
python polars数据科学库对比Pandas优势分析
作者:程序员小寒
python polars数据科学库
今天给大家分享一个神奇的 python 库,polars。
https://github.com/pola-rs/polars
大家都知道,Pandas 是数据科学中重要的 Python 库。但它最大的缺点是对大型数据集的操作可能很慢。
Polars 是一个开源且相对较新的数据分析和处理库,为广泛流行的 Pandas 库提供了替代方案。
为什么它比 Pandas 快
根据 Polars 用户指南,其目标是 “利用机器上的所有可用内核,以提供一个闪电般快速的 DataFrame 库。”
与 Polars 相比,Pandas 本身并不跨计算机核心并行处理。而 Polars 是为并行化而设计的。
Polars 有两种不同的 API:急切 API 和惰性 API。
急切执行类似于 Pandas。这意味着直接运行代码,并立即返回结果。
延迟执行是在你需要结果之前不会运行。因此它避免了运行不必要的代码,所以延迟执行比急切执行更有效。
对于延迟执行,你必须使用 .lazy() 方法开始操作。然后你就可以为你想做的任何事情编写代码。
最后,你需要运行 .collect() 方法来显示结果。
如下所示
df.lazy()
.with_columns([(pl.col("col") * 10).alias("new_col")])
#...
.collect()
如果不运行 .collect() 方法,该操作不会立即执行。
安装库
可以直接使用 pip 进行安装。
pip install polars
之后,你可以像导入 Pandas 一样导入 Polars 。
import polars as pl import pandas as pd
