
使用Python实现ELT统计多个服务器下所有数据表信息
作者:袁袁袁袁满
前言
在ETL相关工作中,将数据库中数据的 ER结构 整理为 Excel 可谓是一件投入产出比极低的、毫无技术含量的体力活
尤其是当你有上百张表的ER结构都要整理成 Excel 时,简直是在燃烧生命。
大把的时间浪费在了低价值的事情上,是对时间这种资源的极大浪费。
生命短暂,更多的时间应该投入到更有意义的事情上。
所以我写了两个Python脚本轻松搞定!
脚本1
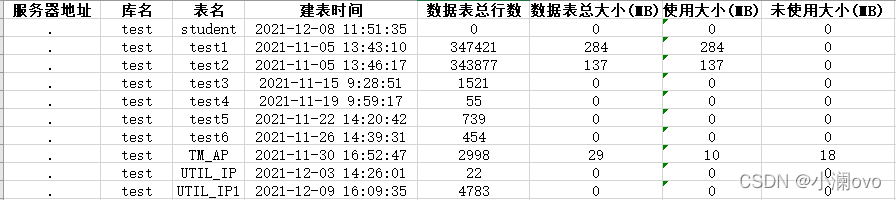
效果展示
统计出对应服务器,库名所对应表的建表时间、数据表总行数、数据表总大小、使用大小、未使用大小
代码解析
1)导入所用库
import pymssql # 操作SqlServer的库 import openpyxl as op # 操作Excel表的库
2)获取服务器下所有库名
def get_databases_name(self, cursor):
"""获取服务器下所有库名"""
sql = 'SELECT * FROM sys.sysdatabases'
cursor.execute(sql)
rows = cursor.fetchall() # 逐行读取
# 存储
databases_name = []
for list in rows:
databases_name.append(list[0])
# 移除系统库
databases_name.remove("master")
databases_name.remove("model")
databases_name.remove("msdb")
databases_name.remove("tempdb")
# 移除无用库,如果没有则可以把try...except删除
try:
databases_name.remove("ReportServer")
databases_name.remove("ReportServerTempDB")
except Exception as e:
print(e)
print(databases_name)
return databases_name- 提取服务器下所有数据库名,用于后续SQL语句的拼接,利用列表的
remove方法移除不需要的数据库
3)获取表详细信息并保存
def save(self, databases_name, cursor, server_name):
"""获取表信息并保存"""
# 加入count是为了换行写入数据
count = self.count
# databases_name:['master', 'tempdb', 'model', 'msdb', 'ReportServer', 'ReportServerTempDB', 'test']
# 取出每个库名,用于拼接sql,获取对应库名下表信息
for database in databases_name:
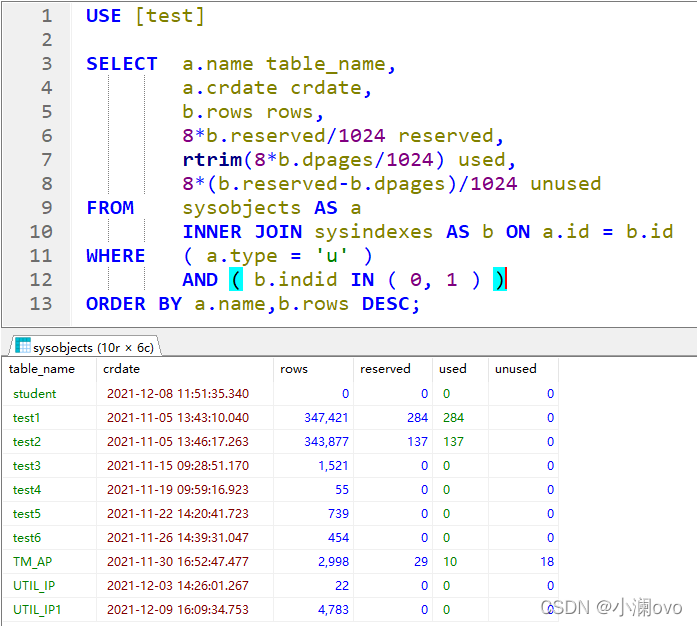
sql = '''
USE [%s]
SELECT a.name table_name,
a.crdate crdate,
b.rows rows,
8*b.reserved/1024 reserved,
rtrim(8*b.dpages/1024) used,
8*(b.reserved-b.dpages)/1024 unused
FROM sysobjects AS a
INNER JOIN sysindexes AS b ON a.id = b.id
WHERE ( a.type = 'u' )
AND ( b.indid IN ( 0, 1 ) )
ORDER BY a.name,b.rows DESC;
''' % database
cursor.execute(sql)
rows = cursor.fetchall() # 逐行读取
for i in rows:
# 要写入excel的数据
server = server_name
database_name = database
table_name = i[0]
crdate = i[1]
rows_size = i[2]
reserved = i[3]
used = i[4]
unused = i[5]
