
Python 哈希表的实现——字典详解
作者:edisonfish
接触过 Python 的小伙伴应该对【字典】这一数据类型都了解吧
虽然 Python 没有显式名称为“哈希表”的内置数据结构,但是字典是哈希表实现的数据结构
在 Python 中,字典的键(key)被哈希,哈希值决定了键对应的值(value)在字典底层数据存储中的位置
那么今天我们就来看看哈希表的原理以及如何实现一个简易版的 Python 哈希表
ps:文中提到的 Python 指的是 CPyhton 实现
何为哈希表?
哈希表(hash table)通常是基于“键-值对”存储数据的数据结构
哈希表的键(key)通过哈希函数转换为哈希值(hash value),这个哈希值决定了数据在数组中的位置。这种设计使得数据检索变得非常快
举个例子,下面有一组键值对数据,其中歌手姓名是 key,歌名是 value
+------------------------------+ | Key | Value | +------------------------------+ | Kanye | Come to life | | XXXtentacion | Moonlight | | J.cole | All My Life | | Lil wanye | Mona Lisa | | Juice WRLD | Come & Go | +------------------------------+
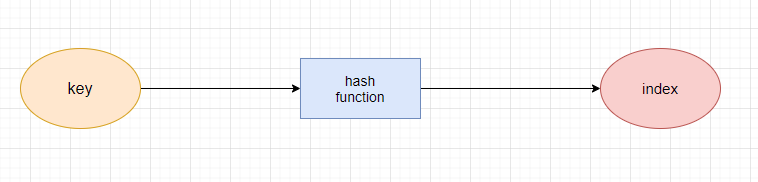
如果我们想要将这些键值对存储在哈希表中,首先需要将键的值转换成哈希表的数组的索引,这时候就需要用到哈希函数了
哈希函数是哈希表实现的主要关键,它能够处理键然后返回存放数据的哈希表中对应的索引
一个好的哈希函数能够在数组中均匀地分布键,尽量避免哈希冲突(两个键返回了相同的索引)
哈希函数是如何处理键的,这里我们创建一个简易的哈希函数来模拟一下(实际上哈希函数要比这复杂得多)
def simple_hash(key, size):
return ord(key[0]) % size这个简易版哈希函数将歌手名(即 key)首字母的 ASCII 值与哈希表大小取余,得出来的值就是歌名(value)在哈希表中的索引
那这个简易版哈希函数有什么问题呢?聪明的你一眼就看出来了:容易出现碰撞。因为不同的键的首字母有可能是一样的,就意味着返回的索引也是一样的
例如我们假设哈希表的大小为 10 ,我们以上面的歌手名作为键然后执行 simple_hash(key, 10) 得到索引
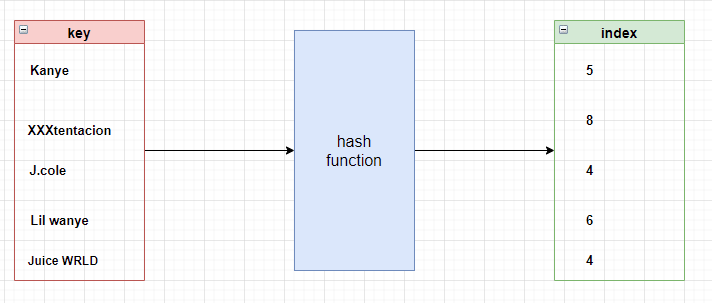
可以看到,由于Juice WRLD 和 J.cole 的首字母都一样,哈希函数返回了相同的索引,这里就发生了哈希碰撞
虽然几乎不可能完全避免任何大量数据的碰撞,但一个好的哈希函数加上一个适当大小的哈希表将减少碰撞的机会
当出现哈希碰撞时,可以使用不同的方法(例如开放寻址法)来解决碰撞
应该设计健壮的哈希函数来尽量避免哈希碰撞
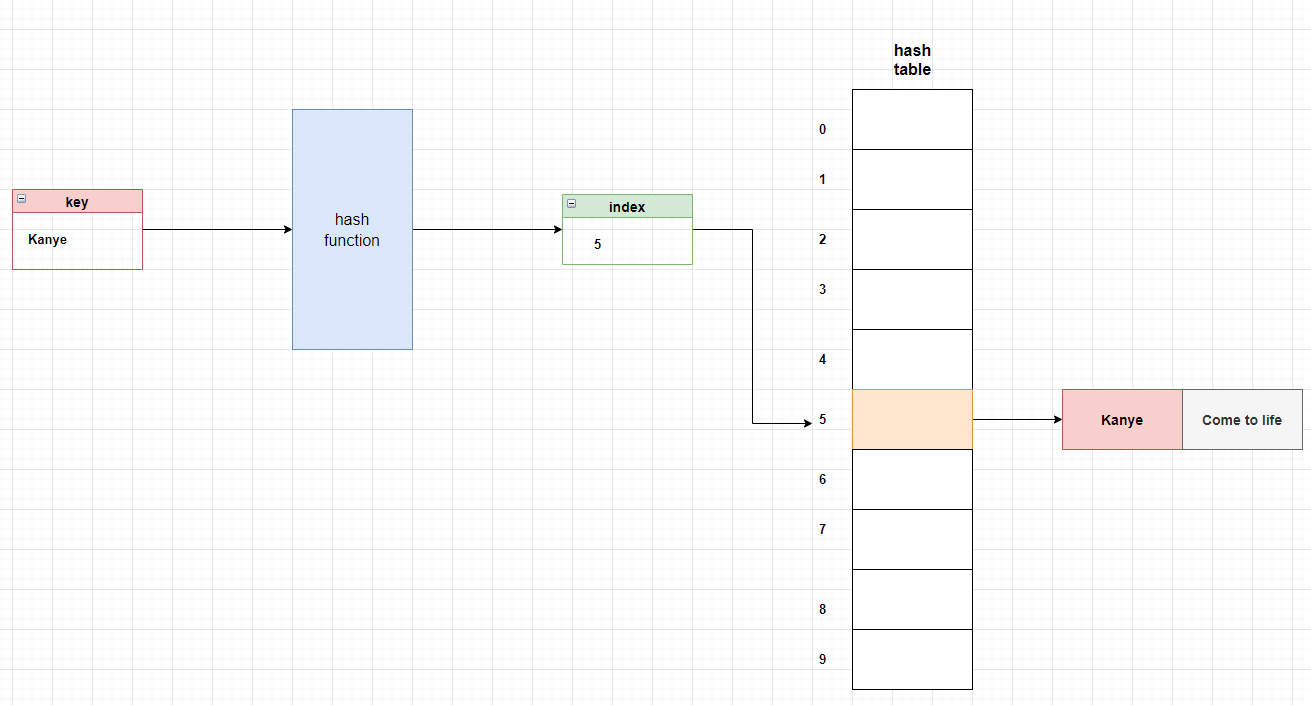
我们再来看其他的键,Kanye 通过 simple_hash() 函数返回 index 5,这意味着我们可以在索引 5 (哈希表的第六个元素)上找到 其键 Kanye 和值Come to life
