
如何使用python的opencv实现人脸识别
作者:小牛不爱吃糖
简介:本项目主要使用python语言,主要的模块库有os,opencv-python,opencv-contrib-python。项目主要分为三个部分,人脸录入,训练数据,实现人脸的识别。本博客包含源代码,以及各个功能模块,需求分析的详细解释,当然本项目只是简单的实现人脸识别,可以在此基础上扩展。
一:项目功能及流程分析
我们项目的主要功能,也就是最终的实现效果是当我们打开摄像头后,在摄像头里会出现我的人脸头像,且对我的人脸进行识别,在画面中能够框出我的人脸部分并显示出画面中人脸的姓名。

项目主要包含以下三个大的模块:人脸录入、训练数据、人脸识别。
主要用到的模块:
- os:为操作系统的访问提供相关功能的支持(处理文件和目录)
- opencv-python:计算机视觉和机器学习软件库
- opencv-contrib-python:opencv 的扩展模块
1、人脸录入模块。
主要目的:通过人脸录入模块去得到人脸的数据,然后通过已知数据去训练模型,得到人脸的姓名标签和人脸的一一对应关系,那么进行人脸的识别时,就能根据训练的数据去识别画面中的人脸是谁了,能够在画面中显示出它的名字。
主要功能:首先能打开摄像头,找到框出人脸的部分,且我们要对人脸部分截取保存,因为我们是训练姓名和人脸一一对应,所有别忘了保存图片的时候让用户输入姓名,为了减小图片大小,我们可以将截取的图片转化成灰度图片,不需要彩色的。步骤如下:
- 打开摄像头。
- 输入人脸对应的姓名。
- 检测画面中的人脸部分。
- 保存人脸图片。(灰度图片,不需要彩色)
2、数据训练模块。
主要目的:通过保存的数据,使用模块自带的训练器,训练得到姓名和人脸的一一对应关系。
主要功能:读取文件的 图片和姓名,开始训练数据,训练结束将数据保存。步骤如下:
- 读取保存的全部灰度图片和姓名。
- 训练数据。
- 保存数据。
3、人脸识别模块。
主要目的:根据所训练的数据,能够在我们打开摄像头的时候,标记出画面中的人脸部分,且在画面中显示人脸的姓名。
主要功能:能够打开摄像头,能够框出画面中的人脸部分,能够识别画面中的人脸并在画面中显示人脸的姓名。步骤如下:
- 打开摄像头。
- 检测人脸部分,框出人脸。
- 进行人脸识别,在画面中显示人脸姓名。
二:项目具体实现代码及结果演示
1、建立项目文件
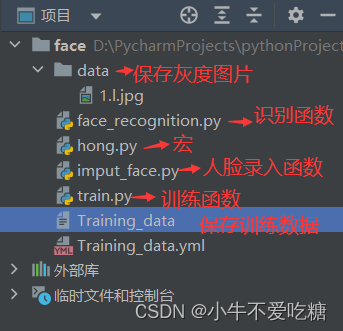
我们将本项目中用到一些路径定义为宏,保存到python文件中,命名为hong,py。将人脸灰度照片保存到文件夹中,建立文件夹data。训练数据也需要保存到文本里面,新建文本文件命名为Training_data。新建三个python文件,分别用于三个模块的具体实现。项目目录如下:
宏文件源代码供参考:
INPUT_FACE_WINDOWS_NAME = 'input_face' BGR_GREEN = (0, 255, 0) BGR_RED = (0, 0, 255) FACE_MIN_SIZE = (60, 60) # 保存图片的路径 IMG_SAVE_PATH = './data' # 级联人脸特征检测器 FACE_CLASSIFIER_PATH = 'D:/python_project/Lib/site-packages/cv2/data/haarcascade_frontalface_alt2.xml' TRAIN_DATA_SAVE_PATH = './Training_data' FACE_RECOGNITION_WINDOW_NAME = "Face recognition" FONT_SCALE = 0.75 # 字体比例 TEXT_THICKNESS = 1 # 线条粗细 GRAPH_THICKNESS = 1
2、人脸录入模块代码实现。
import cv2 as cv
from hong import *
import os
def img_extract_faces(img): # 将人脸图片转为灰度
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY) # 转成灰度图像
face_classifier = cv.CascadeClassifier(FACE_CLASSIFIER_PATH) # 加载级联检测器,人脸特征分类器
return face_classifier.detectMultiScale(gray, minSize=FACE_MIN_SIZE), gray
def get_image_name(name): # 获取图片的命名名字,格式:1.lihua.jpg
# 1.lihua.jpg 格式。如果文件中没有则加入,如果已有则替换
# 把读出来的图片名称,用字典存,然后用name去字典里面找有没有。
f = os.listdir(IMG_SAVE_PATH) # os.listdir(IMG_SAVE_PATH)返回目标路径里的文件列表
if len(f) == 0: # 文件列表f的长度为0则表示没有图片,编号为1
name_number = 1
else: # 说明原文件有人脸照片,如果出现相同人脸姓名替换成新的,没有编号为最大值max.name.jpg加入进去。
name_map = {f.split('.')[1] : int(f.split('.')[0]) for f in os.listdir(IMG_SAVE_PATH)}
name_number = name_map[name] if name in name_map else max(name_map.values())+1
# return IMG_SAVE_PATH + str(name_number) + "." + name + ".jpg"
return str(name_number) + "." + name + ".jpg"
def save_face(faces, img, name): # 保证只有一个人脸出现在画面中
if len(faces) == 0:
print('没有检测到人脸,请调整!!!')
if len(faces) > 1:
print('检测到多个人脸,请调整!!!')
x, y, w, h = faces[0]
# 保存人脸部分,保存到文件夹,格式为 1.李华.jpg 格式。如果文件中没有则加入,如果已有则替换
cv.imwrite('./data/' + get_image_name(name), img[y: y + h, x: x + w])
print('录入成功,按 q 键退出')
def main():
# 人脸录入部分是为了得到人脸的数据,然后后面对人脸进行训练。
# 人脸数据信息主要有三个部分。1、人脸图片。 2、人脸名字。 3、编号(编号需要和名字需要统一。以为训练数据是拿序号和人脸进行比对)
# 1、人脸图片(打开摄像头、只取人脸部分、给用户实时展示人脸的画面(把人脸框出来)、保存和退出)
# 2、人脸名字。(用户输入)
# 3、编号。(文件名称记录)
# 打开摄像头
cap = cv.VideoCapture(0)
if not cap.isOpened():
print('连接摄像头失败')
# 输入人脸的名字
name = input("请输入姓名:")
if name == ' ':
print('姓名不能为空,请重新输入!!!')
print('姓名输入完成:按 s 保存,按 q 退出。')
# 循环读取摄像头的每一帧画面,然后识别画面中的人脸,识别后只保存人脸部分,作为训练数据。
while True:
ret, frame = cap.read()
if not ret:
print('读取失败')
break
# 检测人脸,且提取人脸部分。这部分直接使用一个函数封装起来。
faces, gray = img_extract_faces(frame)
# 框出人脸
for x, y, w, h in faces:
cv.rectangle(
img=frame, pt1=(x, y), pt2=(x+w, y+h),
color=BGR_GREEN, thickness=1
)
cv.imshow(INPUT_FACE_WINDOWS_NAME, frame)
# 保存和退出
k = cv.waitKey(1)
if k == ord('s'):
# 保存图像,(只需保存灰度图像)
save_face(faces, gray, name)
elif k == ord('q'):
break
# 释放内存
cap.release()
cv.destroyAllWindows()
if __name__ == '__main__':
main()运行imput_face.py录入人脸:

