
Python爬虫爬取王者荣耀英雄信息并保存到图数据库的操作方法
作者:叁拾舞
本文介绍了如何使用Python爬虫技术从王者荣耀官方获取英雄信息,并将数据保存到图数据库中,文章详细说明了爬取英雄名称、类型及皮肤名称的过程,并展示了创建英雄类型节点和英雄信息节点的方法
爬取信息说明
- 英雄名称
- 英雄类型
- 英雄包含的所有皮肤名称
创建英雄类型节点
王者荣耀官方给出的英雄类型是以下几种:

直接准备好英雄类型词典
hero_type_dict = [
'战士', '法师', '坦克', '刺客', '射手', '辅助'
]添加到图数据库中
def create_hero_type_node():
for hero_type in hero_type_dict:
cypher = "MERGE (n:HeroType{label: '" + hero_type + "'})"
graph.run(cypher).data()
print('创建英雄类型节点成功')创建英雄信息节点
获取英雄信息
def get_hero_info_list():
# 英雄的全部信息的url
hero_info = 'https://pvp.qq.com/web201605/js/herolist.json'
# 获取英雄的全部信息
response = requests.get(hero_info)
# 转为字典格式
hero_info_dict = json.loads(response.text)
return hero_info_dict打印的内容如下:
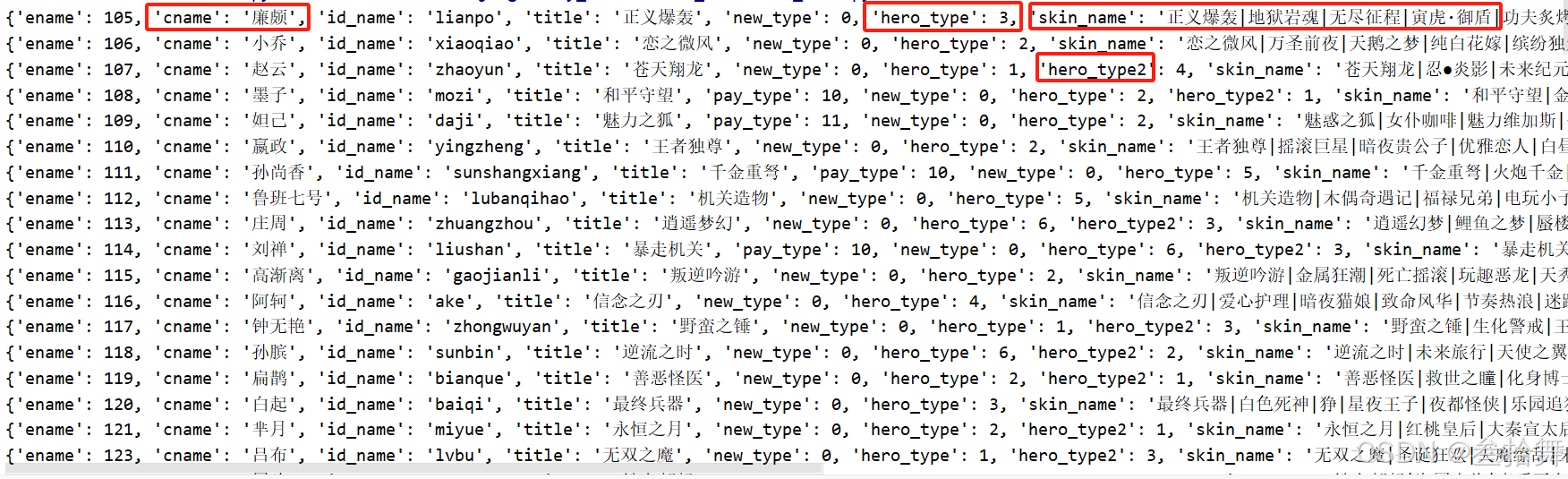
这里需要注意的是,部分英雄包含两个英雄类别。
保存英雄信息
def create_hero_node():
hero_info_dict = get_hero_info_list()
# 1战士 2法师 3坦克 4刺客 5射手 6辅助
for hero in hero_info_dict:
# print(hero)
# print(str(hero.get('cname')) + '===' + str(hero_type[hero.get('hero_type')-1]) + '===' + str(hero.get('skin_name')))
hero_type_list = [str(hero_type_dict[hero.get('hero_type') - 1])]
if '|' in str(hero.get('skin_name')):
skin_name_list = hero.get('skin_name').split('|')
else:
skin_name_list = [hero.get('skin_name')]
if 'hero_type2' in str(hero):
hero_type_list.append(str(hero_type_dict[hero.get('hero_type2') - 1]))
# 创建英雄信息节点
hero_cypher = "MERGE (n:Hero{label: '" + str(hero.get('cname')) + "'})"
graph.run(hero_cypher).data()