Pandas and Polars 比较
乍一看,Pandas 和 Polars(急切 API)在语法上很相似,因为它们共享主要构建块:Series 和 DataFrame。
此外,Polars 中的许多表达式与 Pandas 表达式类似。
# Example expressions that work both with Pandas and Polars df.head() # Get the first n rows df.tail() # Get the last n rows df.unique() # Get unique values of this expression.
下面,我们来一起探讨一下 Polars 与 Pandas 在语法和执行时间方面的主要区别。主要从以下几个操作来进行比较。
读取数据
选择和过滤数据
创建新列
分组和聚合
读取数据
在 Polars 中读取 CSV 文件会感觉很熟悉,因为你可以像在 Pandas 中一样使用 .read_csv() 方法:
# Pandas
df_pd=pd.read_csv('example.csv')
# Polars
df_pl.read_csv('example.csv')
分别使用 Pandas 和 Polars 读取示例数据集的执行时间如下所示:
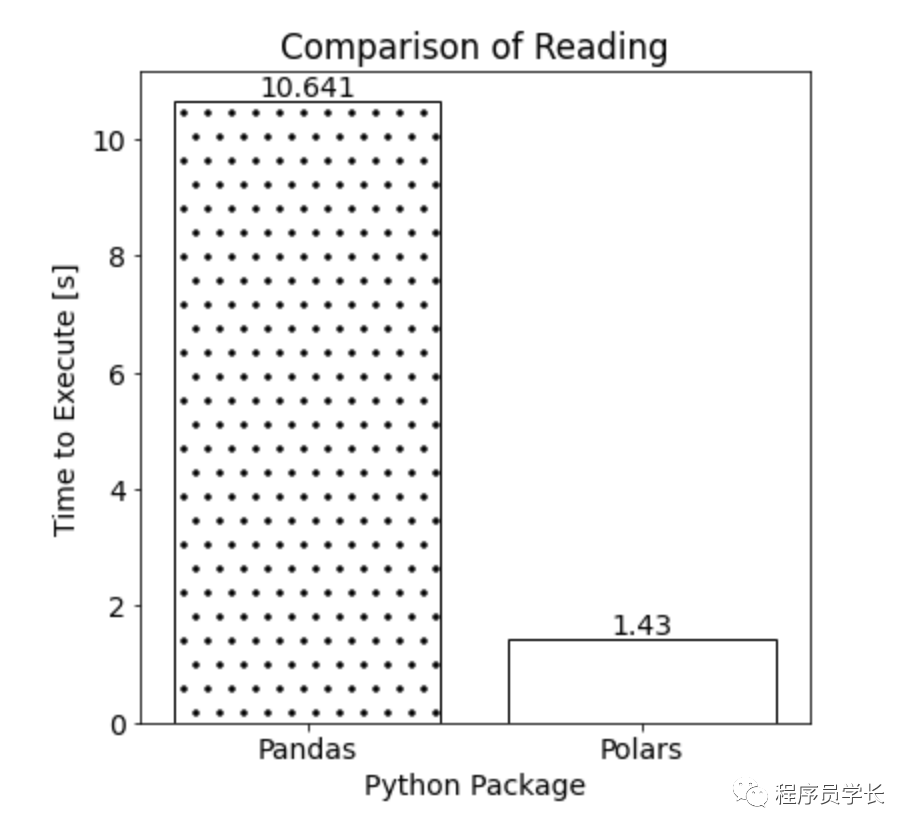
对于我们的示例数据集,使用 Pandas 读取数据所需的时间大约是使用 Polars 的八倍。
选择和过滤数据
Pandas 和 Polars 之间的第一个主要区别是 Polars 不使用索引。
尽管相同的 Pandas 代码可以在 Polars 上运行,但这不是最佳实践。
在 Polars 中,你应该使用 .select() 方法来选择数据。
