
pandas如何修改DataFrame行/列/字段值
作者:guotianqing
这篇文章主要介绍了pandas如何修改DataFrame行/列/字段值问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教
pandas修改DataFrame行/列/字段值
增加/修改一列
有如下几种方法增加一列:
- 增加具有相同值的一列
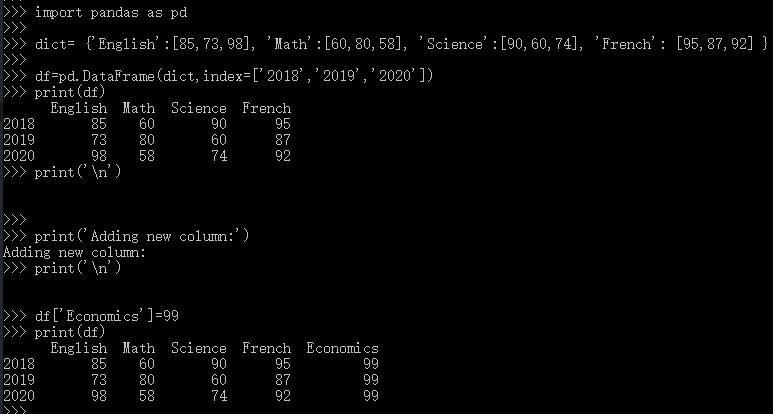
import pandas as pd
dict= {'English':[85,73,98], 'Math':[60,80,58], 'Science':[90,60,74], 'French': [95,87,92] }
df=pd.DataFrame(dict,index=['2018','2019','2020'])
print(df)
print('\n')
print('Adding new column:')
print('\n')
df['Economics']=99
print(df) 结果如下:
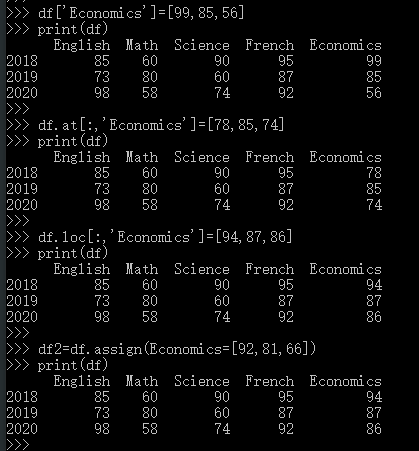
- 增加定制值的一列,此方法也可以修改原有值
df['Economics']=99 df['Economics']=[99,85,56] print(df) df.at[:,'Economics']=[78,85,74] print(df) df.loc[:,'Economics']=[94,87,86] print(df) df2=df.assign(Economics=[92,81,66]) print(df)
输出如下:
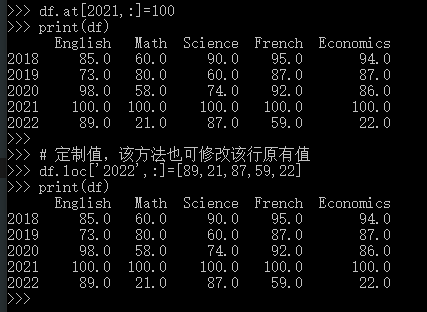
增加/修改一行
语法基本同列,直接上代码:
# 增加具有相同值的一行 df.at[2021,:]=100 print(df) # 定制值,该方法也可修改该行原有值 df.loc['2022',:]=[89,21,87,59,22] print(df)
输出如下:
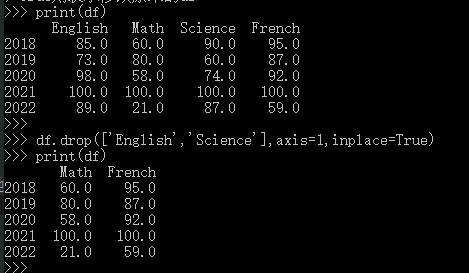
删除列
代码:
# 只有删除一列 del df['Economics'] # 可删除多列,有多个参数,其中,axis=1表示列,0表示行,inplace表示是否本地修改,默认False,返回修改后的df,原df不变,True则表示修改原来的df df.drop(['English','Science'],axis=1,inplace=True)
结果如下:
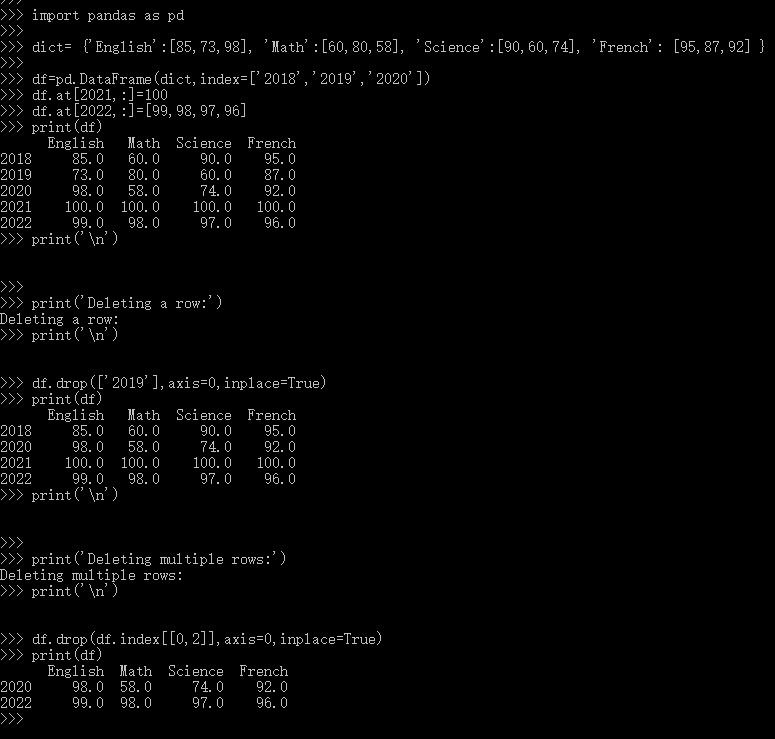
删除行
使用drop即可:
import pandas as pd
dict= {'English':[85,73,98], 'Math':[60,80,58], 'Science':[90,60,74], 'French': [95,87,92] }
df=pd.DataFrame(dict,index=['2018','2019','2020'])
df.at[2021,:]=100
df.at[2022,:]=[99,98,97,96]
print(df)
print('\n')
print('Deleting a row:')
print('\n')
df.drop(['2019'],axis=0,inplace=True)
print(df)
print('\n')
print('Deleting multiple rows:')
print('\n')
df.drop(df.index[[0,2]],axis=0,inplace=True)
print(df) 结果如下:
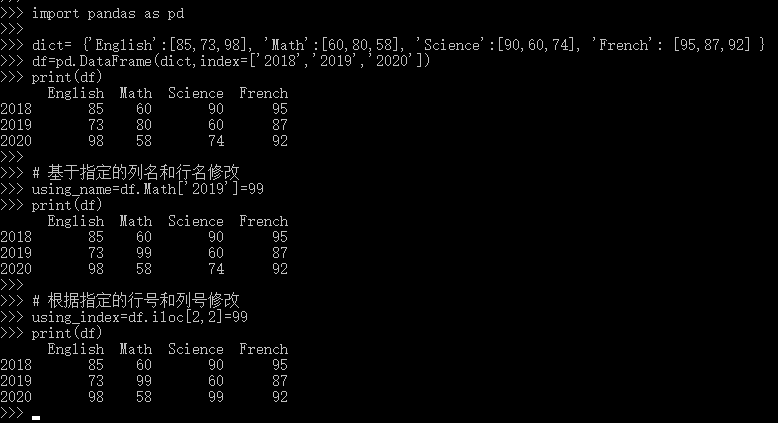
修改指定值
可以基于指定的列名和行名修改,也可以根据指定的行号和列号修改。
示例如下:
import pandas as pd
dict= {'English':[85,73,98], 'Math':[60,80,58], 'Science':[90,60,74], 'French': [95,87,92] }
df=pd.DataFrame(dict,index=['2018','2019','2020'])
print(df)
# 基于指定的列名和行名修改
using_name=df.Math['2019']=99
print(df)
# 根据指定的行号和列号修改
using_index=df.iloc[2,2]=99
print(df) 结果如下:
注意:
DataFrame提供了丰富的方法来操作数据,可以方便地对行列进行增删改操作。
pandas更改DataFrame中的值
构造DataFrame
import pandas as pd
import numpy as np
dates = pd.date_range('20200315', periods = 5)
df = pd.DataFrame(np.arange(20).reshape((5,4)), index = dates, columns = ['A','B','C','D'])
print(df)
#输出
A B C D
2020-03-15 0 1 2 3
2020-03-16 4 5 6 7
2020-03-17 8 9 10 11
2020-03-18 12 13 14 15
2020-03-19 16 17 18 19运用loc、iloc更改值
我们可以利用索引或者标签确定需要修改值的位置。
df.loc['20200318','C'] = 20200318 #标签索引 df.iloc[2,3] = 20200318 #数字索引 print(df) #输出 A B C D 2020-03-15 0 1 2 3 2020-03-16 4 5 6 7 2020-03-17 8 9 10 20200318 2020-03-18 12 13 20200318 15 2020-03-19 16 17 18 19
运用条件判断更改值
如果现在的判断条件是这样, 我们想要更改B中的数, 而更改的位置是取决于 C的. 对于C大于6的位置. 更改B在相应位置上的数为0.
df.B[df.C>6] = 0 #C字段中大于6的那些行在B字段中全都设为0 print(df) #输出 A B C D 2020-03-15 0 1 2 3 2020-03-16 4 5 6 7 2020-03-17 8 0 10 20200318 2020-03-18 12 0 20200318 15 2020-03-19 16 0 18 19
在DataFrame中添加一列
如果对整列做批处理, 加上一列 ‘E’, 并将 E 列全改为 NaN, 如下:
df['E'] = np.nan print(df) #输出 A B C D E 2020-03-15 0 1 2 3 NaN 2020-03-16 4 5 6 7 NaN 2020-03-17 8 9 10 11 NaN 2020-03-18 12 13 14 15 NaN 2020-03-19 16 17 18 19 NaN
用上面的方法也可以加上 Series 序列(但是长度必须对齐)。
df['F'] = pd.Series([11,22,33,44,55],index = pd.date_range('20200315',periods = 5))
print(df)
#输出
A B C D E F
2020-03-15 0 1 2 3 NaN 11
2020-03-16 4 5 6 7 NaN 22
2020-03-17 8 9 10 11 NaN 33
2020-03-18 12 13 14 15 NaN 44
2020-03-19 16 17 18 19 NaN 55总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。