# 创建英雄->类型关系
for hero_type in hero_type_list:
cypher_rel = "MATCH(h:Hero{label:'" + str(
hero.get('cname')) + "'}),(t:HeroType{label:'" + hero_type + "'}) MERGE (h)-[r:类型]->(t) RETURN h,r,t"
graph.run(cypher_rel).data()
for skin_name in skin_name_list:
# 创建英雄皮肤节点
cypher = "MERGE (n:Skin{label:'" + skin_name + "'})"
graph.run(cypher).data()
# 创建英雄->皮肤关系
cypher_rel = "MATCH(h:Hero{label:'" + str(
hero.get('cname')) + "'}),(s:Skin{label:'" + skin_name + "'}) MERGE (h)-[r:皮肤]->(s) RETURN h,r,s"
graph.run(cypher_rel).data()
print(str(hero.get('cname')) + '===' + str(hero_type_list) + '===' + str(skin_name_list))完整代码
import json
import requests
from bs4 import BeautifulSoup
from py2neo import Graph, RelationshipMatcher, NodeMatcher
from dict import hero_type_dict
url = "bolt://localhost:7687"
username = "neo4j"
password = 'Suns3535'
graph = Graph(url, auth=(username, password), name="wzry")
node_matcher = NodeMatcher(graph=graph)
relationship_matcher = RelationshipMatcher(graph=graph)
def get_hero_info_list():
# 英雄的全部信息的url
hero_info = 'https://pvp.qq.com/web201605/js/herolist.json'
# 获取英雄的全部信息
response = requests.get(hero_info)
# 转为字典格式
hero_info_dict = json.loads(response.text)
return hero_info_dict
def create_hero_type_node():
for hero_type in hero_type_dict:
cypher = "MERGE (n:HeroType{label: '" + hero_type + "'})"
graph.run(cypher).data()
print('创建英雄类型节点成功')
def create_hero_node():
hero_info_dict = get_hero_info_list()
