
Google colab中从kaggle中接入数据的操作方法
作者:Yooooung_Lee
写在前面
使用google colab进行数据分析和探索时,可引用的数据源包括但不限于:1.可上传的数据文件用本地加载的的方式打开数据资源;2.从网络链接中直接打开后加载到缓存中的文件资源;3.通过API或者外部的开放接口加载数据;
今天要介绍的就是第三种,我试图教会你如何从colab中直接从kaggle加载数据集。理论上这种方法适用于所有的云端jupyter笔记本。实施过程中如果遇到预期之外的问题,欢迎留言交流讨论。
本文涉及到两大平台内容,所以我默认你已经拥有了,并且使用过了一段时间的google账号和kaggle账号。首先介绍一下google的colab,相比于其他国内外平台,它对于免费账号也分配足够可用的GPU和TPU资源。而且升级到pro版本后,更可以借助copilot的AI补全代码功能,减少开发压力。
Google Colab 是一项托管 Jupyter Notebook 服务,无需设置即可使用,并提供对计算资源(包括 GPU 和 TPU)的免费访问。 Colab 特别适合机器学习、数据科学和教育。
对于在云端笔记本中使用kaggle数据,完全可以通过先将kaggle数据下载至本地,再将数据上传到服务器的方式解决。但本文旨在摆脱这种冗长的处理办法,试图一步到位,而对于无法实现本教程中操作办法的同学们,还是建议一切以能用为主,简化流程乃是第二位的。
kaggle 部分
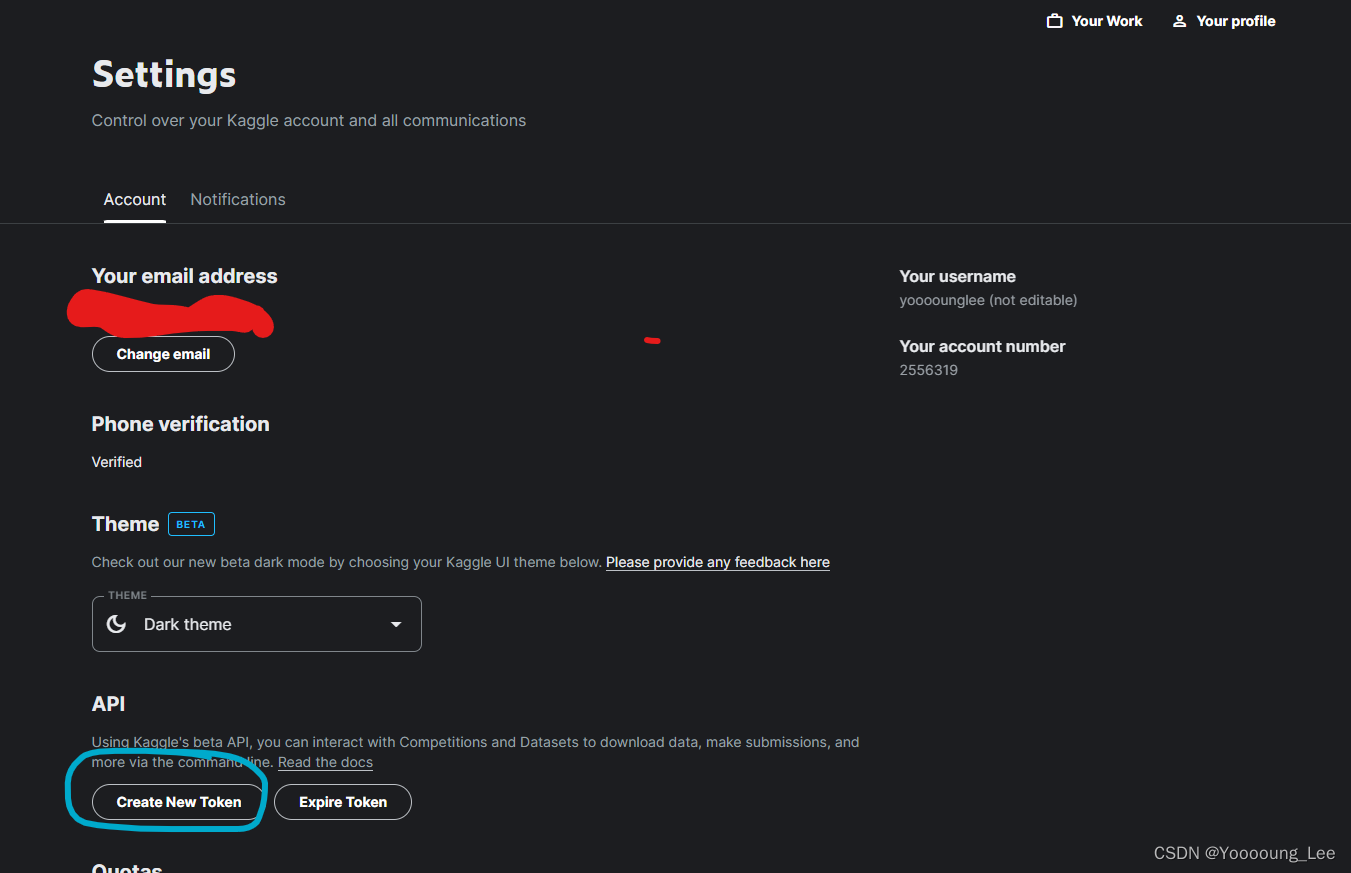
- 点击你的头像,选择Settings
- 下拉至 API,创建一个用于google colab使用的token,点击create new Token后,会自动开始下载一个kaggle.json的配置文件,记住它的存储位置,稍后我们会用到。
Google Colab部分
1.将kaggle.json文件上传至Google Drive
你新建的jupyter笔记本也会默认保存在Drive的某个位置,与其他的google应用一起共享Drive的免费空间。将kaggle.json文件通过 “上传” 功能传至Google Drive,记住它的位置,之后要用。
如果是其他的在线jupyter内容,请上传至对应云端服务器上存储jupyter笔记本位置的同一文件夹内。(其实不用放到一起,只是为了便于你方便找到和操作)
上传完毕之后,在jupyter执行如下命令,查看对应的存储位置,如果当前的位置和你的jupyter位置不对应,那么就在下面给你预留的代码里改一下路径:
import os
# 当前工作目录
print("当前工作目录:", os.getcwd())
# 改变工作目录到新的文件夹
os.chdir("/content/drive/MyDrive/Colab Notebooks") ## 这里替换成kaggle.json存储的所在目录
