
Python实现批量下载excel表中超链接图片
作者:可能是条咸鱼吧
背景
导出数据到excel,excel数据中有图片链接,在excel中没法直接看到图片是什么样的,需要批量下载图片的指定文件夹,再进行查看,想到了用python生成一个脚本文件做批量操作,试着写一下。
数据格式
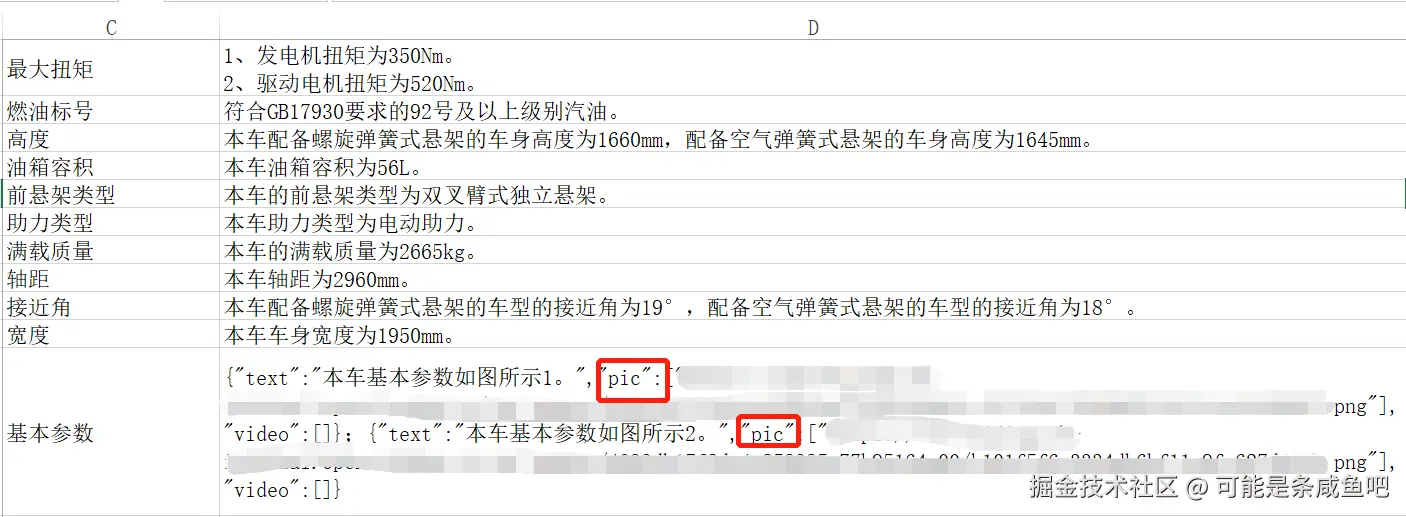
数据类型有文本,也有带图片链接的Json,存在多张图片的情况,需要做的是批量获取Json格式数据中的pic,并进行下载
处理步骤
- 使用xlrd库读取Excel表格的数据
- 获取Excel中的sheet,默认取第一个sheet
- 遍历sheet中的每一行数据,判断是文本还是Json格式数据
- 根据对应的列,获取Json中的pic链接地址,存到对应的list中
- 使用requests库,取出list中的图片地址进行下载
- 确保文件夹存在,如果不存在则创建
1.xlrd库简介
xlrd读取excel表格数据,支持xls和xlsx格式的excel表格
基本函数
1.xlrd.open_workbook(filename[, logfile, file_contents, ...]) 打开excel文件
- filename:需操作的文件名(包括文件路径和文件名称);
- 若filename不存在,则报错FileNotFoundError;
- 若filename存在,则返回值为xlrd.book.Book对象
2.BookObject.sheet_names() 获取Book对象中所有sheet名称,以列表方式显示
3.BookObject.sheets():获取所有sheet的对象,以列表形式显示 BookObject.sheet_by_index(sheetx):通过sheet索引获取所需sheet对象
- sheetx为索引值,索引从0开始计算;
- 若sheetx超出索引范围,则报错IndexError;
- 若sheetx在索引范围内,则返回值为xlrd.sheet.Sheet对象
4.BookObject.sheet_by_name(sheet_name):通过sheet名称获取所需sheet对象 - sheet_name为sheet名称;- 若sheet_name不存在,则报错xlrd.biffh.XLRDError;- 若sheet_name存在,则返回值为xlrd.sheet.Sheet对象
5.对Sheet对象中的行操作
- SheetObject.nrows:获取某sheet中的有效行数
- SheetObject.row_values(rowx[, start_colx=0, end_colx=None]):获取sheet中第rowx+1行从start_colx列到end_colx列的数据,返回值为列表。
- 若rowx在索引范围内,以列表形式返回数据;
- 若rowx不在索引范围内,则报错IndexError
- SheetObject.row(rowx):获取sheet中第rowx+1行单元,返回值为列表;
- 列表每个值内容为: 单元类型:单元数据
- SheetObject.row_slice(rowx[, start_colx=0, end_colx=None]):以切片方式获取sheet中第rowx+1行从start_colx列到end_colx列的单元,返回值为列表;
- 列表每个值内容为: 单元类型:单元数据
