
Matplotlib实战之堆叠面积图绘制详解
作者:databook
堆叠面积图和面积图都是用于展示数据随时间变化趋势的统计图表,但它们的特点有所不同。
面积图的特点在于它能够直观地展示数量之间的关系,而且不需要标注数据点,可以轻松地观察数据的变化趋势。而堆叠面积图则更适合展示多个数据系列之间的变化趋势,它们一层层的堆叠起来,每个数据系列的起始点是上一个数据系列的结束点,多数据列的展示更加直观和易于理解。
堆叠面积图观察几个数据系列随时间的变化情况时,既能看到各数据系列的走势,又能看到整体的规模,但是,过多的系列,也会导致难以分辨。
此外,堆叠面积图展示的数据一般会有时间上的关联,当数据没有时间上的关联时,建议适用堆叠柱状图。
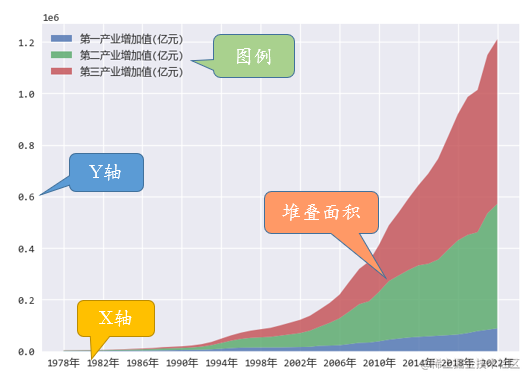
1. 主要元素
堆叠面积图是一种用于展示数据分类、分组和数据关联性的图表,主要由以下几个元素组成:
- 堆叠面积:表示数据的分布或密度
- 图例:图例用于说明堆叠图的绘制规则和参数
- X轴:一般是有序变量,表示数据点的变化区间
- Y轴:数据点在不同时刻的值
2. 适用的场景
堆叠面积图适用于以下分析场景:
- 类别占比比较:堆叠面积图可以用来比较不同类别在总体中的占比关系。例如,你可以使用堆叠面积图来展示销售额按产品类别的分布情况,以显示每个类别对总销售额的贡献。
- 趋势展示:堆叠面积图可以在一个图表中同时显示多个类别或组的趋势。它可以用来展示每个类别在不同时间点或区域的变化情况,并帮助分析人员观察和理解各类别之间的差异和趋势。
- 堆叠级别比较:堆叠面积图还可以用来比较不同级别的数据在总体中的占比关系。例如,你可以使用堆叠面积图来展示各部门在总体支出中的比例,以显示各个部门的相对贡献。
- 累积效果展示:堆叠面积图可以展示随着时间、地区或其他维度的推移,各组别所积累的整体效果。这对于观察累积效果的变化和趋势非常有帮助。
3. 不适用的场景
堆叠面积图不适用于以下分析场景:
- 数据重叠:如果数据中有重叠的部分,堆叠面积图会使数据难以解读和比较。当数据的堆叠部分变得模糊或不清晰时,堆叠面积图可能就无法有效地传达信息。
- 数据量变动:如果每个类别或组的数据量差别很大,堆叠面积图可能会导致视觉上的需求不平衡。数据量较大的类别或组可能会过于突出,而数据量较小的类别或组则可能被掩盖。
- 无法显示趋势:堆叠面积图在展示数据的总体趋势上相对有效,但却不适用于显示每个类别或组内部的趋势。如果你希望关注每个类别或组的个别趋势,那么使用其他图表类型如折线图可能更为合适。
- 存在负值数据:堆叠面积图假设数据都是正值,不适合用于展示包含负值的数据。这是因为堆叠面积图的堆叠效果会导致负值的表现相对模糊,难以准确表达。
4. 分析实战
这次使用三大产业的增加值来实战堆叠面积图的分析。
4.1. 数据来源
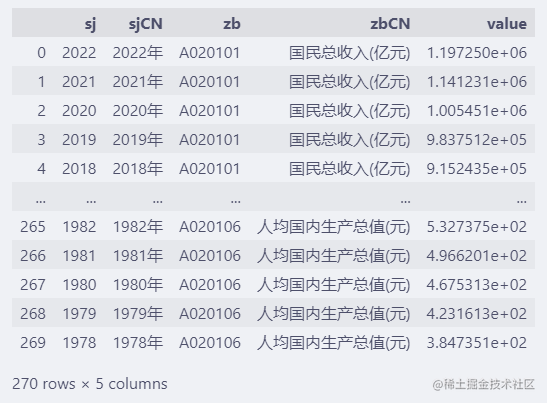
