
Matplotlib实战之平行坐标系绘制详解
作者:databook
平行坐标系是一种统计图表,它包含多个垂直平行的坐标轴,每个轴表示一个字段,并用刻度标明范围。通过在每个轴上找到数据点的落点,并将它们连接起来形成折线,可以很容易地展示多维数据。
随着数据增多,折线会堆叠,分析者可以从中发现数据的特性和规律,比如发现数据之间的聚类关系。
尽管平行坐标系与折线图表面上看起来相似,但它并不表示趋势,各个坐标轴之间也没有因果关系。
因此,在使用平行坐标系时,轴的顺序是可以人为决定的,这会影响阅读的感知和判断。较近的两根坐标轴会使对比感知更强烈。
因此,为了得出最合适和美观的排序方式,通常需要进行多次试验和比较。
同时,尝试不同的排序方式也可能有助于得出更多的结论。
此外,平行坐标系的每个坐标轴很可能具有不同的数据范围,这容易导致读者的误解。
因此,在绘制图表时,最好明确标明每个轴上的最小值和最大值。
1. 主要元素
平行坐标系是一种常用的数据可视化方法,用于展示多个维度的数据,并通过连接这些维度的线段来揭示它们之间的关系。
它的主要元素包括:
- 坐标轴:平行坐标系通常由垂直于数据维度的坐标轴组成,每个坐标轴代表一个数据维度。
- 数据点:每个数据点在平行坐标系中由一条连接各个坐标轴的线段表示,线段的位置和形状反映了数据点在各个维度上的取值。
- 连接线:连接线用于将同一数据点在不同维度上的线段连接起来,形成数据点的轮廓,帮助观察者理解数据点在各个维度上的变化趋势。

2. 适用的场景
平行坐标系适用的场景有:
- 多维数据分析:平行坐标系适用于展示多个维度的数据,帮助观察者发现不同维度之间的关系和趋势,例如在探索数据集中的模式、异常值或相关性时。
- 数据分类和聚类:通过观察数据点的轮廓和分布,可以帮助观察者识别不同的数据类别或聚类。
- 数据交互与过滤:平行坐标系可以支持交互式数据探索和过滤,通过选择或操作特定的坐标轴或线段,可以对数据进行筛选和聚焦。
3. 不适用的场景
平行坐标系不适用的场景有:
- 数据维度过多:当数据维度过多时,平行坐标系的可读性和解释性可能会下降,因为线段之间的交叉和重叠会导致视觉混乱。
- 数据维度之间差异较大:如果数据在不同维度上的取值范围差异较大,那么线段之间的比较和分析可能会受到影响,因为较小的取值范围可能会被较大的取值范围所掩盖。
- 数据具有时间序列:平行坐标系并不适用于展示时间序列数据,因为它无法准确地表示数据的时间顺序。在这种情况下,其他的数据可视化方法,如折线图或时间轴图,可能更适合。
4. 分析实战
平行坐标系适用于展示具有相同属性的一系列数据,每个坐标系代表一种属性。
这次选用了国家统计局公开的教育类数据:databook.top/nation/A0M
选取其中几类具有相同属性的数据:
- A0M06:各级各类学校专任教师数
- A0M07:各级各类学校招生数
- A0M08:各级各类学校在校学生数
- A0M09:各级各类学校毕业生数
4.1. 数据来源
四个原始数据集是按照年份统计的:
fp = "d:/share/A0M06.csv" df = pd.read_csv(fp) df

这是教师相关统计数据,其他3个数据集的结构也类似。
4.2. 数据清理
平行坐标系比较的是属性,不需要每年的数据。
所以,对于上面4个数据集,分别提取2022年的小学,初中,高中,特殊教育相关4个属性的数据。
import os
files = {
"教师数": "A0M06.csv",
"招生数": "A0M07.csv",
"在校学生数": "A0M08.csv",
"毕业学生数": "A0M09.csv",
}
data_dir = "d:/share"
data = pd.DataFrame()
for key in files:
fp = os.path.join(data_dir, files[key])
df = pd.read_csv(fp)
df_filter = pd.DataFrame(
[[
key,
df.loc[225, "value"],
df.loc[135, "value"],
df.loc[90, "value"],
df.loc[270, "value"],
]],
columns=["name", "小学", "初中", "高中", "特殊教育"],
)
data = pd.concat([data, df_filter])
data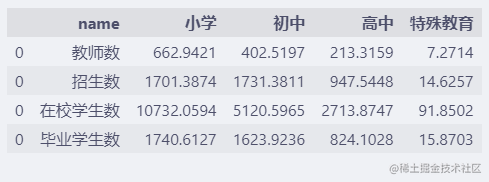
4.3. 分析结果可视化