# 现在的工作目录
print("新的工作目录:", os.getcwd())当前工作目录: /content/drive/My Drive
新的工作目录: /content/drive/MyDrive/Colab Notebooks
确保输出结果正确即可。
2.打通Google Colab与Google Drive之间的连接(其他平台请略过这一步)
Google Drive即谷歌云盘,是谷歌生态下的公共存储空间。它本身支持多种格式文件的存储,以各种格式存储的文件,又能以不同的Google云端应用在线打开并执行操作。Colab作为.ipynb格式文件的编辑器,只要在colab中打通与Google Drive的连接,就能直接访问其中的内容。
操作很简单,只需要点击这个图标,就能够允许这个jupyter笔记本关联drive,受限于网络和网盘内的文件数量,反应时长存在差异,所以只需要参考最终图标的状态是图中这个样子,就是关联成功的状态了。

然后,加载云盘存储,使用以下代码挂载Google Drive:
# 挂载Google Drive: 如果文件确实存在于Google Drive中,
# 确保正确挂载了Google Drive到Colab。使用以下代码挂载Google Drive:
from google.colab import drive
drive.mount('/content/drive')3.获取colab对kaggle.json的访问权限
‘/content/drive/MyDrive/Colab Notebooks/kaggle.json’ 是你kaggle.json存储的位置。还记得我建议你尽可能和jupyter笔记本放在一起吗?只需要把相同的路径填入就可以。而且也不需要在执行下方的复制操作。
如果放在了其他位置也不要紧,执行以下的全部代码,会复制一份kaggle.json到你当前的工作目录里,这个工作目录是你第一步设置的位置。
# 复制文件到正确的位置: 复制 kaggle.json 文件到了
# 使用以下代码检查文件是否成功复制到了正确的位置:
import shutil
shutil.copy("/content/drive/MyDrive/Colab Notebooks/kaggle.json", "/kaggle.json")
# 获取对kaggle文件的访问权限
permissions = oct(os.stat("/root/.kaggle/kaggle.json").st_mode)[-3:]
print("文件权限:", permissions)Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount(“/content/drive”, force_remount=True).
