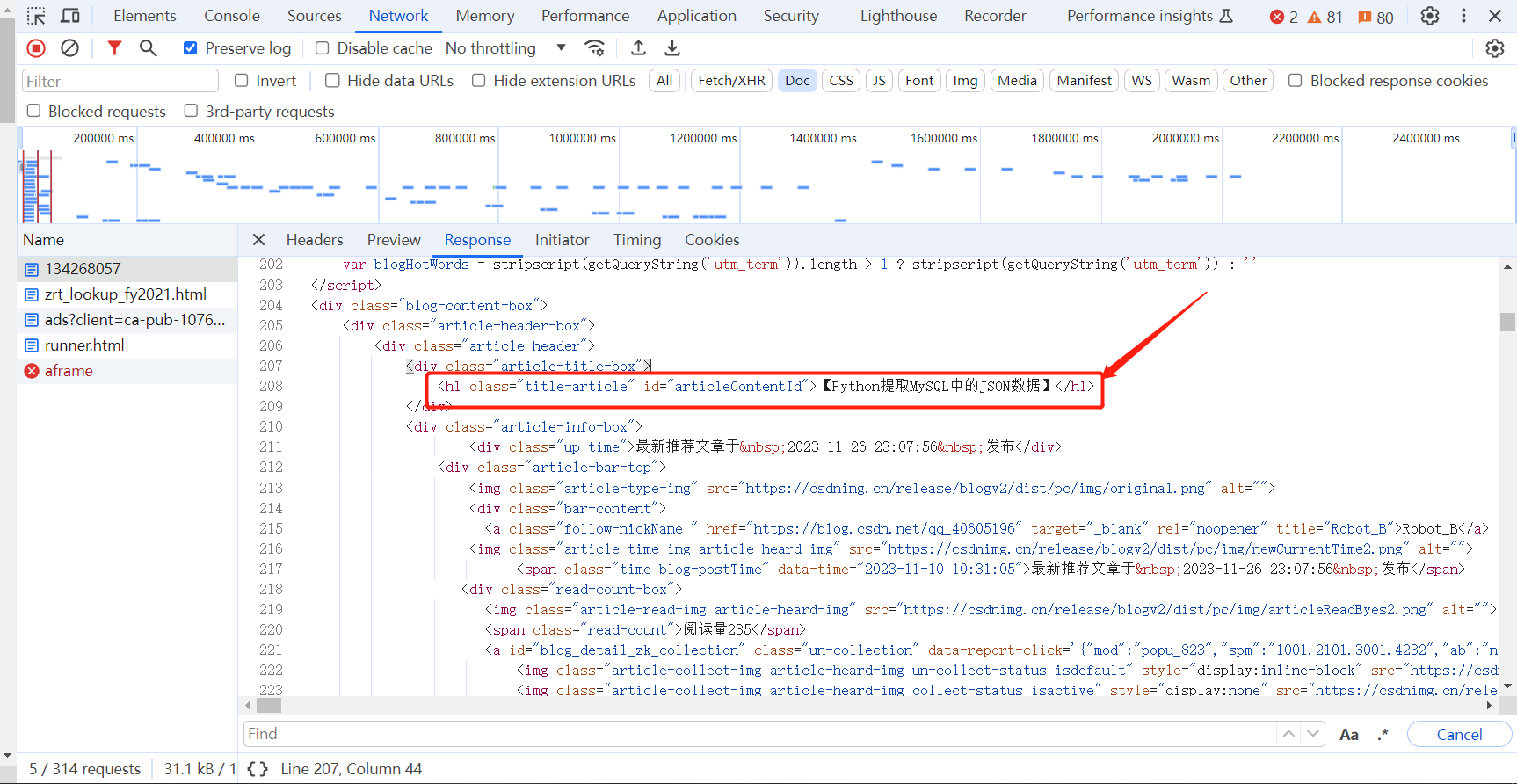
内容在content_views中
Python代码
使用parsel的Selector解析抓取到的文章,css选择器提取标题和内容
import parsel
selector = parsel.Selector(res.text) # 创建Selector解析对象
title = selector.css('#articleContentId::text').get() # CSS选择器提取文章标题
print(title)
print("="*100)
content = selector.css('#content_views').get() # CSS选择器提取文章内容
