
Pytorch使用卷积神经网络对CIFAR10图片进行分类方式
作者:Vic·Tory
神经网络
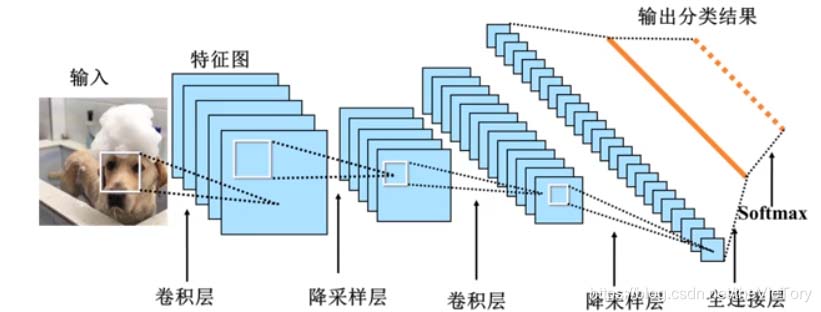
如下所示为一个基本的卷积神经网络的模型,将图像输入之后经过卷积操作提取特征,再经过降采样操作后输出到下一层。
经过多次多个卷积、池化层之后结果输出到全连接层,经过全连接映射到最终结果。
一个神经网络的典型训练过程可以分为如下几步:
- 定义神经网络,包含一些可学习参数(或者叫权重)
- 将数据输入网络进行训练,并计算损失值
- 将梯度反向传播给网络的参数,据此更新网络的权重,并再次训练
定义网络
如下所示为我们定义的神经网络类NeuralNet。
首先它继承自父类nn.Module,从import可以看到从torch中分别引入了torch.nn和torch.functional,其中nn用于保存常用的神经网络类,而functional库中则是一些网络操作。nn.Module类有两个子类必须重写的方法,初始化方法__init__用于定义网络结构,forward()中定义网络训练操作,当网络对象被调用时会自动执行该方法。
在构造函数__init__中我们定义网络的结构,这里定义了网络的两个卷积层为torch.nn库中的二维卷积函数Conv2d(),nn.Conv2d(1, 6, (5, 5))代表输入数据的通道数为1,输出通道数为6,卷积核为5×5,卷积核长和宽一致的话可以简写为5。用nn.Linear实现全连接操作,输入数据长度为16 * 5 * 5,这是由于之前conv2输出的16通道的5×5的数据,输出长度120的数据。经过三个全连接层输出长度为10
在forward()方法中实现网络的训练过程,将输入数据input_x经过conv1的卷积操作后经过激活函数relu,最后经过池化操作max_pool2d得到第一个卷积层的输出layer1,同样操作后得到第二个卷积层layer2。
将卷积的结果通过flat_features()降维,经过第二个卷积层layer2为四维数据[1, 16, 5, 5],通过tensor.size()[1:]选择第一个维度以后的维度相乘得到features为1655=400,通过tensor.view(-1,400)将其转化为长度400的二维数据。最后经过三个全连接层后输出。
import torch
from torch import nn
from torch.nn import functional as Func
class NeuralNet(nn.Module):
def __init__(self):
super(NeuralNet, self).__init__()
# 两个卷积层
self.conv1 = nn.Conv2d(1, 6, (5, 5))
self.conv2 = nn.Conv2d(6, 16, 5)
# 三个全连接层
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, input_x):
# 进行两次卷积、池化操作
layer1 = Func.max_pool2d(Func.relu(self.conv1(input_x)), (2, 2))
layer2 = Func.max_pool2d(Func.relu(self.conv2(layer1)), (2, 2))
# 降维
flat = self.flat_features(layer2)
# 经过三个全连接层
fc1 = Func.relu(self.fc1(flat))
fc2 = Func.relu(self.fc2(fc1))
fc3 = self.fc3(fc2)
return fc3
def flat_features(self, tensor):
features = 1
for size in tensor.size()[1:]:
features *= size
flat = tensor.view(-1, features)
return flat
# 创建一个neural_net对象并打印
neural_net = NeuralNet()
print(neural_net)
'''
NeuralNet(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
'''
训练网络
如下所示为将数据送入网络训练并计算损失值的过程。
首先通过torch.randn()生成四维的随机数据,由于我们之前定义网络中Conv2d()函数接收的数据要求是四维的,其中第一维度代表样本数据的个数,第二维代表数据的通道数,第3、4维代表数据大小,这里是32×32的网格。然后将生成的数据送入neural_net(),这里会自动调用该对象的forward()方法进行模型训练并输出结果。
得到输出结果y_output之后通过和目标值进行比较即可得出损失值,这里仍然使用randn创建目标值y_target,注意目标值要和输出值维度相同,我们输入的样本数量为1,最后经全连接层fc3产生的结果长度为10,所以y_output维度为(1, 10),因此y_target也是二维1×10的数据。
定义评价函数criterion为nn.MSELoss(),即计算输出和目标的均方误差(mean-squared error)。
x = torch.randn(1, 1, 32, 32) # 随机产生输入数据 y_output = neural_net(x) # 输入数据并进行训练 y_target = torch.randn(1, 10) # 随机产生目标数据 criterion = nn.MSELoss() # 定义评价函数 loss = criterion(y_output, y_target) # 计算损失值
反向传播
由之前定义的网络可知我们的从输入到输出,数据经过的函数操作如下,
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d
-> view -> linear -> relu -> linear -> relu -> linear
-> MSELoss