文件权限: 600
当访问权限返回代码码值为600时,表示结果正常。已经获得了权限。
4.从Kaggle下载数据集到Drive内
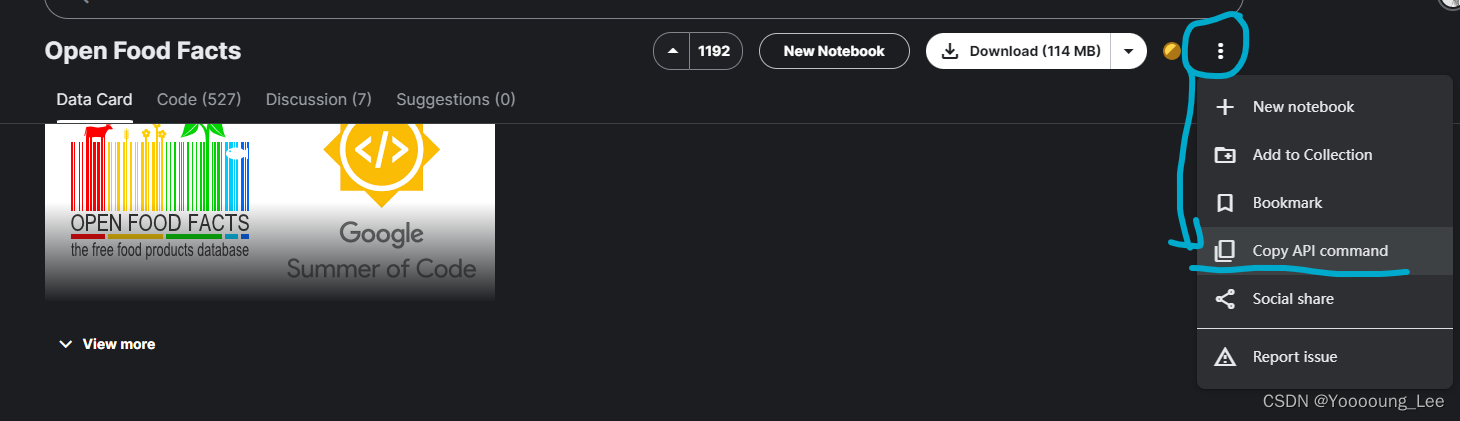
这段代码来自于kaggle的dataset界面,我这里举个例子,如果想要获取这个数据集,那么就可以在这里点击‘copy API command’,他的内容是:
kaggle datasets download -d openfoodfacts/world-food-facts
随后在jupyter内执行以下代码
# 下载原始数据到本地云盘内 ! kaggle datasets download -d openfoodfacts/world-food-facts -p /content/sample_data
对参数的解释,
-d openfoodfacts/world-food-facts 表示数据集名称:world-food-facts 创建人名称:openfoodfacts
-p /content/sample_data 指定数据集文件下载到Google Drive的对应位置
5.如果下载的是压缩包格式…
import zipfile
# 切换到存储文件对应的文件夹
os.chdir("/content/sample_data")
# 要解压的文件名
zip_file = "world-food-facts.zip"
# 新建的文件夹名称
extract_folder = "world-food-facts"
# 创建新的文件夹
os.makedirs(extract_folder, exist_ok=True)
# 解压文件到新建的文件夹中
with zipfile.ZipFile(zip_file, 'r') as zip_ref:
zip_ref.extractall(extract_folder)
print("文件已解压到:", os.path.abspath(extract_folder))
# 重新切换回工作环境内
os.chdir("/content/drive/MyDrive/Colab Notebooks")准备完毕
ok。开始你的表演吧,接下来的操作你应该就全会了,
import pandas as pd
food = pd.read_csv('/content/sample_data/world-food-facts/en.openfoodfacts.org.products.tsv', sep='\t')<ipython-input-40-3044500f6262>:2: DtypeWarning: Columns (0,3,5,19,20,24,25,26,27,28,36,37,38,39,48) have mixed types. Specify dtype option on import or set low_memory=False.
food = pd.read_csv(‘/content/sample_data/world-food-facts/en.openfoodfacts.org.products.tsv’, sep=‘\t’)
food.head()

是不是熟悉的感觉。开始操作吧!
到此这篇关于Google colab中如何从kaggle中接入数据的文章就介绍到这了,更多相关Google colab kaggle数据内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!