哈希表优点
在哈希表中,是根据哈希值(即索引)来寻找数据,所以可以快速定位到数据在哈希表中的位置,使得检索、插入和删除操作具有常数时间复杂度 O(1) 的性能
与其他数据结构相比,哈希表因其效率而脱颖而出
不但如此,哈希表可以存储不同类型的键值对,还可以动态调整自身大小
Python 中的哈希表实现
在 Python 中有一个内置的数据结构,它实现了哈希表的功能,称为字典
Python 字典(dictionary,dict)是一种无序的、可变的集合(collections),它的元素以 “键值对(key-value)”的形式存储
字典中的 key 是唯一且不可变的,这意味着它们一旦设置就无法更改
my_dict = {"Kanye": "Come to life", "XXXtentacion": "Moonlight", "J.cole": "All My Life"}在底层,Python 的字典以哈希表的形式运行,当我们创建字典并添加键值对时,Python 会将哈希函数作用于键,从而生成哈希值,接着哈希值决定对应的值将存储在内存的哪个位置中
所以当你想要检索值时,Python 就会对键进行哈希,从而快速引导 Python 找到值的存储位置,而无需考虑字典的大小
my_dict = {}
my_dict["Kanye"] = "Come to life" # 哈希函数决定了 Come to life" 在内存中的位置
print(my_dict["Alice"]) # "Come to life" 可以看到,我们通过方括号[key]来访问键对应的值,如果键不存在,则会报错
print(my_dict["Kanye"]) # "Come to life" # Raises KeyError: "Drake" print(my_dict["Drake"])
为了避免该报错,我们可以使用字典内置的 get() 方法,如果键不存在则返回默认值
print(my_dict.get('Drake', "Unknown")) # Unknown在 python 中实现哈希表
首先我们定义一个 HashTable 类,表示一个哈希表数据结构
class HashTable:
def __init__(self, size):
self.size = size
self.table = [None]*size
def _hash(self, key):
return ord(key[0]) % self.size在构造函数 __init__() 中:
size表示哈希表的大小table是一个长度为size的数组,被用作哈希表的存储结构。初始化时,数组的所有元素都被设为None,表示哈希表初始时不含任何数据
在内部函数 _hash() 中,用于计算给定 key 的哈希值。它采用给定键 key 的第一个字符的 ASCII 值,并使用取余运算 % 将其映射到哈希表的索引范围内,以便确定键在哈希表中的存储位置。
然后我们接着在 HashTable 类中添加对键值对的增删查方法
class HashTable:
def __init__(self, size):
self.size = size
self.table = [None]*size
def _hash(self, key):
return ord(key[0]) % self.size
def set(self, key, value):