# Pandas df_pd[['col1', 'col2']] # The above code will run with Polars as well, # but the correct way in Polars is: df_pl.select(['col01', 'col02'])
在 Pandas 和 Polars 中选择数据的执行时间如下所示:

对于我们的示例数据集,使用 Pandas 选择数据所需的时间大约是使用 Polars 的 15 倍。
虽然你可以在 Pandas 中使用 .query() 方法来过滤数据,但你需要在 Polars 中使用 .filter() 方法。
# Pandas
df_pd.query('col01 > 5')
# Polars
df_pl.filter(pl.col('col01') > 5)
在 Pandas 和 Polars 中过滤数据的执行时间如下所示:
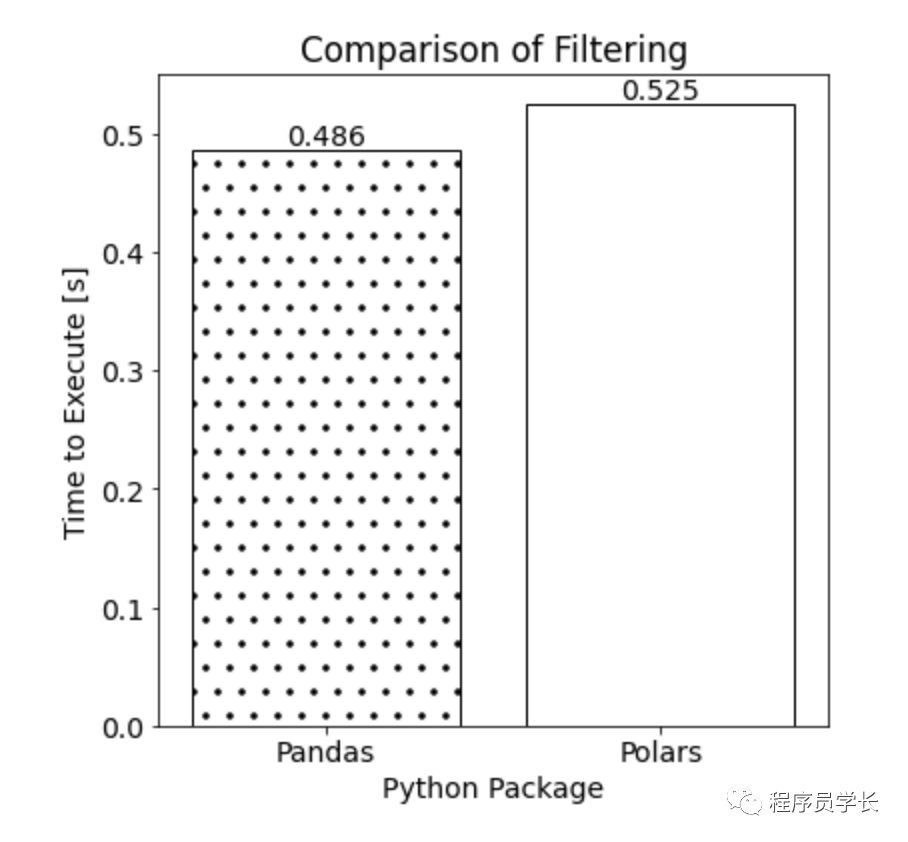
对于我们的示例数据集,在 Pandas 和 Polars 中过滤数据所需的时间相似。
与 Pandas 相比,Polars 可以并行运行 .select() 和 .filter() 中的操作。
创建新列
在 Polars 中创建新列的方法也与你在 Pandas 中的习惯不同。
在 Polars 中,你需要使用 .with_column() 或 .with_columns() 方法,具体取决于你要创建的列数。
# Pandas
df_pd["new_col"] = df_pd["col01"] * 10
# Polars
df_pl.with_column((pl.col("col01") * 10).alias("new_col"))