# 打印获取到的数据
# print(server, database_name, table_name, crdate, rows_size, reserved, used, unused)
# row:count所对应的就是行数,从第二行开始累加,colum:表示第几列,value:表示插入的值
self.wb.cell(row=count, column=1, value=server)
self.wb.cell(row=count, column=2, value=database_name)
self.wb.cell(row=count, column=3, value=table_name)
self.wb.cell(row=count, column=4, value=crdate)
self.wb.cell(row=count, column=5, value=rows_size)
self.wb.cell(row=count, column=6, value=reserved)
self.wb.cell(row=count, column=7, value=used)
self.wb.cell(row=count, column=8, value=unused)
# count加1,进入到下一行写入数据
count += 1
self.count = count- 拼接SQL效果:查看表名所对应建表时间、数据表总行数、数据表总大小、使用大小、未使用大小
4)实现主要逻辑
def main(self):
"""实现主要逻辑"""
# 1.创建Excel表对象,设置列名
self.ws = op.Workbook()
self.wb = self.ws.create_sheet(index=0)
self.wb.cell(row=1, column=1, value='服务器地址')
self.wb.cell(row=1, column=2, value='库名')
self.wb.cell(row=1, column=3, value='表名')
self.wb.cell(row=1, column=4, value='建表时间')
self.wb.cell(row=1, column=5, value='数据表总行数')
self.wb.cell(row=1, column=6, value='数据表总大小(MB)')
self.wb.cell(row=1, column=7, value='使用大小(MB)')
self.wb.cell(row=1, column=8, value='未使用大小(MB)')
self.count = 2 # 定义为全局变量每次用完会更新
# 服务器列表,括号内为:服务器名、账号、密码
# 如果多个服务器元组用逗号隔开
list = [('.', 'sa', 'yuan427')]
# 2.遍历服务器列表,实现统计多个服务器
for server in list:
server_name = server[0]
user_name = server[1]
password = server[2]
conn = pymssql.connect(server_name, user_name, password)
if conn:
print("连接成功!")
cursor = conn.cursor()
# 3.获取库名
databases_name = self.get_databases_name(cursor)
# 4.获取详细信息并保存
self.save(databases_name, cursor, server_name)
# 所有服务器表插入完后保存
excel_name = "./本地数据库统计.xlsx"
self.ws.save(excel_name)
# 关闭游标,关闭数据库
cursor.close()
conn.close()1.在服务器列表循环外创建Excel文件
2.遍历服务器列表,实现统计多个服务器
3.获取当前遍历服务器的所有库名
4.用库名拼接SQL实现获取数据表详细信息
5.换行保存在Excel文件 完整代码
需要修改的地方只有服务器地址、账号、密码,每一个服务器信息放一个元组中;如果有多个服务器用逗号隔开
import pymssql
import openpyxl as op