平行坐标系在 matplotlib 中没有直接提供,实现起来也不难:
import matplotlib.pyplot as plt
from matplotlib.path import Path
import matplotlib.patches as patches
import numpy as np
xnames = data.loc[:, "name"]
ynames = ["小学", "初中", "高中", "特殊教育"]
ys = np.array(data.iloc[:, 1:].values.tolist())
ymins = ys.min(axis=0)
ymaxs = ys.max(axis=0)
dys = ymaxs - ymins
ymins -= dys * 0.05 # Y轴的上下限增加 5% 的冗余
ymaxs += dys * 0.05
#每个坐标系的上下限不一样,调整显示方式
zs = np.zeros_like(ys)
zs[:, 0] = ys[:, 0]
zs[:, 1:] = (ys[:, 1:] - ymins[1:]) / dys[1:] * dys[0] + ymins[0]
fig, host = plt.subplots(figsize=(10, 4))
axes = [host] + [host.twinx() for i in range(ys.shape[1] - 1)]
for i, ax in enumerate(axes):
ax.set_ylim(ymins[i], ymaxs[i])
ax.spines["top"].set_visible(False)
ax.spines["bottom"].set_visible(False)
if ax != host:
ax.spines["left"].set_visible(False)
ax.yaxis.set_ticks_position("right")
ax.spines["right"].set_position(("axes", i / (ys.shape[1] - 1)))
host.set_xlim(0, ys.shape[1] - 1)
host.set_xticks(range(ys.shape[1]))
host.set_xticklabels(ynames, fontsize=14)
host.tick_params(axis="x", which="major", pad=7)
host.spines["right"].set_visible(False)
host.xaxis.tick_top()
host.set_title("各类学校的师生数目比较", fontsize=18, pad=12)
colors = plt.cm.Set1.colors
legend_handles = [None for _ in xnames]
for j in range(ys.shape[0]):
verts = list(
zip(
[x for x in np.linspace(0, len(ys) - 1, len(ys) * 3 - 2, endpoint=True)],
np.repeat(zs[j, :], 3)[1:-1],
)
)
codes = [Path.MOVETO] + [Path.CURVE4 for _ in range(len(verts) - 1)]
path = Path(verts, codes)
patch = patches.PathPatch(
path, facecolor="none", lw=2, alpha=0.7, edgecolor=colors[j]
)
legend_handles[j] = patch
host.add_patch(patch)
host.legend(
xnames,
loc="lower center",
bbox_to_anchor=(0.5, -0.18),
ncol=len(xnames),
fancybox=True,
shadow=True,
)
plt.tight_layout()
plt.show()
从图表中,可以看出一下几点,和我们对实际情况的印象是差不多的:
- 教师数量远小于学生数量
- 从小学到初中,高中,学生数量不断减少
- 招生数量和毕业生数量差不多
平行坐标系用于比较不同数据集的相同属性。
以上就是Matplotlib实战之平行坐标系绘制详解的详细内容,更多关于Matplotlib平行坐标系的资料请关注脚本之家其它相关文章!