
Python爬虫原理与基本请求库urllib详解
作者:打工人户户
一、网络爬虫是什么?
爬虫的定义:请求网站,并提取数据的自动化程序。
通过模拟浏览器,按照一定的规则,自动、大批量的获取网络资源,包括文本、图片、链接、音频、视频等等。
二、爬虫原理
(讲的就是如何获取网络资源的问题—怎么爬?要有尊严的爬,坐着就把数据优雅的爬下来)
1、发起请求:模拟浏览器向目标站点发送一个request,等待服务器响应;
2、获取响应内容:如果服务器能正常响应,会返回一个response,这便是所要获取的页面内容
3、解析内容:根据自己的需求,通过各种解析方法,将得到的内容进行解析
4、保存数据:存放于数据库或者保存为特定格式的文件
所以接下来本次我们要学习的内容就是以上这四个步骤了。
三、基本请求库urllib
这个库的作用呢,就是爬虫原理中的第一、二步,向目标网站发送请求用的。
本节内容:
- 用urllib抓取网页的基本语法
- 抓取需要输入关键词的网页
- 抓取需要登录密码的网页
- 抓取反爬机制的网页
- urllib异常处理
1、用urllib抓取网页的【基本语法】
有两种方法,一种是直接抓取,一种是直接将目标网址的网页信息保存到本地。
#无论哪种方法,先导包 import urllib.request
- 方法一:(常用) urllib.request.urlopen(url, data, timeout) 发送请求直接抓取
'''
urllib.request.urlopen(url, data, timeout) 发送request请求(3个参数不需都写,但必须有url)
url:目标网址
data:访问url时发送的数据包,默认为null
timeout:等待时长
'''
response = urllib.request.urlopen('http://www.baidu.com/')
# decode():解码,将字节流格式数据以相应的形式转化为字符串
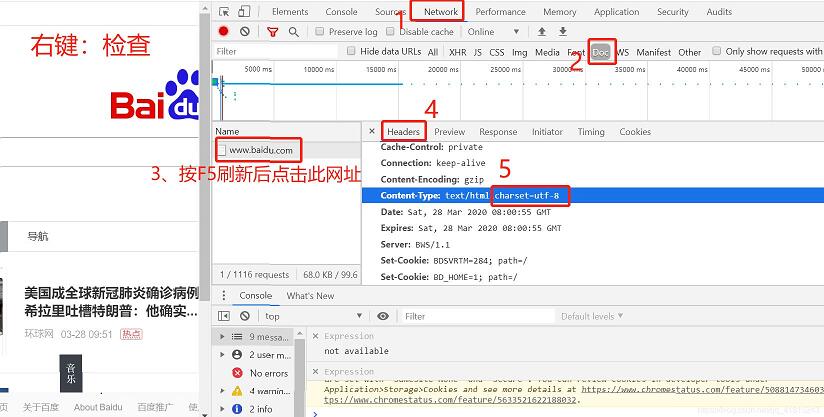
print(response.read().decode('utf-8'))通过urllib请求后得到的response打印如下:<http.client.HTTPResponse object at 0x000001DA07919608> 所以要先read()读取出来,但是给我的页面都是字节流数据,所以我们要在该网页源代码中找到其chartset,比如百度首页的编码格式就是utf-8,所以发送请求后,要拿到我们可读的网页就需要先read()再decode()解码。 具体如何找到目标网页的编码格式如下图:
- 方法二: urllib.request.urlretrieve(url,filename) 将目标网址网页信息保存到本地
'''
urllib.request.urlretrieve(url,filename) 直接将目标网址的网页信息保存到本地
filename:想保存到的路径文件名
然后用urllib.request.urlcleanup()清除缓存
'''
filename = urllib.request.urlretrieve('http://www.baidu.com/',filename='baidu.html')
urllib.request.urlcleanup()2. 抓取需要输入【关键词】的网页
背景:我想爬取目标网页上支持搜索关键词的网页所有相关信息,比如我想爬百度上所有python的信息,或者疫情的信息,或者其它的信息,如果每次都更换url那就太低效了。 分析网页url:目标网页是百度,//www.baidu.com/,输入python之后url有变化,发现//www.baidu.com/s?wd=python这个网址也能搜索到python的信息,找到规律,//www.baidu.com/s?wd=后面的词可以替换成任何词,都支持搜索,那么我们可以把这个词用input来输入得到,然后对url做一个拼接。 注意:发现//www.baidu.com/s?wd=后面的词不支持中文搜索,原因是网址中都是字节流的数据,所以如果我们要输入中文搜索的话,要将中文转为字节流格式。
# 定义关键词
keyword = input('输入你想查询的关键词:')
# 处理中文,进行编码,转成字节流格式
keyword = urllib.request.quote(keyword)
# url重构
url = 'http://www.baidu.com/s?wd='+keyword