class ErTransUtils():
def get_databases_name(self, cursor):
"""获取服务器下所有库名"""
sql = 'SELECT * FROM sys.sysdatabases'
cursor.execute(sql)
rows = cursor.fetchall() # 逐行读取
# 存储
databases_name = []
for list in rows:
databases_name.append(list[0])
# 移除系统库
databases_name.remove("master")
databases_name.remove("model")
databases_name.remove("msdb")
databases_name.remove("tempdb")
# 移除无用库
try:
databases_name.remove("ReportServer")
databases_name.remove("ReportServerTempDB")
except Exception as e:
print(e)
print(databases_name)
return databases_name
def save(self, databases_name, cursor, server_name):
"""获取表信息并保存"""
# 加入count是为了换行写入数据
count = self.count
# databases_name:['master', 'tempdb', 'model', 'msdb', 'ReportServer', 'ReportServerTempDB', 'test'],取出每个库名
for database in databases_name:
sql = '''
USE [%s]
SELECT a.name table_name,
a.crdate crdate,
b.rows rows,
8*b.reserved/1024 reserved,
rtrim(8*b.dpages/1024) used,
8*(b.reserved-b.dpages)/1024 unused
FROM sysobjects AS a
INNER JOIN sysindexes AS b ON a.id = b.id
WHERE ( a.type = 'u' )
AND ( b.indid IN ( 0, 1 ) )
ORDER BY a.name,b.rows DESC;
''' % database
cursor.execute(sql)
rows = cursor.fetchall() # 逐行读取
for i in rows:
# 要写入excel的数据
server = server_name
database_name = database
table_name = i[0]
crdate = i[1]
rows_size = i[2]
reserved = i[3]
used = i[4]
unused = i[5]
# 打印获取到的数据
# print(server, database_name, table_name, crdate, rows_size, reserved, used, unused)
self.wb.cell(row=count, column=1, value=server)
self.wb.cell(row=count, column=2, value=database_name)
self.wb.cell(row=count, column=3, value=table_name)
self.wb.cell(row=count, column=4, value=crdate)
self.wb.cell(row=count, column=5, value=rows_size)
self.wb.cell(row=count, column=6, value=reserved)
self.wb.cell(row=count, column=7, value=used)
self.wb.cell(row=count, column=8, value=unused)
# count加1,进入到下一行写入数据
count += 1
