
Python根据Excel表进行文件重命名的实现示例
作者:PythonFun
一、问题背景
在日常办公过程中,批量重命名是经常使用的操作。之前我们已经进行了初步探索,主要是通过批处理文件、renamer软件或者Python中的pathlib等模块对当前目录下的文件进行批量重命名。
而今天我们要使用的是Python+Excel的方法对指定目录下的文件进行个性化的重命名。采用这种方法有以下两种优势:
1. 个性化重命名
原文件名和目标文件名没有规律,无法通过正则表达式进行重命名,可以用Excel对文件名进行手动编辑,对指定文件进行个性化的重命名。
2. 支持逆向重命名
以往批量重命名前,需要对原文件名进行备份,否则重命名后还需要手动改回来,十分麻烦。而这种方法只需要交换A列和B列的数据,就可以进行逆向重命名,不必担心改完后不能恢复原文件名。
二、批量重命名实现过程
1.问题的提出
当前目录下有AAA.txt,BBB.txt, CCC.txt等多个文件,我们需要把它们批量重命名为111.txt, 222.txt, 333.txt这样的形式,一般的批量重命名的方法很难实现。
问题的提出
2. 问题分析
我们把需要重命名的文件选中,在【主页】标签下点击【复制路径】获取这些文件名的路径。
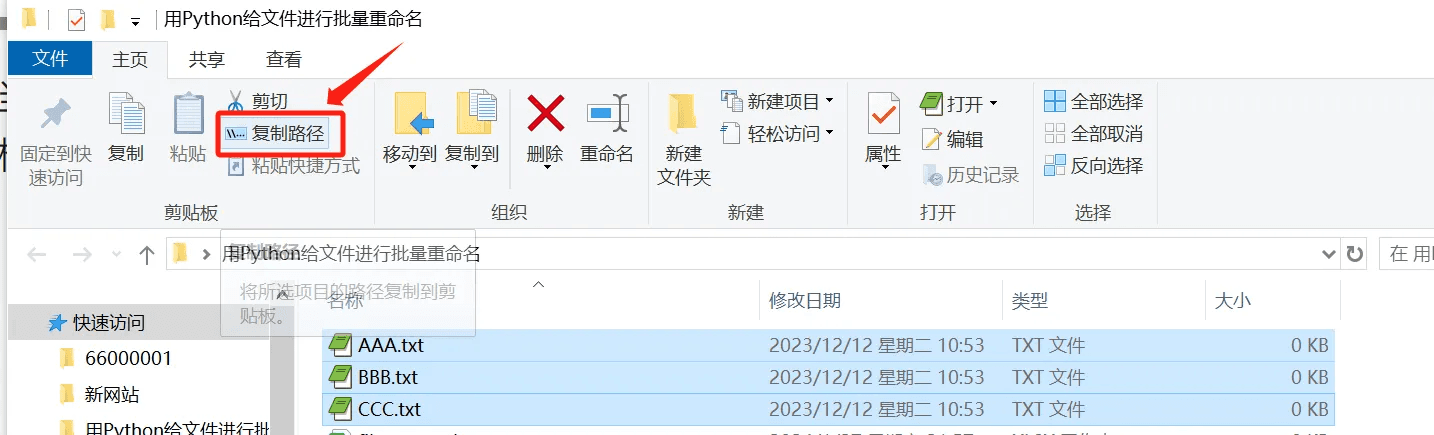
获取文件路径
然后我们就可以得到下面这种样式:
"G:\桌面\用Python给文件进行批量重命名\AAA.txt" "G:\桌面\用Python给文件进行批量重命名\BBB.txt" "G:\桌面\用Python给文件进行批量重命名\CCC.txt"
把上面的内容复制到Excel中,按"\"和引号进行【分列】操作,最后得到【111.txt, 222.txt, 333.txt】这样的文件名,然后放到A列中,如下图所示:

批量重命名Excel文件
Excel表中,A列为旧的文件名, B列为新的文件名,我们可以手动对新文件名进行修改,然后通过Python读取txg每一行,把A列文件名重命名为B列对应的文件名。
3. 问题的解决
下一步,我们就可以采用Python编写对应代码:读取Excel文件中的A列和B列内容,然后遍历当前目录下的指定文件,采用os.rename()对文件进行重命名。
第一种方法:使用xlwings——过程有点儿复杂
原理就是读取file_name.xlsx文件中的内容,然后遍历每一行后,用os.rename()进行重命名。
import os
import xlwings as xw
name_path = r'file_name.xlsx'
# 打开工作簿
app = xw.App(visible=False, add_book=False)
app.display_alerts = False # 关闭一些提示信息,可以加快运行速度。 默认为 True
app.screen_updating = False # 更新显示工作表的内容。默认为 True。关闭它也可以提升运行速度
wb = app.books.open(name_path)
# 获取数据源表格
sht = wb.sheets['name']
col_data_old = sht.range('A2:A200').value # 旧文件名,A列
col_data_new = sht.range('B2:B200').value # 新文件名,B列
# 重命名
for i in range(len(col_data_new)):
if col_data_old[i] is not None and col_data_new[i] is not None:
# 如果单元格值不是 None,则处理这些值
file_name = os.path.abspath(col_data_old[i])
file_rename = os.path.abspath(col_data_new[i])
os.rename(file_rename, file_name)
# 保存表格并退出
wb.save()
wb.close()
app.quit()第二种方法:采用openpyxl——简化代码
