
macbook安装环境chatglm2-6b的详细过程
作者:淡淡的id
1、前言
chatglm安装环境还是比较简单的,比起Stable diffusion安装轻松不少。
安装分两部分,一是github的源码,二是Hugging Face上的模型代码;安装过程跟着官方的readme文档就能顺利安装。以下安装内容,绝大部分是官方readme内容
note1:执行默认你在conda环境下运行,我就不累赘了
note2:默认认为你会把里面模型路径改为你本地的路径
2、环境
系统:macOS Ventura(13.4.1)
芯片:m2
内存:16G
python版本:2.10.11
python虚拟环境:anconda
3、代码下载
note:默认各位已经安装好git、brew软件
3.1、下载运行模型的代码
逐行运行如下命令,克隆(git clone)代码、进入克隆好的目录、安装代码的python依赖
git clone https://github.com/THUDM/ChatGLM2-6B cd ChatGLM2-6B pip install -r requirements.txt
3.2、安装 Git Large File Storage
使用brew包管理软件git lfs,其他方式可参考前面的蓝色超链接
brew install git-lfs
输入如下命令,验证是否安装成功
git lfs install
输出Git LFS initialized.即为安装成功
3.3、下载模型
3.3.1、下载未量化模型
在运行模型代码以外目录,终端使用以下命令,会下载不包含lfs文件模型文件
git clone https://github.com/THUDM/ChatGLM2-6B cd ChatGLM2-6B pip install -r requirements.txt
这里假定你顺利克隆,不能克隆,你懂的,你可以访问网站THUDM/chatglm2-6b克隆完之后,是不包含lfs的实体文件的。此时需要,去chatglm2-6b清华网盘下载模型文件,将文件全部下载,并覆盖到模型下面。
3.3.2、下载int4未量化模型
在运行模型代码以外目录,终端使用以下命令,会下载不包含lfs文件模型文件
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm2-6b-int4
克隆完之后,是不包含lfs的实体文件的。此时需要,去chatglm2-6b-int4清华网盘下载模型文件,将文件全部下载,并覆盖到模型下面。
4、运行模型
4.1、安装mps
curl -O https://mac.r-project.org/openmp/openmp-14.0.6-darwin20-Release.tar.gz sudo tar fvxz openmp-14.0.6-darwin20-Release.tar.gz -C /
以下为项目FAQ引用
参考
https://mac.r-project.org/openmp/假设: gcc(clang)是14.x版本,其他版本见R-Project提供的表格此时会安装下面几个文件:/usr/local/lib/libomp.dylib,/usr/local/include/ompt.h,/usr/local/include/omp.h,/usr/local/include/omp-tools.h。注意:如果你之前运行ChatGLM项目失败过,最好清一下Hugging Face的缓存,i.e. 默认下是rm -rf ${HOME}/.cache/huggingface/modules/transformers_modules/chatglm-6b-int4。由于使用了rm命令,请明确知道自己在删除什么。
参考Accelerated PyTorch training on Mac,命令行输入:
python
mps_device = torch.device("mps")
x = torch.ones(1, device=mps_device)
print (x)进入python命令行,查看输出是否为tensor([1.], device='mps:0')确认是否支持mps,验证完毕关闭终端或者输入quit()退出
4.2、修改运行模型代码
mac只能使用本地的文件运行,所以我们用前面下载的模型路径,进行加载。加载模型的方式有多种,但是修改方式都是统一的,即修改tokenizer和model变量加载代码。未修改前:
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()模型修改后:
tokenizer = AutoTokenizer.from_pretrained("/Users/hui/data/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("/Users/hui/data/chatglm2-6b", trust_remote_code=True).half().to('mps')int4模型修改后【这里增加修复报错的两行代码】:
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