response = urllib.request.urlopen(url).read()
# 保存到本地
f = open('baidu_search.html','wb') #wb存储字节流数据,所以上述response不需要用decode解码
f.write(response)
f.close()3. 抓取需要【登录密码】的网页
背景:需要爬取用户登录之后页面的数据, 这里有一个url供大家练习://www.iqianyue.com/mypost/ 该网页输入任何用户名和密码都能成功登录,下图为登录后的页面,也就是我们这次通过写程序要爬取的结果页面。

还记得urllib的基本语法吗?里面有3个参数,第二个是data,也就是我们传入的值,这里可以把用户名和密码跟着页面请求一起发送过去,但是要怎么做呢?首先要找到网页代码里是怎么设置用户名和密码的命名的(也就是字典里的key值)。
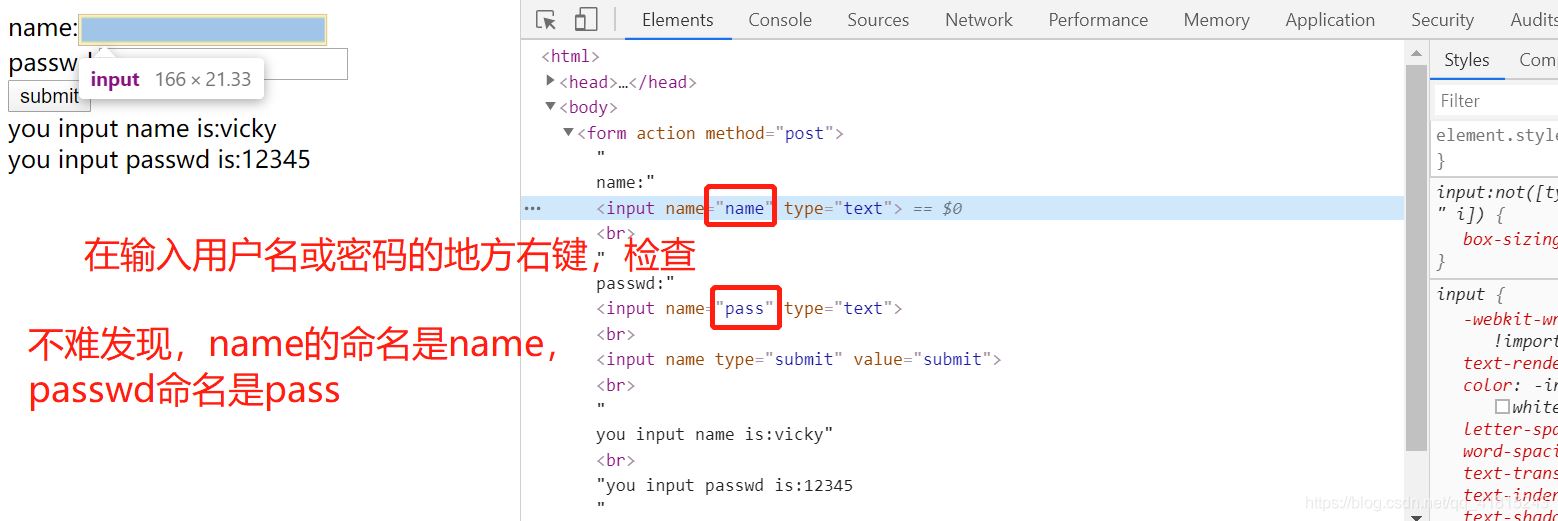
3.1 基础操作
import urllib.request
import urllib.parse #上传用户名和密码,需要先用parse模块进行编码处理
url = 'https://www.iqianyue.com/mypost/'
# urlencode():将上传的数据进行编码处理
# encode():将字符串转化为相应编码的字节流数据
postdata = urllib.parse.urlencode({
'name':'vicky',
'pass':'12345'
}).encode('utf-8')
response = urllib.request.urlopen(url,data=postdata).read()
# 保存网页
f = open('post.html','wb')
f.write(response)
f.close()运行成功后将post.html文件打开,鼠标点进去后右上角会显示各种浏览器,选择各自使用的浏览器打开页面,就会发现,出现的页面就是登录成功后的页面,跟上图一致。
3.2 设置cookie
背景:通过上述常规方法,可以模拟登录页面抓取该目标页面的资源,但也存在一种情况,这一步执行成功后,后续如果想抓取该网站的其它网页,用程序登录进去之后依然是无登录状态,浏览器并没有留下cookie。
【举个栗子】:
import urllib.request
import urllib.parse
# 主页面:'http://blog.chinaunix.net/'
# 登录页面:'http://account.chinaunix.net/login?url=http%3a%2f%2fblog.chinaunix.net'
# 登录跳转页面:'http://account.chinaunix.net/login/sso?url=http%3A%2F%2Fblog.chinaunix.net'
url = 'http://account.chinaunix.net/login/sso?url=http%3A%2F%2Fblog.chinaunix.net'
postdata = urllib.parse.urlencode({
'username':'***',
'password':'******'
}).encode('utf-8')
response = urllib.request.urlopen(url,postdata).read()
f = open('chinaunix.html','wb')
f.write(response)
f.close()拿这个网站举例,我选的url是登录跳转时的页面,顺利跳转后就进入到首页,如果我后续再写一个请求,直接访问该首页,登录进去发现还是无登录状态。 那么那么那么那么那么…
解决方案;
1、导入cookie处理模块 http.cookiejar
2、使用http.cookiejar.CookieJar()创建cookiejar对象
3、使用HTTPCookieProcessor创建cookie处理器,并以此为参数构建opener对象
4、加载为全局默认的opener
这样写,就把cookie贯穿整个网站的始终了,访问哪个页面都是登录状态。
import urllib.request
import urllib.parse
import http.cookiejar