# Polars for multiple columns
# df_pl.with_columns([(pl.col("col01") * 10).alias("new_col"), ...])
在 Pandas 和 Polars 中创建新列的执行时间如下所示:
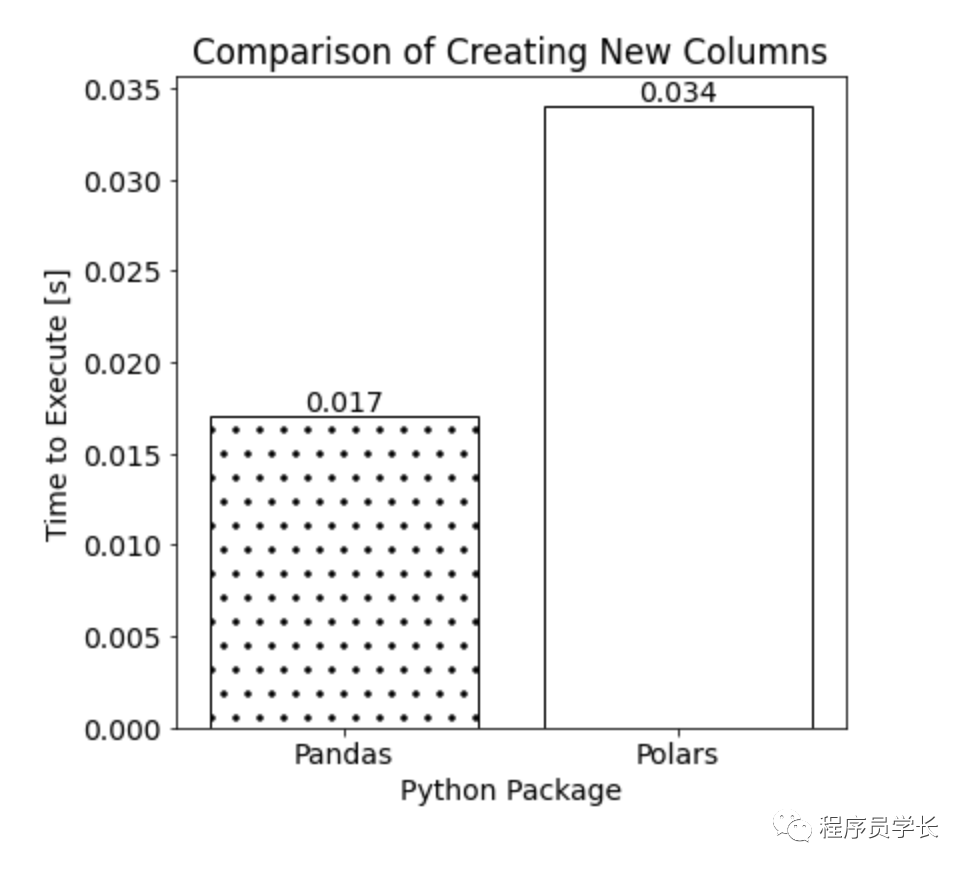
对于我们的示例数据集,使用 Polars 创建新列所需的时间大约是使用 Pandas 的两倍。
分组和聚合
Pandas 和 Polars 的分组和聚合在语法方面略有不同,但都使用 .groupby() 和 .agg() 方法。
# Pandas
df_pd.groupby('col01').col02.agg('mean')
# Polars
df_pl.groupby('col01').agg([pl.mean('col02')])
在 Pandas 和 Polars 中对数据进行分组和聚合的最终执行时间如下所示。
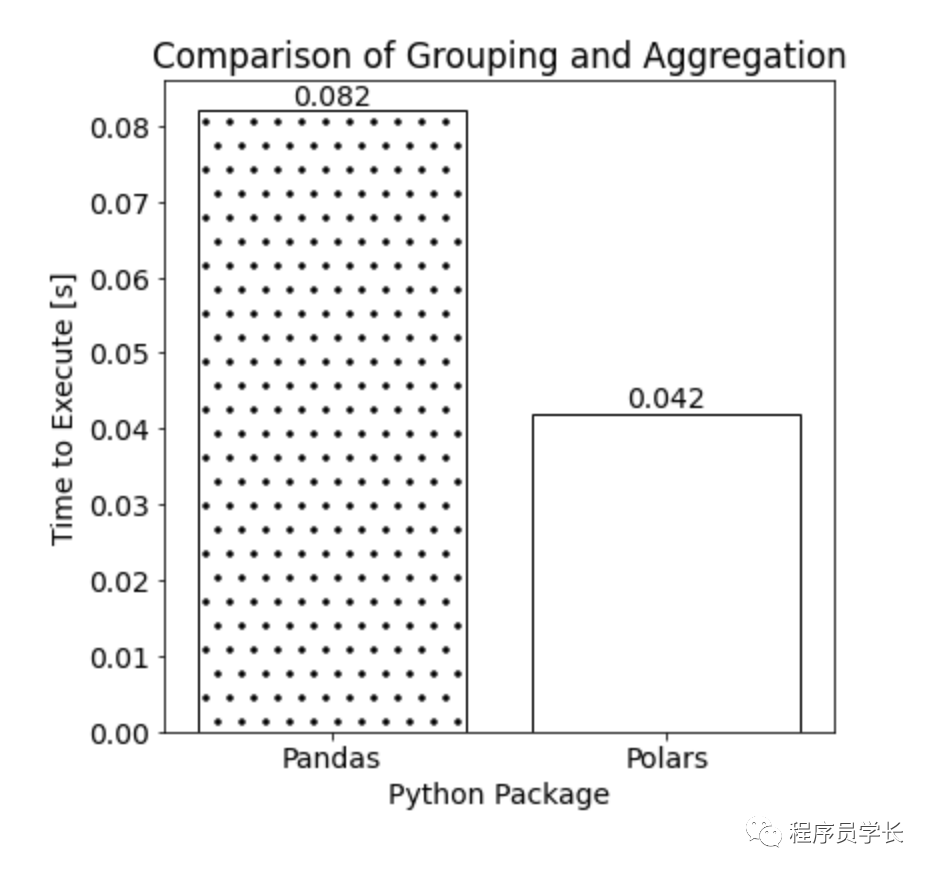
对于我们的示例数据集,使用 Pandas 聚合数据所需的时间大约是使用 Polars 的两倍。
详细源码可以查看 https://www.kaggle.com/code/iamleonie/pandas-vs-polars
Polars 相对于 Pandas 的主要优势是速度。
如果你需要对大型数据集进行大量数据处理,那么你绝对应该尝试 Polars。
此外,你可能还发现,对于相同的操作,Polars 代码通常比 Pandas 代码长一些。
以上就是python polars数据科学库对比Pandas优势分析的详细内容,更多关于python polars数据科学库的资料请关注脚本之家其它相关文章!