self.count = count
def main(self):
"""实现主要逻辑"""
# 创建Excel表对象,设置列名
self.ws = op.Workbook()
self.wb = self.ws.create_sheet(index=0)
self.wb.cell(row=1, column=1, value='服务器地址')
self.wb.cell(row=1, column=2, value='库名')
self.wb.cell(row=1, column=3, value='表名')
self.wb.cell(row=1, column=4, value='建表时间')
self.wb.cell(row=1, column=5, value='数据表总行数')
self.wb.cell(row=1, column=6, value='数据表总大小(MB)')
self.wb.cell(row=1, column=7, value='使用大小(MB)')
self.wb.cell(row=1, column=8, value='未使用大小(MB)')
self.count = 2
# 服务器列表,括号内为:服务器名、账号、密码
# 如果多个服务器用逗号隔开
list = [('.', 'sa', 'yuan427')]
for server in list:
server_name = server[0]
user_name = server[1]
password = server[2]
conn = pymssql.connect(server_name, user_name, password)
if conn:
print("连接成功!")
cursor = conn.cursor()
databases_name = self.get_databases_name(cursor)
self.save(databases_name, cursor, server_name)
# 所有服务器表插入完后保存
excel_name = "./本地数据库统计.xlsx"
self.ws.save(excel_name)
# 关闭游标,关闭数据库
cursor.close()
conn.close()
if __name__ == '__main__':
er = ErTransUtils()
er.main()脚本2
效果展示
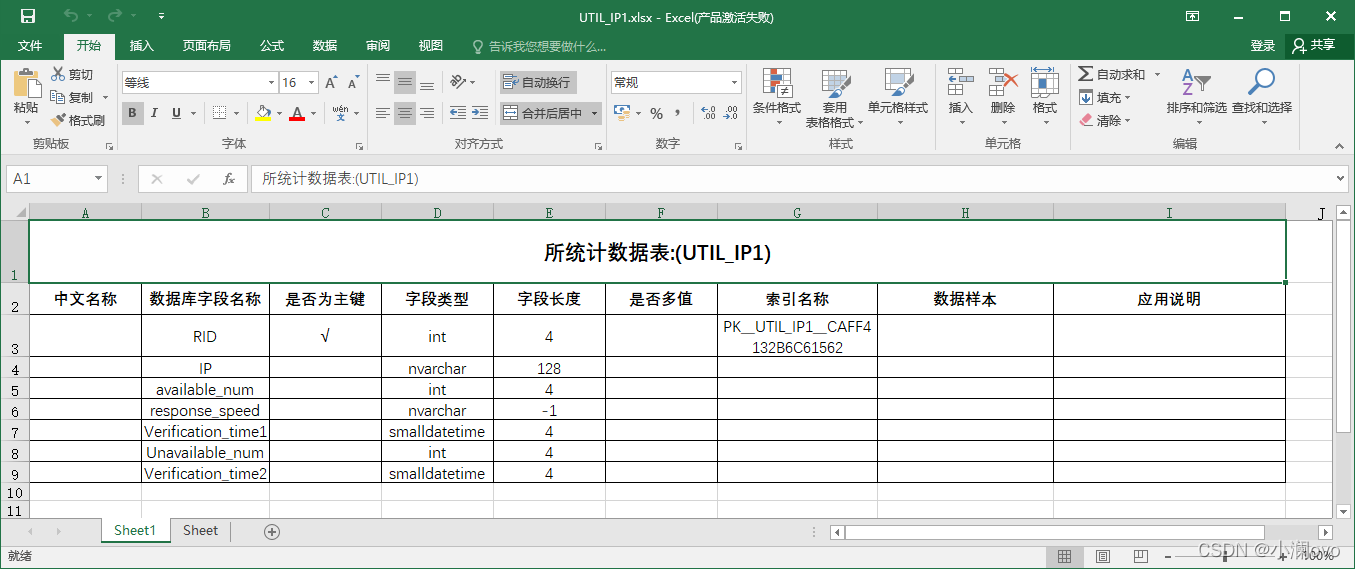
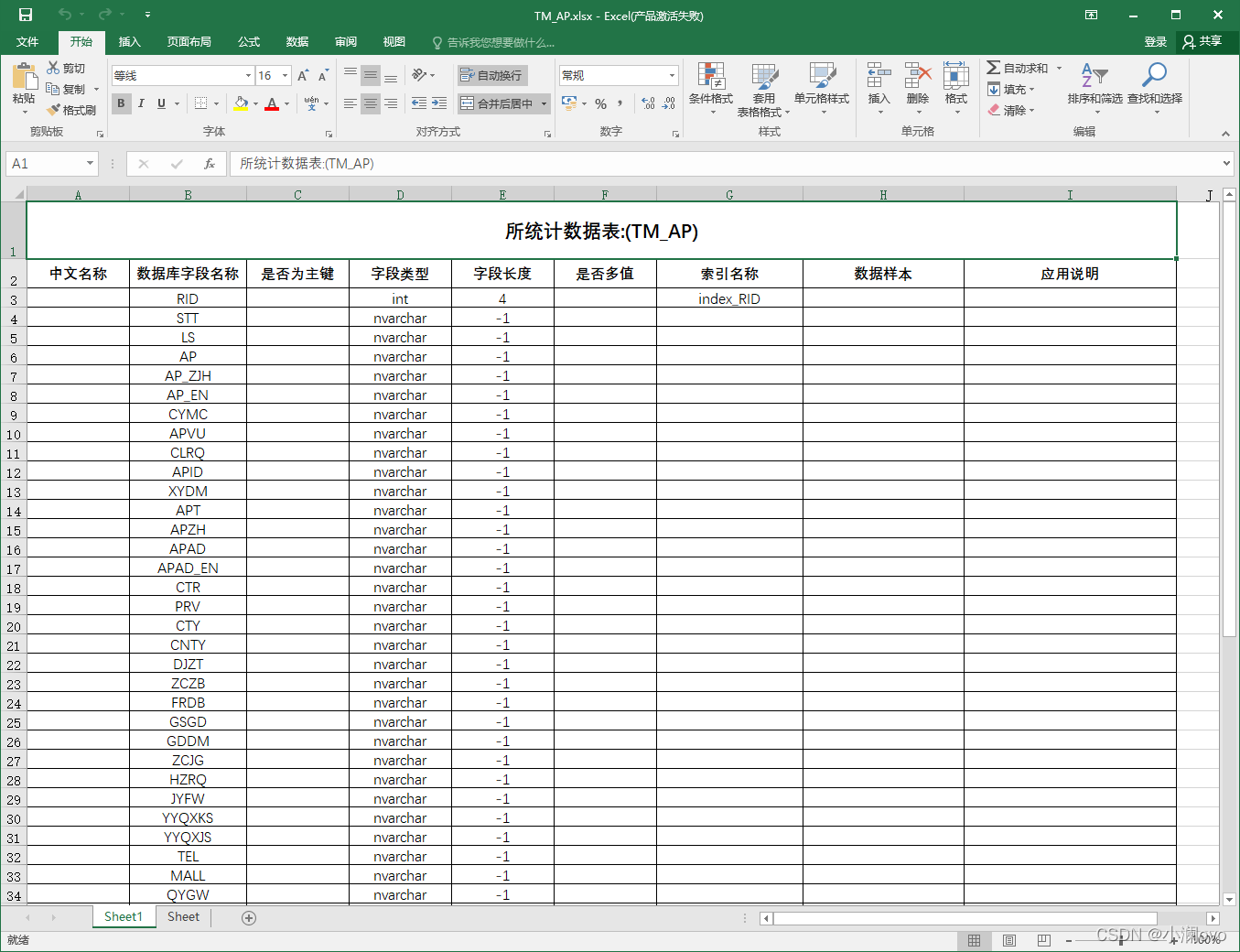
自动创建服务器文件夹,服务器文件夹下是所有库文件夹,库文件夹下是以表名命名的Excel文件名,文件中有表字段名称、是否为主键、字段类型、字段长度、索引名称等。
我本地的test库

表中字段信息如下,代码设置了Excel表格式,网格根据字段数量自动填充
代码解析
由于和第一个脚本相似只讲讲思路:
1.获取所有数据库名
2.获取库中所有表名,把库名和表名存放在元组内放入列表
如:[('test', 'student', 'UTIL_IP1', 'test4', 'test5', 'test6', 'TM_AP', 'test1', 'test2', 'test3', 'UTIL_IP')]第一个是库名其他都是表名
3.拼接获取字段信息的SQL,把库名、表名传进去,SQL能获取到的信息如下图(拼接的地方为上面的库名和红框那的表名):
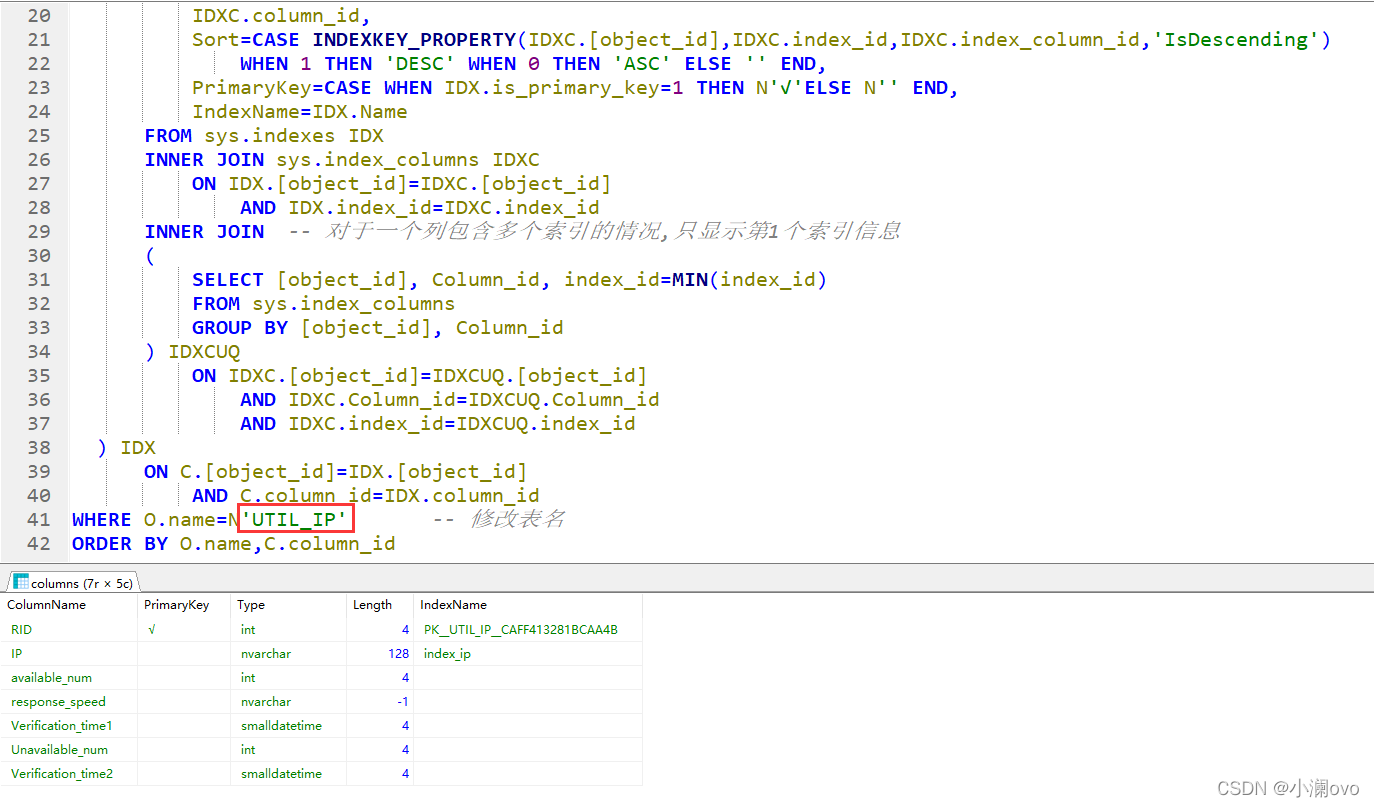
4.设置Excel内格式:字体、加粗、居中、合并、网格线、行高、列宽等
5.一个Excel文件保存完毕,生成另一个表的Excel文件,只到当前服务器下所有表统计完毕,才开始统计另一个服务器
完整代码
需要修改的地方只有服务器地址、账号、密码,每一个服务器信息放一个元组中;如果有多个服务器用逗号隔开
import pymssql
import openpyxl as op
from openpyxl.styles import Font, Alignment, Side, Border
import os
class ErTransUtils():
def get_databases_name(self, cursor):
"""获取服务器下所有库名"""