数据来源国家统计局公开数据,已经整理好的csv文件在:databook.top/nation/A02
本次分析使用其中的 A0201.csv 文件(国内生产总值数据)。
下面的文件路径 fp 要换成自己实际的文件路径。
fp = "d:/share/A0201.csv" df = pd.read_csv(fp) df
4.2. 数据清理
过滤出三大产业的数据:
key1 = "第一产业增加值(亿元)"
key2 = "第二产业增加值(亿元)"
key3 = "第三产业增加值(亿元)"
df = df[(df["zbCN"] == key1)
| (df["zbCN"] == key2)
| (df["zbCN"] == key3)]
df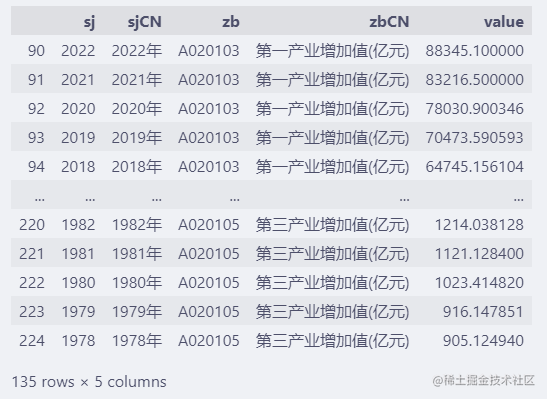
4.3. 分析结果可视化
绘制三大产业的堆叠面积图:
from matplotlib.ticker import MultipleLocator
key1 = "第一产业增加值(亿元)"
key2 = "第二产业增加值(亿元)"
key3 = "第三产业增加值(亿元)"
val1 = df[(df["zbCN"] == key1)].sort_values("sj")
val2 = df[(df["zbCN"] == key2)].sort_values("sj")
val3 = df[(df["zbCN"] == key3)].sort_values("sj")
with plt.style.context("seaborn-v0_8"):
fig = plt.figure()
ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
ax.xaxis.set_major_locator(MultipleLocator(4))
ax.xaxis.set_minor_locator(MultipleLocator(2))
ax.stackplot(
val1["sjCN"],
[val1["value"], val2["value"], val3["value"]],
labels=[key1, key2, key3],
alpha=0.8,
)
ax.legend(loc="upper left")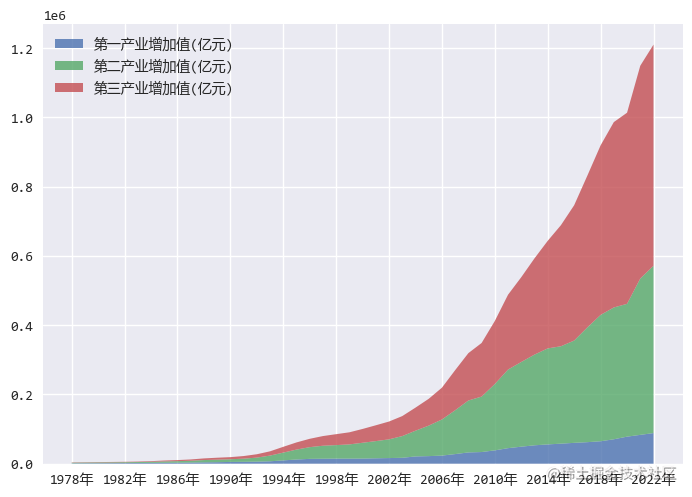
各个数据集在堆叠面积图中不会重合,所以不仅可以看出各个产业的增长情况,还能看出整体的增长主要来自哪个产业的影响。
从分析结果可以看出,我国的经济增长主要来自于第二,第三产业的增长。
这个结果和之前的文章中关于人口的分析也是相吻合的,在那个文章中,我们发现农业人口大量减少,城镇人口大量增加。
到此这篇关于Matplotlib实战之堆叠面积图绘制详解的文章就介绍到这了,更多相关Matplotlib堆叠面积图内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!