-> loss
通过tensor的grad_fn属性记录了这些函数操作,例如从loss向前回退查看grad_fn
print(loss.grad_fn) # MSELoss print(loss.grad_fn.next_functions[0][0]) # Linear print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU
我们进行反向传播操作,然后就可以查看各层网络参数的梯度
neural_net.zero_grad() # 清零所有参数(parameter)的梯度缓存 loss.backward() # 反向传播 print(neural_net.conv1.bias.grad) # 查看梯度 # tensor([-0.0046, -0.0087, 0.0390, 0.0045, -0.0096, 0.0028])
根据得到的梯度对网络的参数进行更新,例如这里使用随机梯度下降法进行更新,其公式为weight = weight - learning_rate * gradient,即在原有权重的基础上,根据学习率learning_rate减少一定梯度。
如下所示遍历网络的所有参数neural_net.parameters并对其进行更新
learning_rate = 0.01
for param in neural_net.parameters():
param.data.sub_(param.grad.data * learning_rate)
然而在使用神经网络时,我们可能希望使用各种不同的更新规则,如SGD、Nesterov-SGD、Adam、RMSProp等。
在torch.optim库实现了所有的这些方法,如下所示,首先创建优化器optimizer,然后进行多次迭代训练
import torch.optim as optim
# 创建优化器(optimizer)
optimizer = optim.SGD(neural_net.parameters(), lr=0.01)
# 在训练的迭代中:
for epoch in range(100):
optimizer.zero_grad() # 清零梯度缓存
output = neural_net(x)
loss = criterion(y_output, y_target)
loss.backward()
optimizer.step() # 自动更新参数
CIFAR10图片识别
卷积神经网络一个常用的领域就是图片分类,而图片分类中最经典的就是对CIFAR10图片数据集进行分类。
它是一个包含“飞机”,“汽车”,“鸟”,“猫”,“鹿”,“狗”,“青蛙”,“马”,“船”,“卡车”10中类别的图片库。
在CIFAR-10里面的图片数据大小是3x32x32,即:三通道彩色图像,图像大小是32x32像素。
准备数据
pytorch的torchvision提供了CIFAR10库,通过torchvision.datasets.CIFAR10加载该数据集。root为数据集的路径,如果该路径下没有数据,则会从指定站点下载并保存到该路径,train属性标志是训练集还是测试集数据。transform指定了对数据进行的预处理操作。
例如这里将两个预处理操作通过Compose放在了transform中,第一步ToTensor将数据转化为张量,第二步通过Normalize()将数据化为正态分布值。
前面的(0.5,0.5,0.5)是 R G B 三个通道上的均值,后面(0.5, 0.5, 0.5)是三个通道的标准差,Normalize对每个通道执行以下操作:image =(图像-平均值)/ std。当mean,std都是0.5时将使图像在[-1,1]范围内归一化。
例如,最小值0将转换(0-0.5)/0.5=-1
接着使用DataLoader将数据分为多个批次,batch_size指定每个批次包含几个图片,shuffle为是否打乱图片,num_workers指定多个线程去加载数据。
当训练很快、加载数据时间过慢时会导致模型等待数据加载而变慢,这时可以采用多线程来加载数据。
import torch
import torchvision
# 定义数据预处理操作
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 加载数据
data_path = 'D:/Temp/MachineLearning/data'
train_set = torchvision.datasets.CIFAR10(root=data_path, train=True, download=True, transform=transform)
test_set = torchvision.datasets.CIFAR10(root=data_path, train=False, download=True, transform=transform)
# 封装为批数据
train_loader = torch.utils.data.DataLoader(train_set, batch_size=4, shuffle=True, num_workers=2)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=4, shuffle=False, num_workers=2)
# 定义标签值
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
我们通过matplotlib打印其中的一个批次图片和标签。由于之前将图片标准化,所以需要进行反标准化操作。
由于CiFAR10的图片数据为3×32×32,需要使用transpose将其转为32×32×3
import matplotlib.pyplot as plt
import numpy as np
# 输出图像的函数
def imshow(img):
img = img / 2 + 0.5 # 反标准化
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# 获取一个批次的训练图片、标签
