
Python实现查找并删除重复文件的方法小结
作者:Bruce_xiaowei
1. 引言
随着计算机存储技术的发展,硬盘容量越来越大,但随之而来的文件管理问题也日益突出。尤其是当多个用户或应用程序在同一系统中工作时,很容易产生大量的重复文件。这些重复文件不仅浪费了宝贵的存储空间,还可能影响系统的性能。因此,定期清理重复文件是非常有必要的。
本文将介绍一种基于Python的解决方案,利用哈希算法(如MD5)来高效地查找并删除重复文件。
2. 环境准备
为了运行本文提供的代码,您需要:
Python 3.x 版本
安装了os和hashlib模块(这两个模块是Python标准库的一部分,无需额外安装)
确保您的环境中已正确安装了Python,并且可以正常导入上述模块。
3. 核心代码解析
3.1 计算文件的MD5哈希值
def file_hash(filepath):
"""计算文件的MD5哈希值"""
hash_md5 = hashlib.md5()
with open(filepath, "rb") as f:
for chunk in iter(lambda: f.read(4096), b""):
hash_md5.update(chunk)
return hash_md5.hexdigest()
该函数接受一个文件路径作为参数,返回其MD5哈希值。它通过逐块读取文件内容(每次读取4096字节),以避免一次性加载整个文件到内存中,从而提高效率并减少内存占用。
3.2 查找并删除重复文件
def find_and_confirm_delete_duplicates(root_dir):
"""在指定目录下查找并确认删除重复文件"""
hashes = {}
duplicates = []
# 遍历指定目录及其所有子目录
for dirpath, _, filenames in os.walk(root_dir):
for filename in filenames:
filepath = os.path.join(dirpath, filename)
try:
file_hash_value = file_hash(filepath)
if file_hash_value in hashes:
duplicates.append(filepath)
else:
hashes[file_hash_value] = filepath
except Exception as e:
print(f"Error processing file {filepath}: {e}")
# 创建Tkinter根窗口
root = tk.Tk()
root.withdraw() # 隐藏主窗口
# 遍历重复文件列表,逐个确认是否删除
for dup in duplicates:
# 显示确认对话框
response = messagebox.askyesno("Confirm Deletion", f"Do you want to delete the duplicate file:\n{dup}")
if response:
try:
os.remove(dup)
print(f"Deleted duplicate file: {dup}")
except Exception as e:
print(f"Error deleting file {dup}: {e}")
else:
print(f"Skipped deletion of duplicate file: {dup}")
root.destroy() # 销毁Tkinter根窗口此函数遍历给定的根目录及其所有子目录,检查每个文件的内容是否与其他文件相同。如果发现相同的文件,则将其添加到duplicates列表中,最后批量删除这些重复文件。
3.3删除确认
引入tkinter和messagebox:用于创建图形用户界面并显示确认对话框。
创建Tkinter根窗口:隐藏主窗口以避免不必要的显示干扰。
确认删除操作:对于每个发现的重复文件,使用messagebox.askyesno()弹出确认对话框。用户点击“是”则删除文件,点击“否”则跳过该文件。
异常处理:增加了对文件读取和删除操作中的异常处理,确保程序不会因单个文件的问题而崩溃。
使用说明:
将上述代码保存为一个Python文件(例如remove_duplicates_with_confirmation.py)。
修改代码中的root_directory变量,使其指向您想要清理的文件夹路径。
在命令行中运行该Python脚本:
python remove_duplicates_with_confirmation.py
通过这种方式,您可以更安全地管理文件,确保每次删除操作都经过用户的确认。
4. 功能详解
4.1 文件哈希值计算
我们选择使用MD5算法来计算文件的哈希值。MD5是一种广泛使用的加密散列函数,能够生成固定长度的字符串,该字符串几乎不可能与任何其他输入产生相同的输出。因此,两个文件具有相同的MD5哈希值意味着它们的内容完全一致。
4.2 遍历目录结构
os.walk()是一个非常有用的函数,它可以递归地遍历指定目录及其所有子目录。对于每个目录,它会返回三个值:当前目录路径、当前目录下的子目录名列表以及当前目录下的文件名列表。这使得我们可以轻松地访问和处理每一个文件。
