
python ftfy库处理金融方面文件编码错误实例详解
作者:weibin python学习与大数据分析
这篇文章主要为大家介绍了使用python ftfy库处理金融方面文件编码错误实例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪
引言
不知道大家在做爬虫或者文件内容处理时有没有遇到过编码错误的问题,反正我在处理金融方面的文件内容时经常遇到编码错误,主要是里面的数据是加密的,或者是采用了特殊编码。但现在有了这个ftfy第三方库,顿时感觉人生都变美好了!
ftfy库介绍
ftfy通过智能分析文本中的字符序列,并应用一系列复杂的规则来猜测原本正确的编码,从而有效地纠正编码错误。该库适用于各种常见的转义序列、MoJibake(日文汉字乱码)、以及其他由不恰当的编码转换产生的异常字符。
安装ftfy
在使用之前,首先确保安装了ftfy库。在命令行中运行以下命令进行安装:
pip install ftfy
ftfy的实际使用示例
比如,你从某个网络资源获取了一段包含编码错误的字符串:
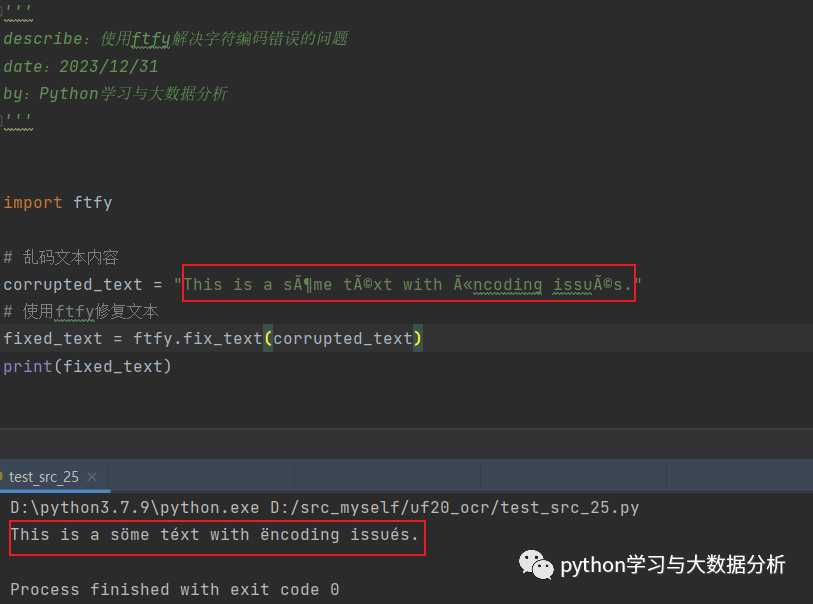
''' describe:使用ftfy解决字符编码错误的问题 date:2023/12/31 by:Python学习与大数据分析 ''' import ftfy # 乱码文本 corrupted_text = "This is a söme téxt with ëncoding issués." # 使用ftfy修复文本后,打印出来 fixed_text = ftfy.fix_text(corrupted_text) print(fixed_text)
使用ftfy.fix_text()函数会尝试修复文本中的编码错误,输出结果如下:
ftfy高级用法
除了基本的文本修复功能外,ftfy还提供了其他有用的方法,例如处理整个文件:
with open('error_file.txt', 'r', encoding='latin-1') as file: # 假设文件以Latin-1读入,实际编码未知
corrupted_content = file.read()
fixed_content = ftfy.fix_text(corrupted_content)
# 将修复后的文本写入新文件
with open('fixed_file.txt', 'w', encoding='utf-8') as fixed_file:
fixed_file.write(fixed_content)此外,ftfy还可以用于流式修复大文件,无需一次性加载到内存中:
from ftfy import fix_line
with open('error_file.txt', 'r', encoding='latin-1') as corrupt_file, \
open('ok_file.txt', 'w', encoding='utf-8') as fixed_file:
for line in corrupt_file:
fixed_line = fix_line(line)
fixed_file.write(fixed_line)以上就是python ftfy库处理金融方面文件编码错误实例详解的详细内容,更多关于python ftfy库处理编码错误的资料请关注脚本之家其它相关文章!