点击英文的s键,即可保存人脸到data文件中,如下图所示:

3、训练数据模块代码实现。
import cv2 as cv
import os
from hong import *
import numpy as np
def main():
# 获取图片完整路径
image_paths = [os.path.join(IMG_SAVE_PATH, f) for f in os.listdir(IMG_SAVE_PATH)]
# 遍历列表中的图片
faces = [cv.imread(image_path, 0) for image_path in image_paths]
# 获取训练对象
img_ids = [int(f.split('.')[0])for f in os.listdir(IMG_SAVE_PATH)]
recognizer = cv.face.LBPHFaceRecognizer_create()
recognizer.train(faces, np.array(img_ids))
print(faces, np.array(img_ids))
# 保存文件
recognizer.write(TRAIN_DATA_SAVE_PATH)
if __name__ == '__main__':
main()运行train.py文件训练data文件夹里面的数据:

4、人脸识别模块代码实现。
"""
通过摄像头识别人脸(LBPH识别器(训练的数据,和当前的人脸图片))得到编号。编号和人脸的对应关系,标记人脸和名字并展示画面
创建识别器,加载训练数据
读取文件构造编号和人脸的关系
打开摄像头
循环取每帧画面
人脸检测且提取人脸部分
遍历人脸进行识别
框出人脸部分且实时展示画面(画面上带有 )
关闭摄像头和窗口
"""
import os
import cv2 as cv
from cv2 import face
from hong import *
from train import *
from imput_face import img_extract_faces
def get_color_text(confidence, name):
if confidence > 85:
return BGR_RED, "unknown"
return BGR_GREEN, name
def main():
# 创建识别器
recognizer = cv.face.LBPHFaceRecognizer_create()
recognizer.read(TRAIN_DATA_SAVE_PATH)
# 读取文件构造编号和人脸的关系。以字典的形式保存编号和人脸名字的关系
name_map = {int(f.split('.')[0]): f.split('.')[1] for f in os.listdir(IMG_SAVE_PATH)}
# 打开摄像头
cap = cv.VideoCapture(0)
if not cap.isOpened():
print('连接摄像头失败')
print("按q退出")
# 循环取每帧画面
while True:
ret, frame = cap.read()
if not ret:
print('读取失败')
break
# 人脸检测,且提取人脸部分。
faces, gray = img_extract_faces(frame)
# 遍历人脸进行识别
for x, y, w, h in faces:
img_id, confidence = recognizer.predict(gray[y: y+h, x: x+w])
# 返回图片编号和置信度。置信度为两张图片的相似程度
# 框出人脸且实时展示画面
color, text = get_color_text(confidence, name_map[img_id])
cv.putText(
img=frame, text=text, org=(x, y),
fontFace=cv.FONT_HERSHEY_SIMPLEX, fontScale=FONT_SCALE,
color=color, thickness=TEXT_THICKNESS
)
cv.circle(
img=frame, center=(x+w//2, y+h//2),
radius=w // 2,
color=color, thickness=GRAPH_THICKNESS
)
cv.imshow(FACE_RECOGNITION_WINDOW_NAME, frame)
if cv.waitKey(1) == ord('q'):
break
# 关闭摄像头,释放空间
cap.release()
cv.destroyAllWindows()
if __name__ == '__main__':
main()运行face_recognition.py文件进行人脸识别:

项目介绍到这里,感谢阅读!!!
到此这篇关于使用python的opencv实现人脸识别的文章就介绍到这了,更多相关python opencv人脸识别内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!