sql = 'SELECT * FROM sys.sysdatabases'
cursor.execute(sql)
rows = cursor.fetchall() # 逐行读取
# 存储
databases_name = []
for list in rows:
databases_name.append(list[0])
# 移除系统库和无用库
databases_name.remove("master")
databases_name.remove("model")
databases_name.remove("msdb")
databases_name.remove("tempdb")
try:
databases_name.remove("ReportServer")
databases_name.remove("ReportServerTempDB")
except Exception as e:
print(e)
# print(databases_name)
return databases_name
def get_tables_name(self, databases_name, cursor):
"""获取库中所有表名,并把对应的库名和表名存储在一起"""
item1 = [] # 存储
for i in databases_name:
sql = f'SELECT * FROM [{i}].sys.tables'
cursor.execute(sql)
rows = cursor.fetchall() # 逐行读取
item = []
for j in rows:
item.append(j[0])
item.insert(0, i)
item1.append(tuple(item))
return item1
def save(self, item1, cursor, server_name):
"""获取表中字段信息,并写入Excel"""
# 根据服务器名称创建目录
os.makedirs(server_name)
# databases_name:['master', 'tempdb', 'model', 'msdb', 'ReportServer', 'ReportServerTempDB', 'test']
# 取出每个库名
for database in item1:
# 根据库名名称创建目录
database1 = f'./{server_name}/{database[0]}'
os.makedirs(database1)
print('正在统计%s库' % database[0])
for table in range(1, len(database)):
sql = '''
USE [%s]
SELECT
ColumnName=C.name,
PrimaryKey=ISNULL(IDX.PrimaryKey,N''),
Type=T.name,
Length=C.max_length,
IndexName=ISNULL(IDX.IndexName,N'')
FROM sys.columns C
INNER JOIN sys.objects O
ON C.[object_id]=O.[object_id]
AND O.type='U'
AND O.is_ms_shipped=0
INNER JOIN sys.types T
ON C.user_type_id=T.user_type_id
LEFT JOIN -- 索引及主键信息
(
SELECT
IDXC.[object_id],
IDXC.column_id,
Sort=CASE INDEXKEY_PROPERTY(IDXC.[object_id],IDXC.index_id,IDXC.index_column_id,'IsDescending')
WHEN 1 THEN 'DESC' WHEN 0 THEN 'ASC' ELSE '' END,
PrimaryKey=CASE WHEN IDX.is_primary_key=1 THEN N'√'ELSE N'' END,
IndexName=IDX.Name
FROM sys.indexes IDX
INNER JOIN sys.index_columns IDXC
ON IDX.[object_id]=IDXC.[object_id]