tokenizer = AutoTokenizer.from_pretrained("/Users/hui/data/chatglm2-6b-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("/Users/hui/data/chatglm2-6b-int4", trust_remote_code=True).float()4.3、加载模型的demo种类
按照readme描述,加载demo的方式有cli_demo.py、web_demo.py、web_demo2.py、api.py、openai_api.py这些方式运行模型并交互,你认真看项目会发现,我列的文件名差不多就项目的全部文件了。 这里还未调通前,建议使用cli_demo.py来测试,因为这个加载方式是最容易发现错误的模式,调通后,建议改web_demo2.py来玩耍。加载模型项目的文件下,命令行运行:
python cli_demo.py
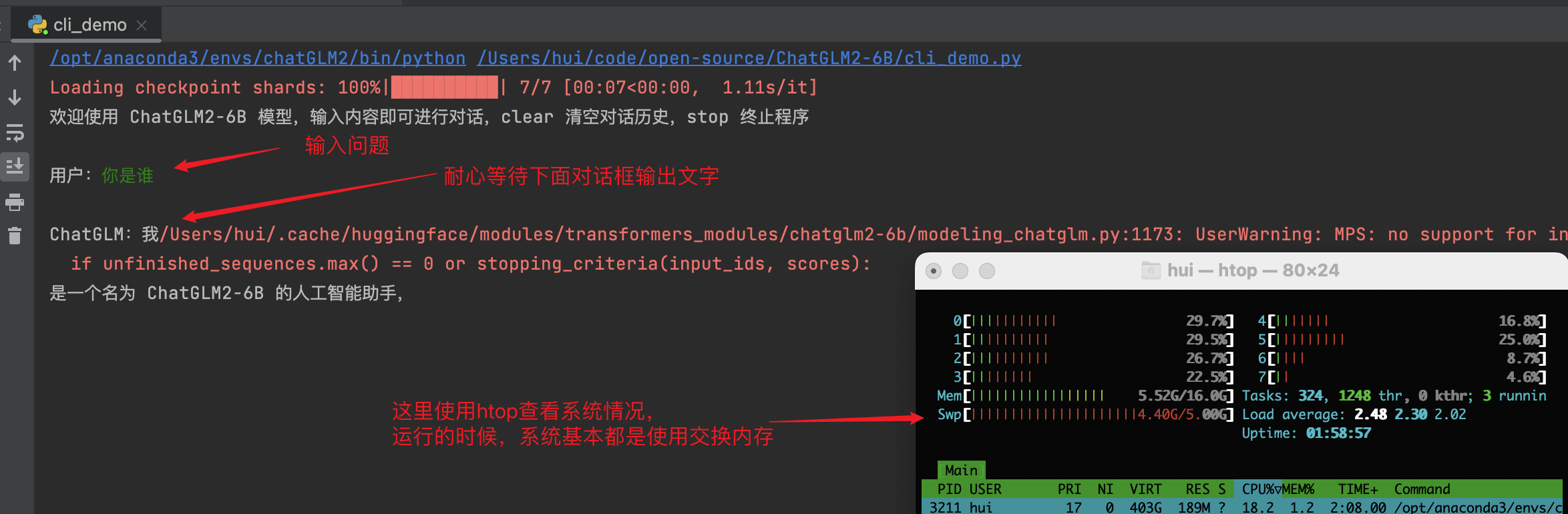
在用户行,输入问题,耐心等待输出的ChatGLM行输出答案,同时观察到系统是基本都是使用虚拟内存进行运行的,此时你的系统会很卡。这里是使用half方法情况下的内存情况,如果把half方法去掉,那么虚拟内存会到16G,输入问题的时候,你的8个cpu也会都使用率过半。
5、加载模型知识
加载模型都是方式都是一样,这里区别在于你加载模型在哪里运行,有cpu和gpu两种方式。这里总结下文档和网上看到一下方式。
5.1、gpu方式
gpu方式其实就是使用cuda()方法,即加载代码的结尾使用cuda(),使用gpu方式可以指定模型加载的进度,默认模型不指定的时候是16位浮点,可以在cuda()前面再用有参quantize()方法指定为8位或者4位。note:cuda肯定要求你是英伟达显卡啦,英伟达的技术例:
# 按需修改,目前只支持 4/8 bit 量化
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).quantize(8).cuda()5.2、cpu方式
cpu方式使用float()和to(‘mps’)进行指定,就不能使用quantize()指定了,会报错,可以使用half()进行指定,我也是尝鲜,所以不知道这个方法的用法,但是从表现来看,节省了一半以上的内存,但是只在to(‘mps’)上生效,float()加上没有效果,还是使用了19G虚拟内存。例:
model = AutoModel.from_pretrained("/Users/hui/data/chatglm2-6b", trust_remote_code=True).half().to('mps')5.3、使用压缩向量模型
官方提供4精度模型(即THUDM/chatglm2-6b-int4)运行,使用起来,的确快了不少,但是总体上来也是龟速。这个只是换了个小模型,同样可以用gpu和cpu加载起来
6、遇到的报错
报错1:
AssertionError: Torch not compiled with CUDA enabled
这事因为用了cuda()方法加载模型,报错意思是你的torch不是适配cuda编译的,但也不用更换,因为我的是mac,只有m2芯片,没有gpu,故不用折腾,使用上面提到的cpu方式加载即可
报错2:
OMP: Error #15: Initializing libomp.dylib, but found libomp.dylib already initialized.
这种情况是在int4模型加载才会出现,出现问题原因是系统中存在多个mps的环境。解决方式是加载时设置环境变量,加载前,加入如下代码:
import os os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
看意思就是允许多个动态库加载
报错3
Failed to load cpm_kernels:Unknown platform: darwin
THUDM/ChatGLM-6B/issues/6这里从issue回复看,没用到相关功能,不用理会即可。实际只有int4模型才会提示,而且也不影响使用。
报错4:
cannot import name 'COMMON_SAFE_ASCII_CHARACTERS' from 'charset_normalizer.constant'
是因为缺失了部分东西,重新安装即可。运行如下命令安装:
pip install chardet
报错5:
AttributeError: 'NoneType' object has no attribute 'int4WeightExtractionHalf'
这个报错int4模型下才会出现,解决方式就是改为float()方式运行解决
参考博客:
1、MAC安装ChatGLM-6B报错:Unknown platform: darwin
2、Python—OMP: Error #15: Initializing libomp.dylib, but found libiomp5.dylib already initialized.
3、cannot import name ‘COMMON_SAFE_ASCII_CHARACTERS‘ from ‘charset_normalizer.constant‘ ,已解决!
到此这篇关于macbook安装chatglm2-6b的文章就介绍到这了,更多相关macbook安装chatglm2-6b内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!