url = 'http://account.chinaunix.net/login/sso?url=http%3A%2F%2Fblog.chinaunix.net'
postdata = urllib.parse.urlencode({
'username':'***',
'password':'***'
}).encode('utf-8')
response = urllib.request.urlopen(url,postdata).read()
# 创建cookiejar对象
cjar = http.cookiejar.CookieJar()
# 创建cookie处理器,并以此为参数构建opener对象
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cjar))
# 加载为全局默认的opener
urllib.request.install_opener(opener)
f = open('chinaunix_2.html','wb')
f.write(response)
f.close()4. 抓取【反爬机制】的网页
背景:因为有些网站也有一些反爬机制,所以你用上述语法进行常规的发送请求之后不一定能得到响应,,下面就讲述遇到反爬的网站我们应该怎么做。
对于反爬网页的对策有2点: headers:设置头部信息,将爬虫伪装成浏览器 proxy:设置代理,使用代理服务器并经常切换代理服务器
4.1 设置headers
— headers信息也在网页源代码中,找到User-Agent(headers里一般设置这个就行了),构建字典,把:后面的系统浏览器版本等信息全部复制粘贴进来,模拟浏览器登录。
— 发送请求前,要先构建一个Request请求对象,设置headers,再把请求对象传到urlopen中
import urllib.request
url = 'http://t.dianping.com/hangzhou'
# 构建headers
h = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
# 构建Request请求对象
request = urllib.request.Request(url=url, headers=h)
response = urllib.request.urlopen(request).read()
# 保存文件
f = open('headers.html','wb')
f.write(response)
f.close()4.2 设置proxy
也就是代理IP,在一定时间内频繁爬取某个网页可能会被封,所以可以使用一些代理IP来爬取资源。
import urllib.request
def use_Proxy(proxy_addr,url):
# ProxyHandler()设置对应的代理服务器信息
proxy = urllib.request.ProxyHandler({'http':proxy_addr})
# build_opener()创建一个自定义的opener对象
opener = urllib.request.build_opener(proxy)
# 将opener加载为全局使用的opener
urllib.request.install_opener(opener)
response = urllib.request.urlopen(url).read().decode('utf-8')
return response
proxy_addr = '183.146.213.157:80' # IP地址:端口号 自行百度“代理IP”
url = 'http://www.taobao.com'
print(len(use_Proxy(proxy_addr,url))) #随便打印一个长度,看看这个代理IP能否使用5. urllib异常处理
建立异常处理机制,反馈出错原因。
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://www.ijinqian.com')
except urllib.error.URLError as e:
print('发生异常--->'+str(e))到此这篇关于Python爬虫原理与基本请求库urllib详解的文章就介绍到这了,更多相关Python爬虫urllib库内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!