AND IDX.index_id=IDXC.index_id
INNER JOIN -- 对于一个列包含多个索引的情况,只显示第1个索引信息
(
SELECT [object_id], Column_id, index_id=MIN(index_id)
FROM sys.index_columns
GROUP BY [object_id], Column_id
) IDXCUQ
ON IDXC.[object_id]=IDXCUQ.[object_id]
AND IDXC.Column_id=IDXCUQ.Column_id
AND IDXC.index_id=IDXCUQ.index_id
) IDX
ON C.[object_id]=IDX.[object_id]
AND C.column_id=IDX.column_id
WHERE O.name=N'%s' -- 修改表名
ORDER BY O.name,C.column_id
''' % (database[0], database[table])
# 执行sql语句
try:
cursor.execute(sql)
rows = cursor.fetchall() # 逐行读取
except Exception as e:
print(e)
# 存储
lists = []
for list in rows:
lists.append(list)
# 获取字段的行数,+2表示Excel的行数
excel_line = len(lists) + 2
# 加入count是为了换行写入数据
count = 3
wb = op.Workbook()
ws = wb.create_sheet(index=0)
table_name = f'所统计数据表:({database[table]})'
ws.cell(row=1, column=1, value=table_name)
ws.cell(row=2, column=1, value='中文名称')
ws.cell(row=2, column=2, value='数据库字段名称')
ws.cell(row=2, column=3, value='是否为主键')
ws.cell(row=2, column=4, value='字段类型')
ws.cell(row=2, column=5, value='字段长度')
ws.cell(row=2, column=6, value='是否多值')
ws.cell(row=2, column=7, value='索引名称')
ws.cell(row=2, column=8, value='数据样本')
ws.cell(row=2, column=9, value='应用说明')
# 整体格式
row_range = ws[1:excel_line]
for row in row_range:
for cell in row:
cell.font = Font(name="等线", size=12, bold=False, italic=False,
color="00000000") # name=字体名称,size=字体大小,bold=是否加粗,color=字体颜色
cell.alignment = Alignment(horizontal="center", vertical="center", wrap_text=True) # 字体上下左右居中
side1 = Side(style="thin", color="00000000")
side2 = Side(style="thin", color="00000000")
cell.border = Border(left=side1, right=side1, top=side2, bottom=side2) # 边框
# 设置列宽
ws.column_dimensions['A'].width = 14
ws.column_dimensions['B'].width = 16
ws.column_dimensions['C'].width = 14
ws.column_dimensions['D'].width = 14
ws.column_dimensions['E'].width = 14
ws.column_dimensions['F'].width = 14