4.3 删除重复文件
一旦确定了哪些文件是重复的,就可以使用os.remove()函数将它们从文件系统中删除。需要注意的是,在实际应用中应谨慎操作,最好先备份重要数据,或者仅将重复文件移动到另一个位置进行审查。
5. 使用示例
假设您有一个包含许多图片、文档等文件的文件夹,并且怀疑其中存在重复项。可以通过以下步骤使用我们的脚本:
将上述代码保存为一个Python文件(例如remove_duplicates.py)。
修改代码中的root_directory变量,使其指向您想要清理的文件夹路径。
在命令行中运行该Python脚本:
python remove_duplicates.py
6. 源码
# 导入必要的模块
import os
import hashlib
import tkinter as tk
from tkinter import messagebox
def file_hash(filepath):
"""计算文件的MD5哈希值"""
hash_md5 = hashlib.md5()
with open(filepath, "rb") as f:
for chunk in iter(lambda: f.read(4096), b""):
hash_md5.update(chunk)
return hash_md5.hexdigest()
def find_and_confirm_delete_duplicates(root_dir):
"""在指定目录下查找并确认删除重复文件"""
hashes = {}
duplicates = []
# 遍历指定目录及其所有子目录
for dirpath, _, filenames in os.walk(root_dir):
for filename in filenames:
filepath = os.path.join(dirpath, filename)
try:
file_hash_value = file_hash(filepath)
if file_hash_value in hashes:
duplicates.append(filepath)
else:
hashes[file_hash_value] = filepath
except Exception as e:
print(f"Error processing file {filepath}: {e}")
# 创建Tkinter根窗口
root = tk.Tk()
root.withdraw() # 隐藏主窗口
# 遍历重复文件列表,逐个确认是否删除
for dup in duplicates:
# 显示确认对话框
response = messagebox.askyesno("Confirm Deletion", f"Do you want to delete the duplicate file:\n{dup}")
if response:
try:
os.remove(dup)
print(f"Deleted duplicate file: {dup}")
except Exception as e:
print(f"Error deleting file {dup}: {e}")
else:
print(f"Skipped deletion of duplicate file: {dup}")
root.destroy() # 销毁Tkinter根窗口
# 使用示例
if __name__ == "__main__":
# 指定要查找重复文件的根目录路径
root_directory = input("请输入要查找的目录:") # 替换为你的目录路径
# 调用函数查找并确认删除重复文件
find_and_confirm_delete_duplicates(root_directory)
/Users/liuxiaowei/PycharmProjects/AI大模型/.venv/bin/python /Users/liuxiaowei/PycharmProjects/AI大模型/Kimi模型/查找并删除重复文件.py
请输入要查找的目录: /Users/liuxiaowei/Downloads
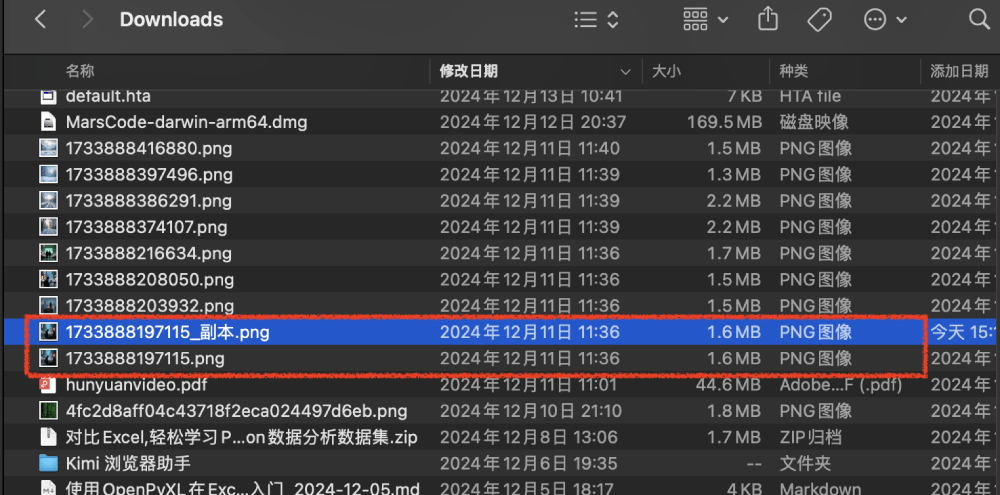

7. 注意事项
数据安全性:在执行删除操作之前,请务必确认确实不需要保留这些文件。建议先备份重要数据,或者只将重复文件移至临时位置进行进一步检查。
性能考虑:对于非常大的文件集,计算哈希值可能会比较耗时。可以根据实际情况调整每次读取的字节数(默认为4096),以优化性能。
跨平台兼容性:虽然本文提供的代码适用于大多数操作系统,但在不同平台上使用时仍需注意路径分隔符等问题。
8. 总结
通过使用Python编写一个简单的脚本,我们可以高效地查找并删除指定目录及其子目录中的重复文件。这种方法不仅节省了磁盘空间,还提高了文件管理的效率。
到此这篇关于Python实现查找并删除重复文件的方法小结的文章就介绍到这了,更多相关Python查找与删除重复文件内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!