
Pandas JSON的处理使用
作者:游王子og
JSON(JavaScript Object Notation,JavaScript 对象表示法),是存储和交换文本信息的语法,类似 XML。JSON 比 XML 更小、更快,更易解析。Pandas 提供了强大的方法来处理 JSON 格式的数据,支持从 JSON 文件或字符串中读取数据并将其转换为 DataFrame,以及将 DataFrame 转换回 JSON 格式。
| 操作 | 方法 | 说明 |
|---|---|---|
| 从 JSON 文件/字符串读取数据 | pd.read_json() | 从 JSON 数据中读取并加载为 DataFrame |
| 将 DataFrame 转换为 JSON | DataFrame.to_json() | 将 DataFrame 转换为 JSON 格式的数据,可以指定结构化方式 |
| 支持 JSON 结构化方式 | orient 参数 | 支持多种结构化方式,如 split、records、columns |
Pandas 可以很方便的处理 JSON 数据,本文以 sites.json 为例,内容如下:
[
{
"id": "A001",
"name": "bing",
"url": "www.bing.com",
"likes": 61
},
{
"id": "A002",
"name": "Google",
"url": "www.google.com",
"likes": 124
},
{
"id": "A003",
"name": "淘宝",
"url": "www.taobao.com",
"likes": 45
}
]1 从 JSON 文件/字符串加载数据
1.1 pd.read_json() - 读取 JSON 数据
read_json() 用于从 JSON 格式的数据中读取并加载为一个 DataFrame。它支持从 JSON 文件、JSON 字符串或 JSON 网址中加载数据。
df = pd.read_json(
path_or_buffer, # JSON 文件路径、JSON 字符串或 URL
orient=None, # JSON 数据的结构方式,默认是 'columns'
dtype=None, # 强制指定列的数据类型
convert_axes=True, # 是否转换行列索引
convert_dates=True, # 是否将日期解析为日期类型
keep_default_na=True # 是否保留默认的缺失值标记
)| 参数 | 说明 | 默认值 |
|---|---|---|
path_or_buffer | JSON 文件的路径、JSON 字符串或 URL | 必需参数 |
orient | 定义 JSON 数据的格式方式。常见值有 split、records、index、columns、values。 | None(根据文件自动推断) |
dtype | 强制指定列的数据类型 | None |
convert_axes | 是否将轴转换为合适的数据类型 | True |
convert_dates | 是否将日期解析为日期类型 | True |
keep_default_na | 是否保留默认的缺失值标记(如 NaN) | True |
常见的 orient 参数选项:
| orient 值 | JSON 格式示例 | 描述 |
|---|---|---|
split | {"index":["a","b"],"columns":["A","B"],"data":[[1,2],[3,4]]} | 使用键 index、columns 和 data 结构 |
records | [{"A":1,"B":2},{"A":3,"B":4}] | 每个记录是一个字典,表示一行数据 |
index | {"a":{"A":1,"B":2},"b":{"A":3,"B":4}} | 使用索引为键,值为字典的方式 |