相比xlwings,openpyxl的代码更为简单,逻辑也很清晰。导入模块,打开工作簿,获取表格的内容,循环每一行,读取非空数据,然后用os.rename()进行重命名。
import os
import openpyxl
name_path = r'file_name.xlsx'
# 打开工作簿
wb = openpyxl.load_workbook(name_path)
# 获取数据源表格
sht = wb.worksheets[0]
# 获取 A 列和 B 列的最大行数
max_row = max(sht.max_row, sht.max_column)
# 遍历 A 列和 B 列,将非空数据添加到字典中
for row in range(2, max_row + 1):
key = sht.cell(row=row, column=1).value
value = sht.cell(row=row, column=2).value
if key is not None and value is not None:
file_name = os.path.abspath(key)
file_rename = os.path.abspath(value)
os.rename(file_name, file_rename)第三种方法:Pandas法——进一步简化
pandas这个模块导入虽然有点儿慢,但是它的重命名代码量最少,搭配上pathlib,命名效率更高。实现过程是导入pandas和path模块,读取Excel文件,把A列和B列转化为一一对应的字典,然后遍历Excel表的每一行进行批量重命名。
from pathlib import Path
import pandas as pd
# 文件路径
name_path = Path('file_name.xlsx')
# 读取 Excel 文件
df = pd.read_excel(name_path)
# 将 A 列和 B 列数据转换为字典
data_dict = df.set_index(df.columns[0]).squeeze().to_dict()
# 遍历字典,执行文件重命名
for key, value in data_dict.items():
if pd.notna(key) and pd.notna(value):
file_name = Path(key).absolute() # 获取原文件的绝对路径
file_rename = Path(value).absolute()
file_name.rename(file_rename)以上代码中,首先将 Excel 文件读取到 df 这个数据框变量中,然后使用 set_index() 方法将第一列设置为索引,并使用 squeeze() 方法将结果转换为 Series。然后,使用 to_dict() 方法将 Series 转换为字典。最后,遍历字典,执行文件重命名操作。
三、学后反思
- Python在批量重命名的过程中体现出良好的跨平台性,可以把Excel表和文件连接起来,使数据的流转更加便捷。另一方面,Python在批量操作文件方面的优势明显,程序调试成功后,哪怕是上千个文件也可以轻松重命名,可以极大地提升重命名准确性和效率。
- 虽然我们可以通过交换A列和B列的数据进行逆向重命名,但是保险起见,还是在重命名之前对文件进行备份,然后再操作,以免出现操作失误的问题。
- Python程序默认是从Excel表第二行开始读取,所以一定要保留列索引,不要删除,否则可能会出现报错。
- 本次小项目涉及xlwings, openpyxl和pandas等Excel读取模块,以及os和pathlib等多个文件管理模块,对于读取它们之间的差异具有很好的帮助作用。可以明显看出,openpyxl和pandas比xlwings使用起来更简单,所以推荐初学者直接学openpyxl,高级的学习者可以学习pandas,为后期学习数据分析打下基础。
到此这篇关于Python根据Excel表进行文件重命名的实现示例的文章就介绍到这了,更多相关Python Excel文件重命名内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!