- SheetObject.row_types(rowx[, start_colx=0, end_colx=None]):获取sheet中第rowx+1行从start_colx列到end_colx列的单元类型,返回值为array.array类型。
- 单元类型ctype:empty为0,string为1,number为2,date为3,boolean为4, error为5(左边为类型,右边为类型对应的值);
- SheetObject.row_len(rowx):获取sheet中第rowx+1行的长度
- rowx:行标,行数从0开始计算(0表示第一行), 必填参数;
- start_colx:起始列,表示从start_colx列开始取值,包括第start_colx的值;
- end_colx:结束列,表示到end_colx列结束取值,不包括第end_colx的值;
- start_colx默认为0,end_colx默认为None:表示取整行相关数据;
- SheetObject.get_rows():获取某一sheet所有行的生成器
6.对Sheet对象中的列操作
- SheetObject.ncols:获取某sheet中的有效列数
- SheetObject.col_values(self, colx[, start_rowx=0, end_rowx=None]):获取sheet中第colx+1列从start_rowx行到end_rowx行的数据,返回值为列表。
- SheetObject.col_slice(colx[, start_rowx=0, end_rowx=None]):以切片方式获取sheet中第colx+1列从start_rowx行到end_rowx行的数据,返回值为列表。
- 列表每个值内容为: 单元类型:单元数据
- SheetObject.col_types(colx[, start_rowx=0, end_rowx=None]):获取sheet中第colx+1列从start_rowx行到end_rowx行的单元类型,返回值为列表;
7.对Sheet对象的单元格执行操作
- ShellObeject.cell(rowx, colx):获取sheet对象中第rowx+1行,第colx+1列的单元对象,返回值为'xlrd.sheet.Cell'类型,返回值的格式为“单元类型:单元值”。
- ShellObject.cell_value(rowx, colx):获取sheet对象中第rowx+1行,第colx+1列的单元数据,返回值为当前值的类型(如float、int、string...);
- ShellObject.cell_type(rowx, colx):获取sheet对象中第rowx+1行,第colx+1列的单元数据类型值;
- 单元类型ctype:empty为0,string为1,number为2,date为3,boolean为4, error为5;
在Python编译器中安装xlrd
pip install xlrd
注:高版本的xlrd目前去除了xlsx格式的支持,支持xls格式,目前使用有两种方式: 1.删除高版本,重装xlrd
xlrd.biffh.XLRDError: Excel xlsx file; not supported pip install xlrd==1.2.0
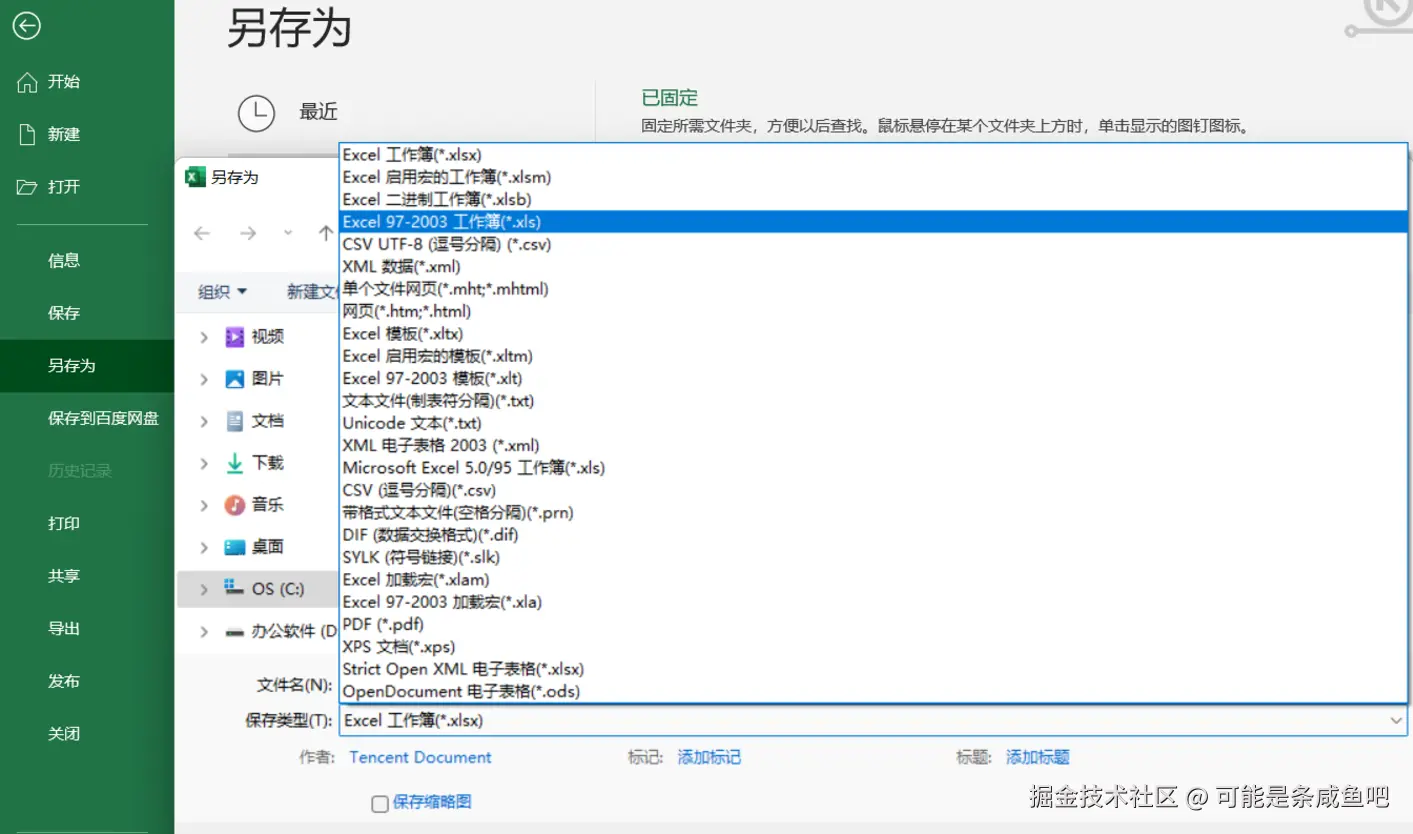
2.打开xlsx文件,另存为xls格式
2.详细代码
