
Pandas Groupby之在Python中汇总、聚合和分组数据的示例详解
作者:吃肉的小馒头
GroupBy是一个非常简单的概念,我们可以创建一个类别分组,并对这些类别应用一个函数,本文给大家介绍Pandas Groupby之如何在Python中汇总、聚合和分组数据,感兴趣的朋友跟随小编一起看看吧
GroupBy是一个非常简单的概念。我们可以创建一个类别分组,并对这些类别应用一个函数。这是一个简单的概念,但它是一种在数据科学中广泛使用的非常有价值的技术。在真实的的数据科学项目中,您将处理大量数据并一遍又一遍地尝试,因此为了提高效率,我们使用Groupby概念。Groupby概念非常重要,因为它能够有效地汇总、聚合和分组数据。
汇总
汇总包括统计,描述数据帧中存在的所有数据。我们可以使用describe()方法总结数据框中的数据。此方法用于从数据帧中获取min、max、sum、count值沿着该特定列的数据类型。
- describe():此方法详细说明数据类型及其属性。
dataframe_name.describe()
- unique():此方法用于从给定列中获取所有唯一值。
dataframe[‘column_name].unique()
- nunique():这个方法类似于unique,但它会返回唯一值的计数。
dataframe_name[‘column_name].nunique()
- info():此命令用于获取数据类型和列信息
- columns:此命令用于显示数据框中存在的所有列名
示例:
# importing pandas as pd for using data frame
import pandas as pd
# creating dataframe with student details
dataframe = pd.DataFrame({'id': [7058, 4511, 7014, 7033],
'name': ['sravan', 'manoj', 'aditya', 'bhanu'],
'Maths_marks': [99, 97, 88, 90],
'Chemistry_marks': [89, 99, 99, 90],
'telugu_marks': [99, 97, 88, 80],
'hindi_marks': [99, 97, 56, 67],
'social_marks': [79, 97, 78, 90], })
# display dataframe
dataframe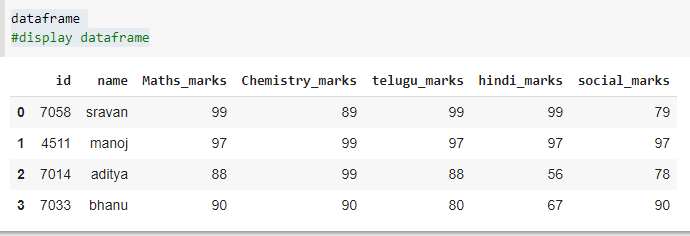
# describing the data frame
print(dataframe.describe())
print("-----------------------------")
# finding unique values
print(dataframe['Maths_marks'].unique())
print("-----------------------------")
# counting unique values
print(dataframe['Maths_marks'].nunique())
print("-----------------------------")
# display the columns in the data frame
print(dataframe.columns)
print("-----------------------------")
# information about dataframe
print(dataframe.info())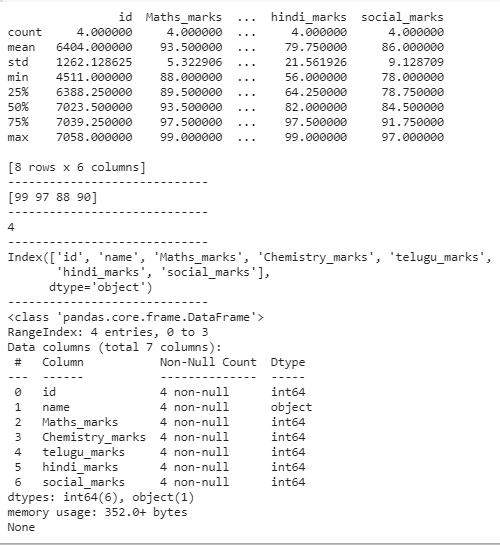
聚合
聚合用于获得数据帧中所有列或数据帧中特定列的均值、平均值、方差和标准差。
- sum():返回数据帧的和
dataframe[‘column].sum()
- mean():返回数据框中特定列的平均值
- std():返回该列的标准差。
- var():返回该列的方差
- min():返回列中的最小值
- max():返回列中的最大值
示例:
# importing pandas as pd for using data frame
import pandas as pd
# creating dataframe with student details
dataframe = pd.DataFrame({'id': [7058, 4511, 7014, 7033],
'name': ['sravan', 'manoj', 'aditya', 'bhanu'],
'Maths_marks': [99, 97, 88, 90],
'Chemistry_marks': [89, 99, 99, 90],
'telugu_marks': [99, 97, 88, 80],
'hindi_marks': [99, 97, 56, 67],
'social_marks': [79, 97, 78, 90], })
# display dataframe
dataframe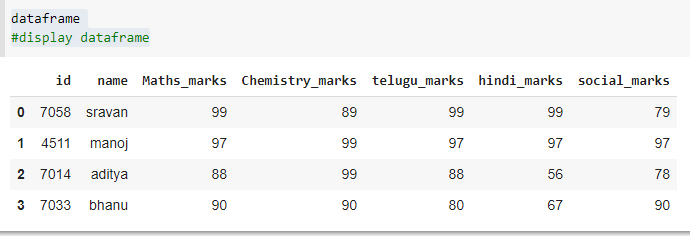
# getting all minimum values from
# all columns in a dataframe
print(dataframe.min())
print("-----------------------------------------")
