
python批量爬取图片的方法详解
作者:开心就好啦啦啦
这篇文章给大家介绍了如何使用python批量爬取图片,文中通过代码示例给大家介绍的非常详细,对大家的学习或工作有一定的帮助,需要的朋友可以参考下
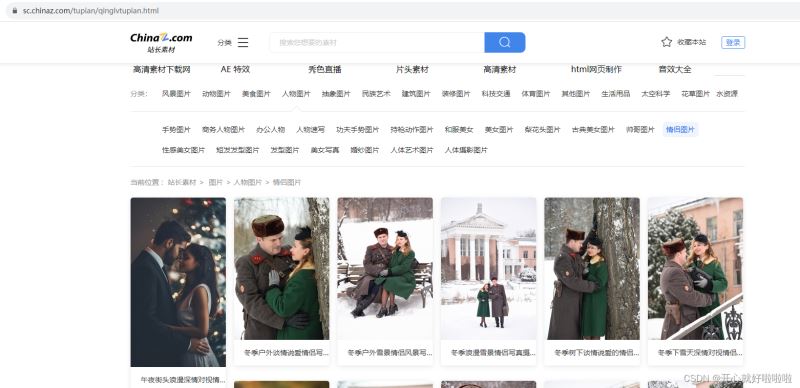
爬取的目标网站为
https://sc.chinaz.com/tupian/qinglvtupian.html
如果爬取多页,需要依次遍历每一页,经过分析跳转其它页面的规律如下
https://sc.chinaz.com/tupian/qinglvtupian_N.html N从2开始,除了第一页不同,后面跳转其它页面规律相同
爬虫步骤
- 根据请求url地址获取网页源码,使用requests库
- 通过xpath解析源码获取需要的数据
- 获取到数据下载到本地
爬取前十页图片到本地
根据页码获取网络源码
def create_request(page):
if page == 1:
url = 'https://sc.chinaz.com/tupian/qinglvtupian.html'
else:
url = 'https://sc.chinaz.com/tupian/qinglvtupian_'+str(page)+'.html'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url,headers=header)
#获取网络源码
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
使用xpath解析网页
使用xpath需要在chrome中安装此插件,安装xpath完成后,按alt+shift+x就会出现黑框
//img[@class="lazy"]/@alt #获取图片名称 //img[@class="lazy"]/@data-original #获取图片地址
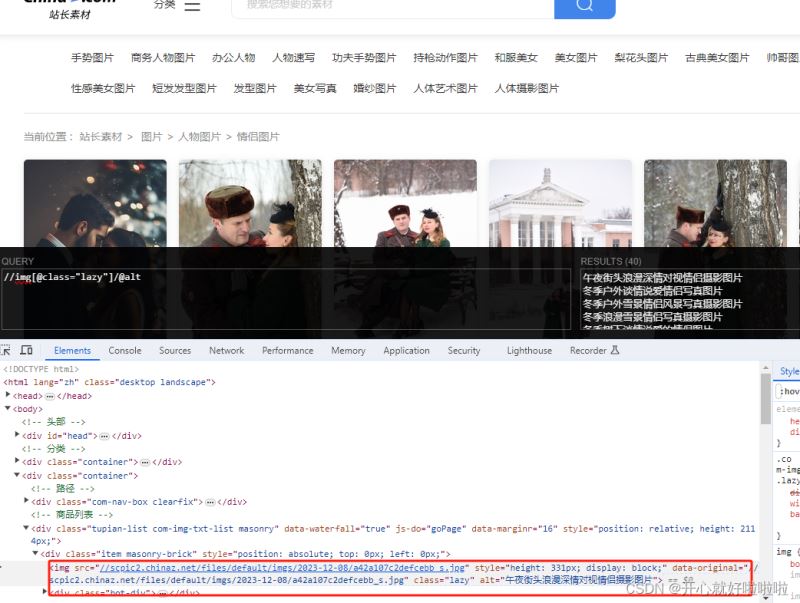
解析网页并下载图片
下载图片、网页、视频使用的函数为urllib.request.urlretrieve()
def down_load(content):
tree = etree.HTML(content) #解析网页数据 解析本地的html文件 etree.parse('D:/pages/test.html')
name_list = tree.xpath('//img[@class="lazy"]/@alt')
# 图片会进行懒加载
src_list = tree.xpath('//img[@class="lazy"]/@data-original')
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
url = 'https:'+src
urllib.request.urlretrieve(url,filename='../loveImg/'+name+'.jpg')#先在当前目录下创建loveImg文件夹
主函数如下
if __name__ == '__main__':
start_page = int(input("开始页"))
end_page = int(input("结束页"))
for page in range(start_page,end_page+1):
context = create_request(page)
down_load(context)
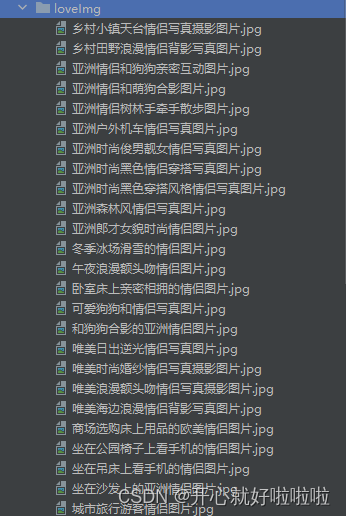
下载的图片会在loveImg目录
以上就是python批量爬取图片的方法详解的详细内容,更多关于python批量爬取图片的资料请关注脚本之家其它相关文章!