# 1战士 2法师 3坦克 4刺客 5射手 6辅助
for hero in hero_info_dict:
# print(hero)
# print(str(hero.get('cname')) + '===' + str(hero_type[hero.get('hero_type')-1]) + '===' + str(hero.get('skin_name')))
hero_type_list = [str(hero_type_dict[hero.get('hero_type') - 1])]
if '|' in str(hero.get('skin_name')):
skin_name_list = hero.get('skin_name').split('|')
else:
skin_name_list = [hero.get('skin_name')]
if 'hero_type2' in str(hero):
hero_type_list.append(str(hero_type_dict[hero.get('hero_type2') - 1]))
# 创建英雄信息节点
hero_cypher = "MERGE (n:Hero{label: '" + str(hero.get('cname')) + "'})"
graph.run(hero_cypher).data()
# 创建英雄->类型关系
for hero_type in hero_type_list:
cypher_rel = "MATCH(h:Hero{label:'" + str(
hero.get('cname')) + "'}),(t:HeroType{label:'" + hero_type + "'}) MERGE (h)-[r:类型]->(t) RETURN h,r,t"
graph.run(cypher_rel).data()
for skin_name in skin_name_list:
# 创建英雄皮肤节点
cypher = "MERGE (n:Skin{label:'" + skin_name + "'})"
graph.run(cypher).data()
# 创建英雄->皮肤关系
cypher_rel = "MATCH(h:Hero{label:'" + str(
hero.get('cname')) + "'}),(s:Skin{label:'" + skin_name + "'}) MERGE (h)-[r:皮肤]->(s) RETURN h,r,s"
graph.run(cypher_rel).data()
print(str(hero.get('cname')) + '===' + str(hero_type_list) + '===' + str(skin_name_list))
# 创建英雄类型节点
create_hero_type_node()
# 创建英雄信息
create_hero_node()实现效果
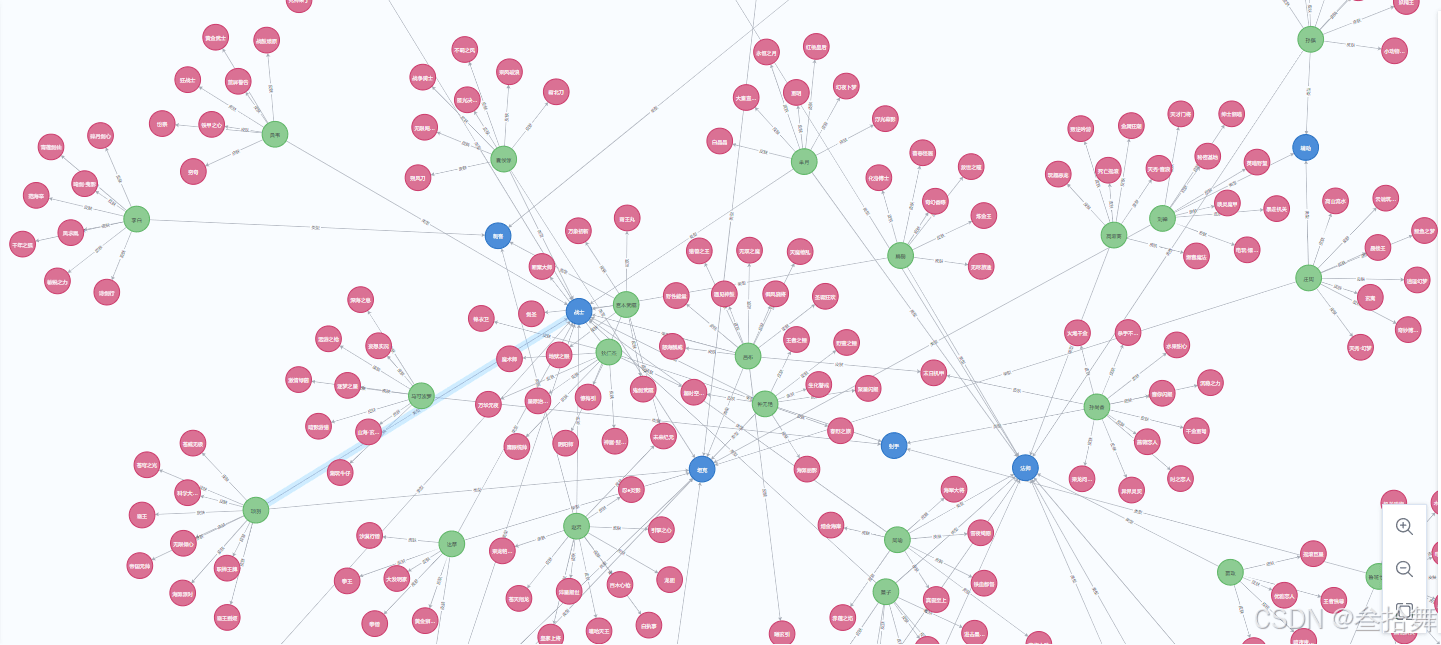
到此这篇关于Python爬虫爬取王者荣耀英雄信息并保存到图数据库的文章就介绍到这了,更多相关Python爬取王者荣耀英雄信息内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!