images, labels = iter(train_loader).next()
# 显示图片
imshow(torchvision.utils.make_grid(images))
# 打印图片标签
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
显示结果如下:

定义网络和参数
如下定义卷积网络类并创建一个对象net,以及定义训练的损失函数和优化器
nn.Conv2d(3, 6, 5)代表使用pytorch自带的二维卷积网络,输入通道为3,输出通道为6,卷积核大小为5×5。
输入的一个批次有四张32×32的3通道图片[4, 3, 32, 32],输出大小=(输入大小-卷积核+padding)/stride+1,这里默认padding为0,stride为1,所以卷积后为[4, 6, 28, 28]
nn.MaxPool2d(2, 2)为最大池化函数,池化窗口大小为2,步长也为2,由于窗口大小为2,所以图片大小会/2,即池化后为[4, 6, 14, 14]
之后经过view()将x转化为[4, 400]的二维张量,再经过由nn.Linear()实现的三个全连接层,由400->120->84->10映射为10个分类
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 定义卷积网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x): # 输入x:[4, 3, 32, 32]
x = self.pool(F.relu(self.conv1(x))) # x:[4, 6, 14, 14]
x = self.pool(F.relu(self.conv2(x))) # x:[4, 16, 5, 5]
x = x.view(-1, 16 * 5 * 5) # x:[4, 400]
x = F.relu(self.fc1(x)) # x:[4, 120]
x = F.relu(self.fc2(x)) # x:[4, 84]
x = self.fc3(x) # x:[4, 10]
return x
net = Net()
criterion = nn.CrossEntropyLoss() # 损失函数
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # 优化器
训练并保存模型
如下所示进行两轮叠代训练,每轮按批次取出训练集的数据投入模型进行训练
for epoch in range(2): # 进行两轮迭代训练
running_loss = 0.0
# 按批次取出数据进行训练
for i, data in enumerate(train_loader, 0):
inputs, labels = data # 获取数据和标签
optimizer.zero_grad() # 清零梯度缓存
outputs = net(inputs) # 得到预测结果
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 每隔两千次输出一次平均损失值
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
# 保存训练好的模型
MODEL_PATH = './cifar_net.pth'
torch.save(net.state_dict(), MODEL_PATH)
载入模型进行测试
模型以及训练好并保存了,那么模型的预测效果如何呢?
这就需要在测试集数据上进行检测了,如下所示,我们首先读取保存的模型,然后将测试集的图片数据images投入模型进行预测,然后取得预测值predicted,将其和测试集的标签labels进行比对,统计预测正确的个数correct,除以总数total就是准去率了
# 加载模型
net = Net()
net.load_state_dict(torch.load(MODEL_PATH))
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = net(images) # 将测试集图片投入模型
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0) # 统计测试集总样本数
correct += (predicted == labels).sum().item() # 累计预测正确的个数
print('在整个测试集上的准确率为: %d %%' % (100 * correct / total))
使用GPU
Nvidia显卡具有的CUDA加速可以更快地进行神经网络的训练,torch.cuda包集成了相关的操作函数。例如通过is_available()可以查看显卡是否可用,device_count()统计具有cuda功能的显卡个数,get_device_name(i)查看第i个显卡名字。
如果需要使用GPU进行网络训练,需要将模型net和训练集的数据images、标签labels都放到GPU设备上,通过model.to(device)可以将模型或张量放到指定设备上。或者直接使用model.cuda(i)放到第i块CUDA显卡上。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 获取GPU设备
print(device)
net = Net()
net.to(device) # 将模型放在GPU上
for epoch in range(2): # 进行两轮迭代训练
running_loss = 0.0
# 按批次取出数据进行训练
for i, data in enumerate(train_loader, 0):
inputs, labels = data
inputs, labels = inputs.to(device),labels.to(device) # 将训练数据放到GPU
......
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。