columns | {"A":{"a":1,"b":3},"B":{"a":2,"b":4}} | 使用列名为键,值为字典的方式 |
values | [[1,2],[3,4]] | 只返回数据,不包括索引和列名 |
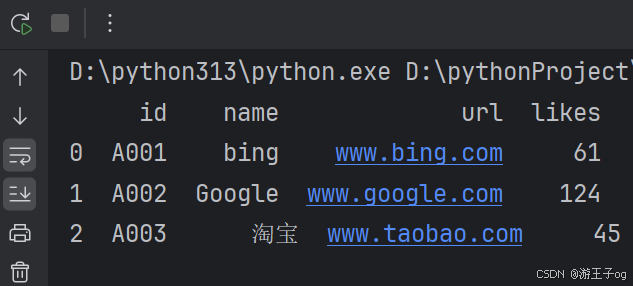
从 JSON 文件加载数据,to_string() 用于返回 DataFrame 类型的数据,我们也可以直接处理 JSON 字符串。
import pandas as pd
df = pd.read_json('sites.json')
print(df.to_string())
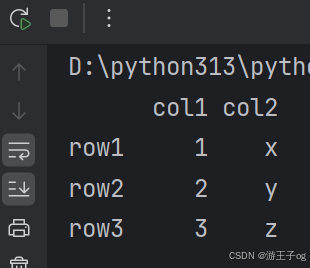
JSON 对象与 Python 字典具有相同的格式,所以我们可以直接将 Python 字典转化为 DataFrame 数据:
import pandas as pd
# 字典格式的 JSON
s = {
"col1": {"row1": 1, "row2": 2, "row3": 3},
"col2": {"row1": "x", "row2": "y", "row3": "z"}
}
# 读取 JSON 转为 DataFrame
df = pd.DataFrame(s)
print(df)
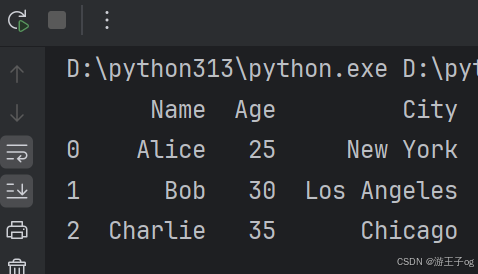
从 JSON 字符串加载数据:
from io import StringIO
import pandas as pd
# JSON 字符串
json_data = '''
[
{"Name": "Alice", "Age": 25, "City": "New York"},
{"Name": "Bob", "Age": 30, "City": "Los Angeles"},
{"Name": "Charlie", "Age": 35, "City": "Chicago"}
]
'''
# 从 JSON 字符串读取数据
df = pd.read_json(StringIO(json_data))
print(df)
1.2 内嵌的 JSON 数据
假设有一组内嵌的 JSON 数据文件 nested_list.json :
{
"school_name": "ABC primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}]
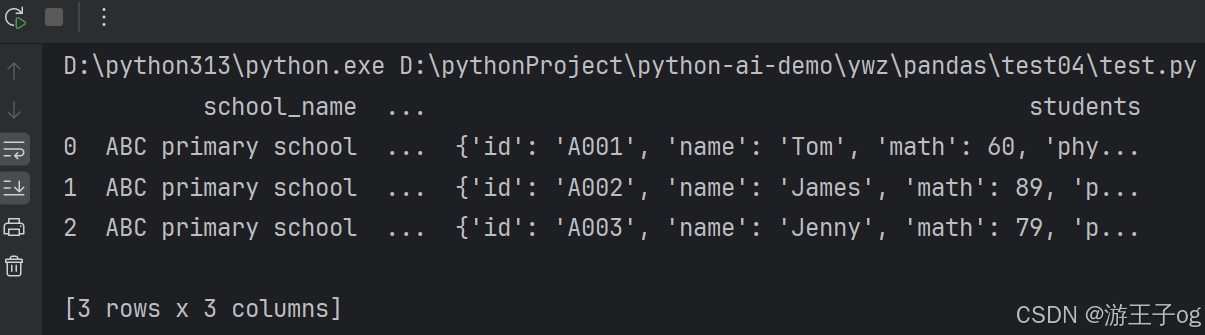
}使用以下代码格式化完整内容:
import pandas as pd
df = pd.read_json('nested_list.json')
print(df)
这时我们就需要使用到 json_normalize() 方法将内嵌的数据完整的解析出来:
import pandas as pd
import json
# 使用 Python JSON 模块载入数据
with open('nested_list.json', 'r') as f:
data = json.loads(f.read())
# 展平数据
df_nested_list = pd.json_normalize(data, record_path=['students'])
print(df_nested_list)
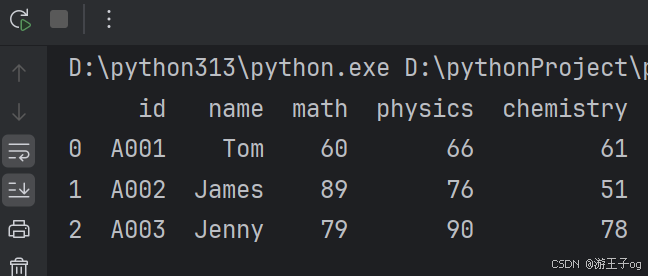
data = json.loads(f.read()) 使用 Python JSON 模块载入数据。json_normalize() 使用了参数 record_path 并设置为 ['students'] 用于展开内嵌的 JSON 数据 students。显示结果还没有包含 school_name 和 class 元素,如果需要展示出来可以使用 meta 参数来显示这些元数据:
import pandas as pd
import json
# 使用 Python JSON 模块载入数据
with open('nested_list.json', 'r') as f:
data = json.loads(f.read())
# 展平数据
df_nested_list = pd.json_normalize(
data,
record_path=['students'],
meta=['school_name', 'class']
)
print(df_nested_list)
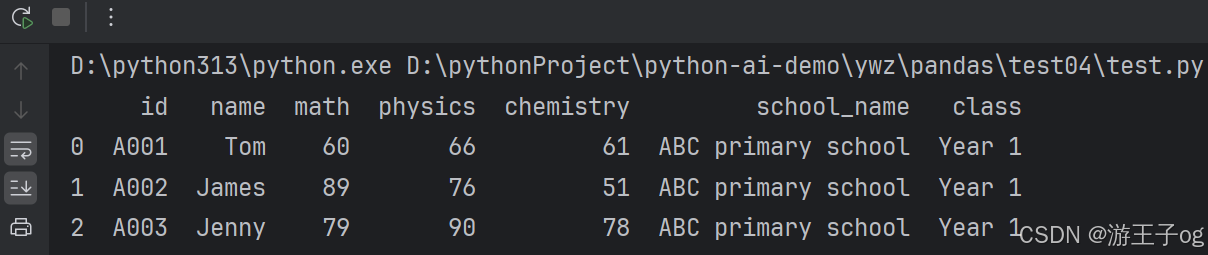
接下来尝试读取更复杂的 JSON 数据,该数据嵌套了列表和字典,数据文件 nested_mix.json 如下:
{
"school_name": "local primary school",
"class": "Year 1",
"info": {
"president": "John Kasich",
"address": "ABC road, London, UK",
"contacts": {
"email": "admin@e.com",
"tel": "123456789"
}
},
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}
]
}nested_mix.json 文件转换为 DataFrame:
import pandas as pd
import json
# 使用 Python JSON 模块载入数据
with open('nested_mix.json', 'r') as f:
data = json.loads(f.read())
df = pd.json_normalize(
data,
record_path=['students'],
meta=[
'class',
['info', 'president'],
['info', 'contacts', 'tel']
]
)
print(df)
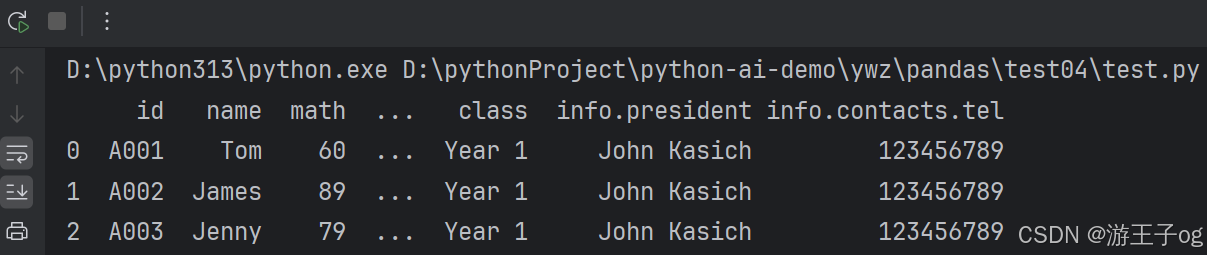
1.3 读取内嵌数据中的一组数据
以下是实例文件 nested_deep.json,我们只读取内嵌中的 math 字段:
{
"school_name": "local primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"grade": {
"math": 60,
"physics": 66,
"chemistry": 61
}
},
{
"id": "A002",
"name": "James",
"grade": {
"math": 89,
"physics": 76,
"chemistry": 51
}
},
{
"id": "A003",
"name": "Jenny",
"grade": {
"math": 79,
"physics": 90,
"chemistry": 78
}
}
]
}这里我们需要使用到 glom 模块来处理数据套嵌,glom 模块允许我们使用 . 来访问内嵌对象的属性。第一次使用我们需要安装 glom:
pip3 install glom
import pandas as pd
from glom import glom
df = pd.read_json('nested_deep.json')
data = df['students'].apply(lambda row: glom(row, 'grade.math'))
print(data)
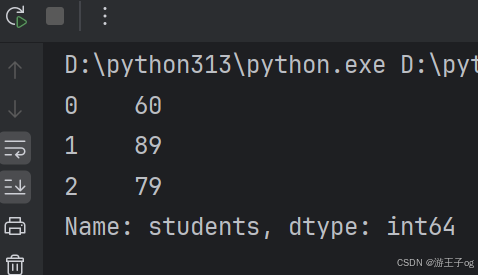
2 将 DataFrame 转换为 JSON