ws.column_dimensions['G'].width = 20
ws.column_dimensions['H'].width = 22
ws.column_dimensions['I'].width = 29
# 单独设置应用说明列
column = f'I3:I{excel_line}'
font1 = ws[column]
for a in font1:
for a1 in a:
a1.alignment = Alignment(horizontal="left", vertical="justify", wrap_text=True)
# 设置第一行格式
ws.row_dimensions[1].height = 46.5 # 行高
ws.merge_cells('A1:I1') # 合并单元格
cell = ws["A1"]
cell.font = Font(name="等线", size=16, bold=True, italic=False,
color="00000000") # name=字体名称,size=字体大小,bold=是否加粗,color=字体颜色
# 设置第二行格式
ws.row_dimensions[2].height = 24 # 行高
font2 = ws['A2:I2']
for b in font2:
for b1 in b:
b1.font = Font(name="等线", size=12, bold=True, italic=False,
color="00000000") # name=字体名称,size=字体大小,bold=是否加粗,color=字体颜色
for i in lists:
# 要写入excel的数据
field_name = i[0]
key_name = i[1]
field_type = i[2]
field_length = i[3]
index_name = i[4]
# 将数据写入到下一行
ws.cell(row=count, column=2, value=field_name)
ws.cell(row=count, column=3, value=key_name)
ws.cell(row=count, column=4, value=field_type)
ws.cell(row=count, column=5, value=field_length)
ws.cell(row=count, column=7, value=index_name)
# count加1,进入到下一行写入数据
count += 1
excel_name = f'./{server_name}/{database[0]}/{database[table]}.xlsx'
wb.save(excel_name)
print('%s库统计完成' % database[0])
def main(self):
# 服务器列表
list = [('.', 'sa', 'yuan427')]
for server in list:
server_name = server[0]
user_name = server[1]
password = server[2]
conn = pymssql.connect(server_name, user_name, password)
if conn:
print("连接成功!")
cursor = conn.cursor()
databases_name = self.get_databases_name(cursor)
item1 = self.get_tables_name(databases_name, cursor)
print(item1)
self.save(item1, cursor, server_name)
# 关闭游标,关闭数据库
cursor.close()
conn.close()
if __name__ == '__main__':
er = ErTransUtils()
er.main()到此这篇关于使用Python实现ELT统计多个服务器下所有数据表信息的文章就介绍到这了,更多相关Python实现ELT统计内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!