print(content)
构建html
将提取到的content构建成html
html_content = f"""
<!doctype html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
{content}
</body>
</html>
"""转存markdown
html2text将构建好的html转换为markdown文件
from html2text import html2text
markdown = html2text(html_content) # html转换为markdown
md_path = f'{title}.md'
with open(md_path, 'w+', encoding='utf-8') as f: # 保存为md文件
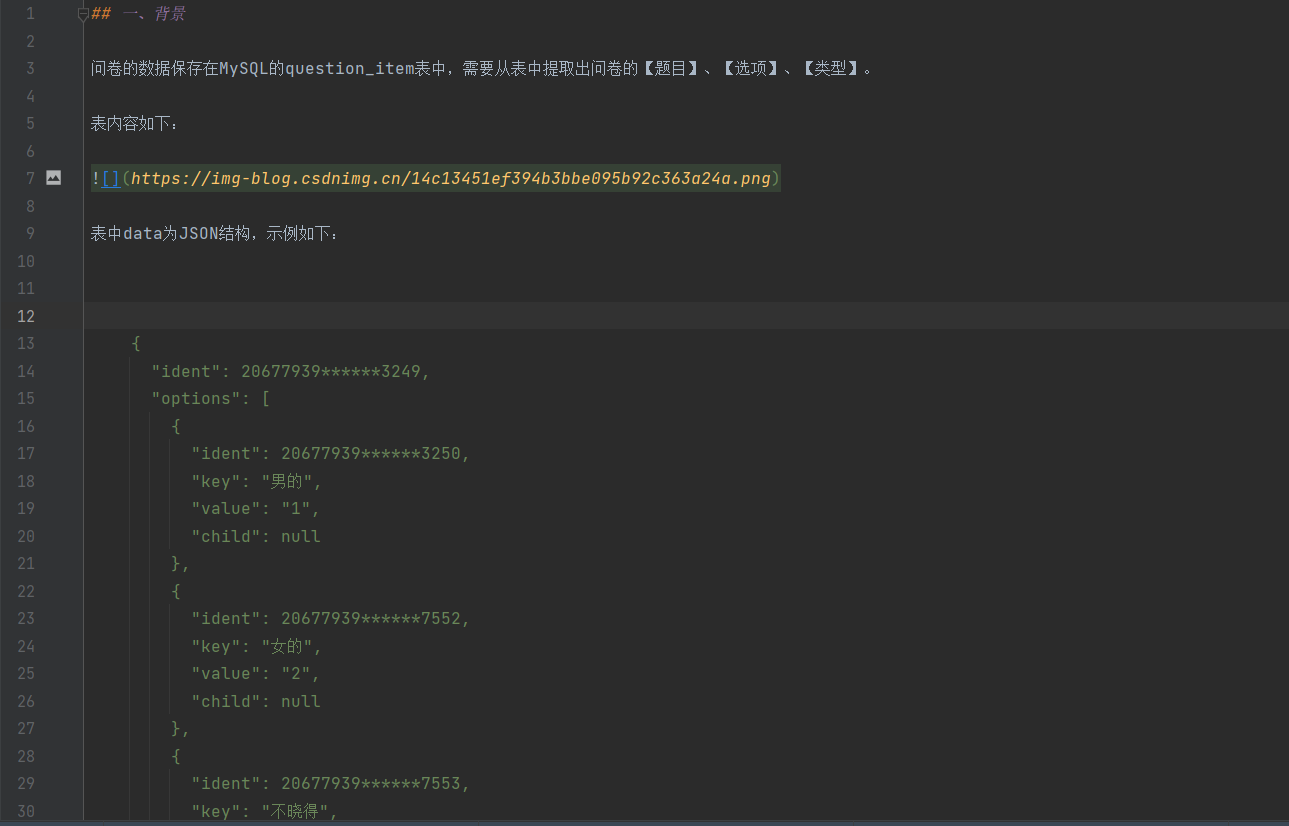
f.write(markdown)markdown文件内容如下图:
搬入新家
在新家中导入保存的.md文件
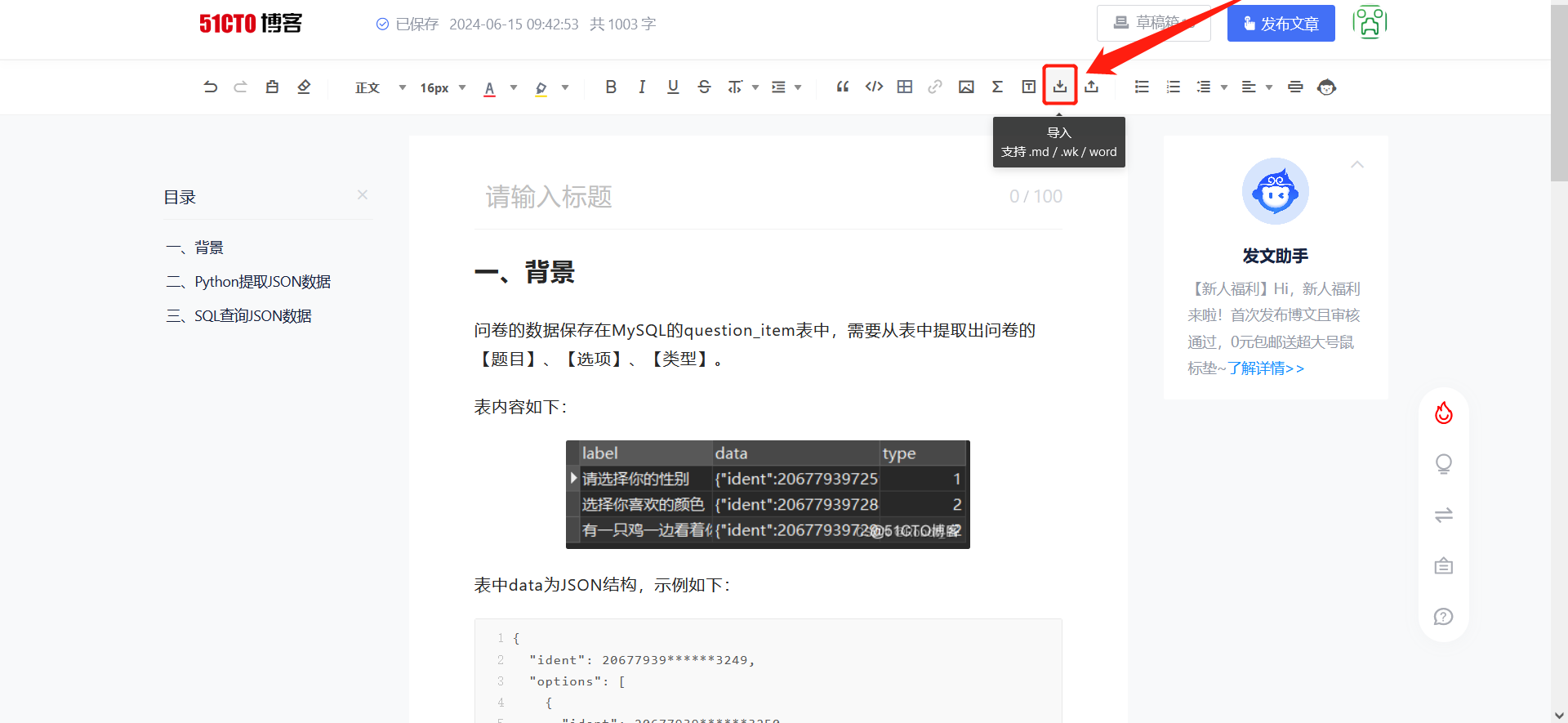
文章中的文字、图片、代码块以及格式都完美搬入新家
到此这篇关于Python将博客内容html导出为Markdown格式的文章就介绍到这了,更多相关Python将html导出为Markdown内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!