hash_index = self._hash(key)
self.table[hash_index] = (key, value)
def get(self, key):
hash_index = self._hash(key)
if self.table[hash_index] is not None:
return self.table[hash_index][1]
raise KeyError(f'Key {key} not found')
def remove(self, key):
hash_index = self._hash(key)
if self.table[hash_index] is not None:
self.table[hash_index] = None
else:
raise KeyError(f'Key {key} not found')其中,set() 方法将键值对添加到表中,而 get() 该方法则通过其键检索值。该 remove() 方法从哈希表中删除键值对
现在,我们可以创建一个哈希表并使用它来存储和检索数据:
# 创建哈希表
hash_table = HashTable(10)
# 添加键值对
hash_table.set('Kanye', 'Come to life')
hash_table.set('XXXtentacion', 'Moonlight')
# 获取值
print(hash_table.get('XXXtentacion')) # Outputs: 'Moonlight'
# 删除键值对
hash_table.remove('XXXtentacion')
# 报错: KeyError: 'Key XXXtentacion not found'
print(hash_table.get('XXXtentacion'))前面我们提到过,哈希碰撞是使用哈希表时不可避免的一部分,既然 Python 字典是哈希表的实现,所以也需要相应的方法来处理哈希碰撞
在 Python 的哈希表实现中,为了避免哈希冲突,通常会使用开放寻址法的变体之一,称为“线性探测”(Linear Probing)
当在字典中发生哈希冲突时,Python 会使用线性探测,即从哈希冲突的位置开始,依次往后查找下一个可用的插槽(空槽),直到找到一个空的插槽来存储要插入的键值对。
这种方法简单直接,可以减少哈希冲突的次数。但是,它可能会导致“聚集”(Clustering)问题,即一旦哈希表中形成了一片连续的已被占用的位置,新元素可能会被迫放入这片区域,导致哈希表性能下降
为了缓解聚集问题,假若当哈希表中存放的键值对超过哈希表长度的三分之二时(即装载率超过66%时),哈希表会自动扩容
最后总结一下:
- 在哈希表中,是根据哈希值(即索引)来寻找数据,所以可以快速定位到数据在哈希表中的位置
- Python 的字典以哈希表的形式运行,当我们创建字典并添加键值对时,Python 会将哈希函数作用于键,从而生成哈希值,接着哈希值决定对应的值将存储在内存的哪个位置中
- Python 通常会使用线性探测法来解决哈希冲突问题
到此这篇关于Python 哈希表的实现——字典的文章就介绍到这了,更多相关Python 哈希表字典内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!