2.1 DataFrame.to_json() - 将 DataFrame 转换为 JSON 数据
to_json() 方法用于将 DataFrame 转换为 JSON 格式的数据,可以指定 JSON 的结构化方式。语法格式:
df.to_json(
path_or_buffer=None, # 输出的文件路径或文件对象,如果是 None 则返回 JSON 字符串
orient=None, # JSON 格式方式,支持 'split', 'records', 'index', 'columns', 'values'
date_format=None, # 日期格式,支持 'epoch', 'iso'
default_handler=None, # 自定义非标准类型的处理函数
lines=False, # 是否将每行数据作为一行(适用于 'records' 或 'split')
encoding='utf-8' # 编码格式
)| 参数 | 说明 | 默认值 |
|---|---|---|
path_or_buffer | 输出的文件路径或文件对象,若为 None,则返回 JSON 字符串 | None |
orient | 指定 JSON 格式结构,支持 split、records、index、columns、values | None(默认是 columns) |
date_format | 日期格式,支持 'epoch' 或 'iso' 格式 | None |
default_handler | 自定义处理非标准类型(如 datetime 等)的处理函数 | None |
lines | 是否将每行数据作为一行输出(适用于 records 或 split) | False |
encoding | 输出文件的编码格式 | 'utf-8' |
import pandas as pd
# 创建 DataFrame
df = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Los Angeles', 'Chicago']
})
# 将 DataFrame 转换为 JSON 字符串
json_str = df.to_json()
print(json_str)

将 DataFrame 转换为 JSON 文件(指定 orient='records'):
import pandas as pd
# 创建 DataFrame
df = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Los Angeles', 'Chicago']
})
# 将 DataFrame 转换为 JSON 文件,指定 orient='records'
df.to_json('data.json', orient='records', lines=True)
将 DataFrame 转换为 JSON 并指定日期格式:
import pandas as pd
# 创建 DataFrame,包含日期数据
df = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie'],
'Date': pd.to_datetime(['2021-01-01', '2022-02-01', '2023-03-01']),
'Age': [25, 30, 35]
})
# 将 DataFrame 转换为 JSON,并指定日期格式为 'iso'
json_str = df.to_json(date_format='iso')
print(json_str)

到此这篇关于Pandas JSON的处理使用的文章就介绍到这了,更多相关Pandas JSON内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!