
Python实现高精度敏感词过滤
作者:星辰@Sea
这篇文章主要为大家详细介绍了Python中实现高精度敏感词过滤的相关方法,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下
一、需求分析:敏感词过滤的四大核心挑战
- 准确性要求:误判率需低于0.01%
- 性能压力:单机QPS需达到10万+
- 对抗升级:需识别变体、拼音、谐音等
- 合规需求:满足《网络安全法》等法规要求
二、常用算法横向对比
算法性能对比表
| 算法类型 | 时间复杂度 | 内存消耗 | 支持模糊匹配 | 适用场景 |
|---|---|---|---|---|
| 正则表达式 | O(n*m) | 低 | 有限支持 | 简单规则匹配 |
| Trie树 | O(k) | 中 | 不支持 | 精确匹配 |
| AC自动机 | O(n) | 高 | 支持 | 大规模词库 |
| DFA | O(1) | 极高 | 支持 | 超大规模实时检测 |
三、生产级实现方案
方案1:AC自动机(Aho-Corasick)实现
class ACTrie:
def __init__(self):
self.root = {'fail': None, 'children': {}}
def build_fail_pointers(self):
queue = deque()
for child in self.root['children'].values():
child['fail'] = self.root
queue.append(child)
while queue:
node = queue.popleft()
for char, child in node['children'].items():
fail = node['fail']
while fail and char not in fail['children']:
fail = fail['fail']
child['fail'] = fail['children'][char] if fail else self.root
queue.append(child)
def add_keyword(self, keyword):
node = self.root
for char in keyword:
node = node['children'].setdefault(char, {'children': {}, 'is_end': False})
node['is_end'] = True
def filter_text(self, text):
current = self.root
result = []
for i, char in enumerate(text):
while current and char not in current['children']:
current = current['fail']
if not current:
current = self.root
continue
current = current['children'][char]
if current['is_end']:
start = i - len(keyword) + 1
result.append((start, i+1))
return result
方案2:DFA优化版
public class DFASensitiveFilter {
private Map<Object, Object> dfaMap = new HashMap<>();
public void buildDFA(Set<String> sensitiveWords) {
for (String word : sensitiveWords) {
Map nowMap = dfaMap;
for (int i = 0; i < word.length(); i++) {
char keyChar = word.charAt(i);
Map<String, String> subMap = (Map) nowMap.get(keyChar);
if (subMap == null) {
subMap = new HashMap<>();
nowMap.put(keyChar, subMap);
}
nowMap = subMap;
if (i == word.length() - 1) {
nowMap.put("isEnd", "1");
}
}
}
}
public String filter(String text) {
StringBuilder result = new StringBuilder();
for (int i = 0; i < text.length(); i++) {
int length = checkDFA(text, i);
if (length > 0) {
result.append("***");
i += length - 1;
} else {
result.append(text.charAt(i));
}
}
return result.toString();
}
}
四、高级对抗策略
1. 拼音检测实现
from pypinyin import lazy_pinyin
def detect_pinyin(text):
pinyin_text = ''.join(lazy_pinyin(text))
return trie.search(pinyin_text)
2. 相似字符替换表
{
"⓪":"0", "①":"1", "②":"2",
"𝓪":"a", "𝓑":"B", "𝒄":"c",
"𝕯":"D", "è":"e", "ƒ":"f"
}
3. 谐音检测算法
def homophone_replace(word):
mapping = {
'艹': 'cao',
'氵': 'shui',
'扌': 'ti'
}
return ''.join([mapping.get(c, c) for c in word])
五、性能优化方案
优化策略对比表
| 优化手段 | 效果提升 | 实现难度 | 适用场景 |
|---|---|---|---|
| 多级缓存 | 50% QPS提升 | ★★☆☆☆ | 高并发读取 |
| 分布式检测 | 线性扩展能力 | ★★★★☆ | 超大规模系统 |
| SIMD指令优化 | 3倍吞吐量提升 | ★★★★★ | 底层性能优化 |
| 预处理机制 | 降低90%计算量 | ★★☆☆☆ | 长文本处理 |
六、生产环境部署架构
核心组件说明:
- 动态词库管理:支持热更新敏感词库
- 多级缓存:LocalCache + Redis集群
- 降级策略:超时自动切换基础算法
- 监控报警:实时统计检测命中率
七、合规性实践指南
1.日志记录要求:
存储原始内容和检测结果
保留时间不少于6个月
3.审核流程设计:
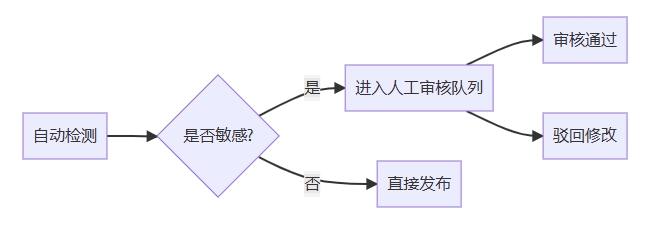
3.法律风险规避:
- 用户协议中明确过滤规则
- 提供申诉渠道
- 定期进行合规审查
八、案例:某社交平台实践
业务需求:
- 日均检测10亿条消息
- 平均响应时间<5ms
- 支持100种语言
技术选型:
- AC自动机 + DFA混合引擎
- Go语言实现核心算法
- Redis集群缓存热点规则
性能指标:
压测结果:
QPS: 238,000
P99延迟: 8ms
内存占用: 12GB(1亿关键词)
九、开源方案推荐
敏感词库:
检测工具:
十、注意事项与常见陷阱
字符编码问题:
- 统一使用UTF-8编码
- 处理全角/半角字符
性能陷阱:
- 避免在循环中创建检测对象
- 注意正则表达式回溯问题
安全防护:
- 词库文件加密存储
- 防止规则注入攻击
权威数据:Gartner报告显示,到2025年70%的内容审核将采用AI辅助方案,但核心过滤算法仍是基石!
到此这篇关于Python实现高精度敏感词过滤的文章就介绍到这了,更多相关Python敏感词过滤内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!