# minimum value from a particular
# column in a data frame
print(dataframe['Maths_marks'].min())
print("-----------------------------------------")
# computing maximum values
print(dataframe.max())
print("-----------------------------------------")
# computing sum
print(dataframe.sum())
print("-----------------------------------------")
# finding count
print(dataframe.count())
print("-----------------------------------------")
# computing standard deviation
print(dataframe.std())
print("-----------------------------------------")
# computing variance
print(dataframe.var())
分组
它用于通过使用groupby()方法对数据帧中的一个或多个列进行分组。Groupby主要是指涉及以下步骤中的一个或多个的过程:
- 拆分:这是一个通过对数据集应用某些条件将数据拆分成组的过程。
- 应用:它是一个过程,在这个过程中,我们将一个函数独立地应用于每个组
- 组合:这是一个在应用groupby后将不同数据集组合在一起并生成数据结构的过程
# importing pandas as pd for using data frame
import pandas as pd
# creating dataframe with student details
dataframe = pd.DataFrame({'id': [7058, 4511, 7014, 7033],
'name': ['sravan', 'manoj', 'aditya', 'bhanu'],
'Maths_marks': [99, 97, 88, 90],
'Chemistry_marks': [89, 99, 99, 90],
'telugu_marks': [99, 97, 88, 80],
'hindi_marks': [99, 97, 56, 67],
'social_marks': [79, 97, 78, 90], })
# group by name
print(dataframe.groupby('name').first())
print("---------------------------------")
# group by name with social_marks sum
print(dataframe.groupby('name')['social_marks'].sum())
print("---------------------------------")
# group by name with maths_marks count
print(dataframe.groupby('name')['Maths_marks'].count())
print("---------------------------------")
# group by name with maths_marks
print(dataframe.groupby('name')['Maths_marks'])
import pandas as pd
# creating dataframe with student details
dataframe = pd.DataFrame({'id': [7058, 4511, 7014, 7033],
'name': ['sravan', 'manoj', 'aditya', 'bhanu'],
'Maths_marks': [99, 97, 88, 90],
'Chemistry_marks': [89, 99, 99, 90],
'telugu_marks': [99, 97, 88, 80],
'hindi_marks': [99, 97, 56, 67],
'social_marks': [79, 97, 78, 90], })
# group by name
print(dataframe.groupby('name').first())
print("------------------------")
# group by name with social_marks sum
print(dataframe.groupby('name')['social_marks'].sum())
print("------------------------")
# group by name with maths_marks count
print(dataframe.groupby('name')['Maths_marks'].count())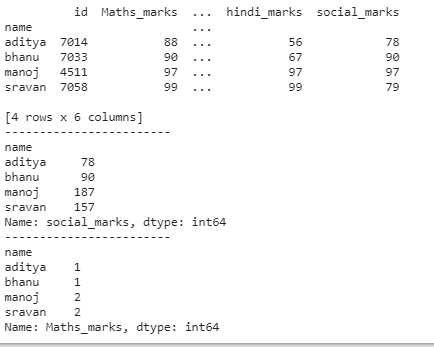
到此这篇关于Pandas Groupby之如何在Python中汇总、聚合和分组数据的文章就介绍到这了,更多相关Python汇总、聚合和分组数据内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!