引入相关库
import xlrd import requests import json
实例代码
读取excel
read_path = r"xx\xx.xls" # excel文件路径 bk = xlrd.open_workbook(read_path)
获取所有sheet,取第1个sheet页,如果有多个sheet也可以使用sheet_by_name()方法
try:
sh = bk.sheets()[0]
except:
print("no sheet in %s" % read_path)
获取表中的总行数
def is_json(msg):
if isinstance(msg, str): # 判断是否是字符串
try:
json.loads(msg)
except ValueError:
return False
return True
else:
return False
由于数据存在文本和json格式数据,需要先进行判断 判断是否是json格式数据
def is_json(msg):
if isinstance(msg, str): # 判断是否是字符串
try:
json.loads(msg)
except ValueError:
return False
return True
else:
return False
表中第一行有标题,需要从第2行开始
for i in range(1, nrows):
# print("下载第 %d 个图片" % i)
picList = [] # 定义存放图片的list
# 读取C列数据
C_name = sh.cell_value(i, 2)
print('C_name: ', C_name)
# 读取D列数据 excel表中存在一行有多个图片情况,使用“;”对数据进行分隔,分别拿到每一个json格式数据
D_name = sh.cell_value(i, 3).split(";")
print('D_name: ', D_name)
# 循环获取所有的json
for d_value in D_name:
print('d_value:', d_value)
if is_json(d_value):# 先对json进行判断
picList = json.loads(d_value)['pic'] # 如果是json数据就直接取pic里的值
if len(picList): # 为空不打印
print("picList:", picList)
# 循环取出图片地址 使用enumerate获取每个图片下标
for j, picUrl in enumerate(picList):
# 根据URL下载到本地
f = requests.get(picUrl)
# 需要先创建文件夹
pic_name = r"D:\xxx\Downloads\文件夹\\" + C_name + "_" + str(j + 1) + ".png" # 构造完整文件路径+名称
with open(pic_name, "wb") as code:
code.write(f.content)
写在最后
通过这种方式可以将excel表中的超链接图片批量下载到本地,再使用电脑图片查看功能直接看到excel数据中的图片。一个小功能,不一定能满足更多的使用场景,还要努力学习
以上就是Python实现批量下载excel表中超链接图片的详细内容,更多关于Python下载excel超链接图片的资料请关注脚本之家其它相关文章!