
python3中http协议提供文件服务器功能详解
作者:hsy12342611
http协议是互联网的通用基础协议,也可以利用其来开发文件服务器,给客户提供文件浏览,查看,下载,上传等功能,这篇文章主要介绍了python3中http协议提供文件服务器功能,需要的朋友可以参考下
http协议是互联网的通用基础协议,也可以利用其来开发文件服务器,给客户提供文件浏览,查看,下载,上传等功能。
1.python3自带http文件服务
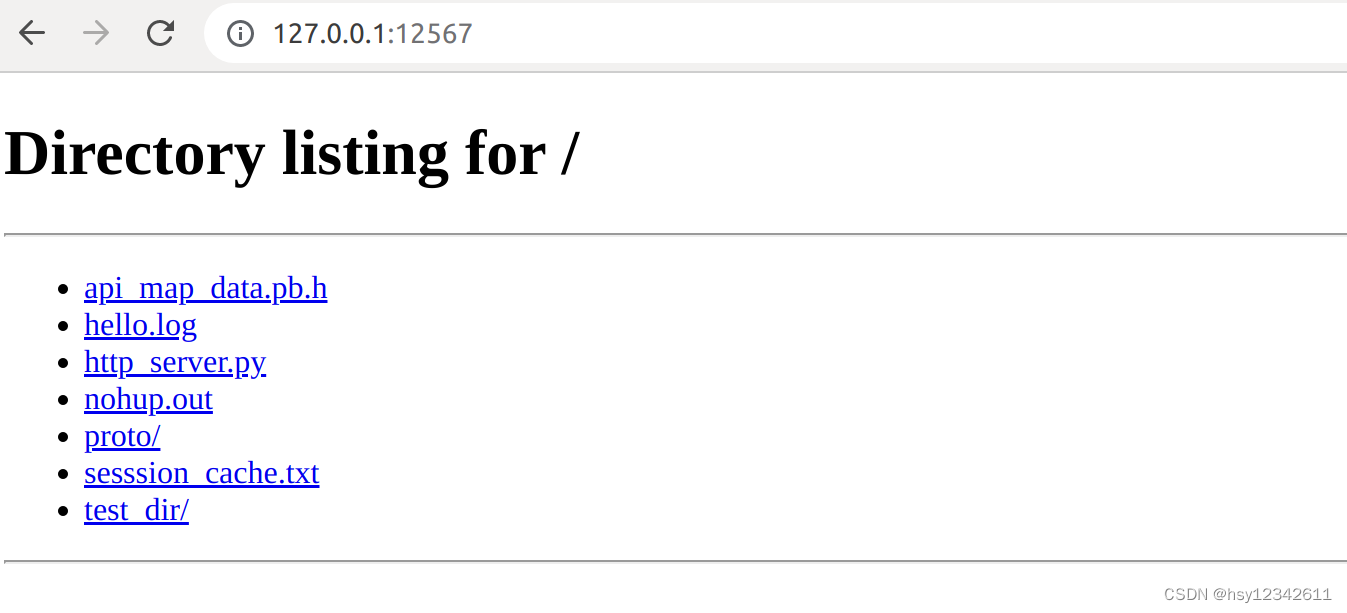
python3中http.server提供http文件服务,默认端口是8000,可以进行修改
运行命令:
python3 -m http.server 12567
另外python2中可以使用SimpleHTTPServer来提供http文件服务,默认端口是8000,ye可以进行修改
运行命令:
python -m SimpleHTTPServer 12567运行效果如下:

2.python3从头开发http文件服务
http_server.py
# -*- coding: UTF-8 -*-
import os, time
import sys, socket
import posixpath
#escape:逃跑,用来让特殊符号表示它本来的意思
try:
from html import escape
except ImportError:
from cgi import escape
import shutil
import mimetypes
import re
import signal
from io import StringIO, BytesIO
import codecs
from urllib.parse import quote
from urllib.parse import unquote
import urllib.parse
from http.server import HTTPServer
from http.server import BaseHTTPRequestHandler
"""urlencode quote unquote
urllib.parse.urlencode
urlencode函数,可以把key-value这样的键值对转换成我们想要的格式,返回的是a=1&b=2这样的字符串
urllib.parse.quote
quote对一个字符串进行urlencode转换
urllib.parse.unquote
unquote与quote对应,用来解码quote处理后的结果
"""
"""内存IO之StringIO和BytesIO
参考博客:
https://zhuanlan.zhihu.com/p/332651899
"""
"""HTTPServer
参考博客
https://www.cnblogs.com/jason-huawen/p/16241405.html
"""
"""
浏览器运行:
http://127.0.0.1:18081
"""
class MyHTTPRequestHandler(BaseHTTPRequestHandler):
address = socket.gethostbyname(socket.gethostname())
treefile = "sesssion_cache.txt"
mylist = []
myspace = ""
def do_GET(self):
"""处理GET请求
"""
print(MyHTTPRequestHandler.address)
paths = unquote(self.path)
path = str(paths)
print("path is ", paths, path)
'''
self.send_error(404, "File not found")
'''
if self.remove_dir_or_file(path):
return
fd = self.send_head()
if fd:
#关键代码: self.wfile用来向客户端写入数据
shutil.copyfileobj(fd, self.wfile)
if path == "/":
self.traversal_file(translate_path(self.path))
self.write_list(MyHTTPRequestHandler.treefile)
fd.close()
def do_HEAD(self):
"""处理HEAD请求
"""
fd = self.send_head()
if fd:
fd.close()
def do_POST(self):
"""处理POST请求
"""
r, info = self.deal_post_data()
#拼装HTML文本
f = BytesIO()
f.write(b'<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">')
f.write(b"<html>\n<title>Upload Result Page</title>\n")
f.write(b"<body>\n<h2>Upload Result Page</h2>\n")
f.write(b"<hr>\n")
if r:
f.write(b"<strong>Success:</strong><br>")
else:
f.write(b"<strong>Failed:</strong><br>")
for i in info:
print(r, i, "by: ", self.client_address)
f.write(i.encode('utf-8')+b"<br>")
f.write(b"<br><a href=\"%s\">back</a>" % self.headers['referer'].encode('ascii'))
f.write(b"</body>\n</html>\n")
length = f.tell()
f.seek(0)
self.send_response(200)
self.send_header("Content-type", "text/html;charset=utf-8")
self.send_header("Content-Length", str(length))
self.end_headers()
if f:
shutil.copyfileobj(f, self.wfile)
f.close()
#每次提交post请求之后更新目录树文件
self.p(translate_path(self.path))
self.write_list(MyHTTPRequestHandler.treefile)
def str_to_chinese(self,var):
not_end = True
while not_end:
start1 = var.find("\\x")
# print start1
if start1 > -1:
str1 = var[start1 + 2:start1 + 4]
print(str1)
start2 = var[start1 + 4:].find("\\x") + start1 + 4
if start2 > -1:
str2 = var[start2 + 2:start2 + 4]
start3 = var[start2 + 4:].find("\\x") + start2 + 4
if start3 > -1:
str3 = var[start3 + 2:start3 + 4]
else:
not_end = False
if start1 > -1 and start2 > -1 and start3 > -1:
str_all = str1 + str2 + str3
# print str_all
str_all = codecs.decode(str_all, "hex").decode('utf-8')
str_re = var[start1:start3 + 4]
# print str_all, " " ,str_re
var = var.replace(str_re, str_all)
# print var.decode('utf-8')
return var
def deal_post_data(self):
boundary = self.headers["Content-Type"].split("=")[1].encode('ascii')
print("boundary===", boundary)
remain_bytes = int(self.headers['content-length'])
print("remain_bytes===", remain_bytes)
res = []
line = self.rfile.readline()
while boundary in line and str(line, encoding = "utf-8")[-4:] != "--\r\n":
#line = self.rfile.readline()
remain_bytes -= len(line)
if boundary not in line:
return False, "Content NOT begin with boundary"
line = self.rfile.readline()
remain_bytes -= len(line)
print("line!!!",line)
fn = re.findall(r'Content-Disposition.*name="file"; filename="(.*)"', str(line))
if not fn:
return False, "Can't find out file name..."
path = translate_path(self.path)
fname = fn[0]
#fname = fname.replace("\\", "\\\\")
fname = self.str_to_chinese(fname)
print("------",fname)
fn = os.path.join(path, fname)
while os.path.exists(fn):
fn += "_"
print("!!!!",fn)
dirname = os.path.dirname(fn)
if not os.path.exists(dirname):
os.makedirs(dirname)
line = self.rfile.readline()
remain_bytes -= len(line)
line = self.rfile.readline()
# b'\r\n'
remain_bytes -= len(line)
try:
out = open(fn, 'wb')
except IOError:
return False, "Can't create file to write, do you have permission to write?"
pre_line = self.rfile.readline()
print("pre_line", pre_line)
remain_bytes -= len(pre_line)
print("remain_bytes", remain_bytes)
Flag = True
while remain_bytes > 0:
line = self.rfile.readline()
print("while line", line)
if boundary in line:
remain_bytes -= len(line)
pre_line = pre_line[0:-1]
if pre_line.endswith(b'\r'):
pre_line = pre_line[0:-1]
out.write(pre_line)
out.close()
res.append("File '%s' upload success!" % fn)
Flag = False
break
else:
out.write(pre_line)
pre_line = line
if pre_line is not None and Flag == True:
out.write(pre_line)
out.close()
res.append("File '%s' upload success!" % fn)
return True, res
def remove_dir_or_file(self, path):
plist = path.split("/", 2)
print("plist plist plist plist ", plist)
if len(plist) > 2 and plist[1] == "delete":
#路径转化
file = translate_path(plist[2])
print("======>>>>>>>>>> file", file)
if os.path.exists(file):
fdir = os.path.dirname(file)
print("======>>>>>>>>>> ", file, fdir)
#删除文件
os.remove(file)
if not os.listdir(fdir):
#删除目录
os.removedirs(fdir)
time.sleep(0.5)
# 0.5s后重定向
self.send_response(302)
self.send_header('Location', "/")
self.end_headers()
return True
print("======>>>>>>>>>> file not exists ", file)
return False
def send_head(self):
"""发送HTTP头
"""
path = translate_path(self.path)
if os.path.isdir(path):
if not self.path.endswith('/'):
# redirect browser - doing basically what apache does
self.send_response(301)
self.send_header("Location", self.path + "/")
self.end_headers()
return None
for index in "index.html", "index.htm":
index = os.path.join(path, index)
if os.path.exists(index):
path = index
break
else:
return self.list_directory(path)
print("=================================")
content_type = self.guess_type(path)
try:
# Always read in binary mode. Opening files in text mode may cause
# newline translations, making the actual size of the content
# transmitted *less* than the content-length!
f = open(path, 'rb')
except IOError:
self.send_error(404, "File not found")
return None
self.send_response(200)
self.send_header("Content-type", content_type)
fs = os.fstat(f.fileno())
self.send_header("Content-Length", str(fs[6]))
self.send_header("Last-Modified", self.date_time_string(fs.st_mtime))
self.end_headers()
return f
def list_directory(self, path):
"""Helper to produce a directory listing (absent index.html).
Return value is either a file object, or None (indicating an
error). In either case, the headers are sent, making the
interface the same as for send_head().
"""
try:
list_dir = os.listdir(path)
except os.error:
self.send_error(404, "No permission to list directory")
return None
list_dir.sort(key=lambda a: a.lower())
f = BytesIO()
display_path = escape(unquote(self.path))
f.write(b'<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">')
f.write(b"<html>\n<title>Directory listing for %s</title>\n" % display_path.encode('ascii'))
f.write(b"<body>\n<h2>Directory listing for %s</h2>\n" % display_path.encode('ascii'))
f.write(b"<hr>\n")
#上传目录
f.write(b"<h3>Directory Updating</h3>\n")
f.write(b"<form ENCTYPE=\"multipart/form-data\" method=\"post\">")
#@change=\"handleChange\" @click=\"handelClick\"
f.write(b"<input ref=\"input\" webkitdirectory multiple name=\"file\" type=\"file\"/>")
f.write(b"<input type=\"submit\" value=\"uploadDir\"/></form>\n")
f.write(b"<hr>\n")
#上传文件
f.write(b"<h3>Files Updating</h3>\n")
f.write(b"<form ENCTYPE=\"multipart/form-data\" method=\"post\">")
f.write(b"<input ref=\"input\" multiple name=\"file\" type=\"file\"/>")
f.write(b"<input type=\"submit\" value=\"uploadFiles\"/></form>\n")
f.write(b"<hr>\n")
#表格
f.write(b"<table with=\"100%\">")
f.write(b"<tr><th>path</th>")
f.write(b"<th>size(Byte)</th>")
f.write(b"<th>modify time</th>")
f.write(b"</tr>")
# 根目录下所有的内容
for name in list_dir:
# 根目录下的路径
fullname = os.path.join(path, name)
# 目录名/文件名
display_name = linkname = name
print("display_name ==> ", display_name)
if display_name.upper() == "HTTP_SERVER.PY":
continue
# 如果是文件夹的话
if os.path.isdir(fullname):
# 遍历文件夹
for root, dirs, files in os.walk(fullname):
# root 表示当前正在访问的文件夹路径
# dirs 表示该文件夹下的子目录名list
# files 表示该文件夹下的文件list
# 遍历文件
for fi in files:
print("########", os.path.join(root, fi))
display_name = os.path.join(root, fi)
#删除前面的xx个字符,取出相对路径
relativePath = display_name[len(os.getcwd()):].replace('\\','/')
st = os.stat(display_name)
fsize = st.st_size
fmtime = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(st.st_mtime))
f.write(b"<tr>")
f.write(b'<td><a href="%s" rel="external nofollow" rel="external nofollow" rel="external nofollow" >%s</a></td>' % (quote(relativePath).encode('utf-8'), escape(relativePath).encode('utf-8')))
f.write(b"<td>%d</td>" % fsize)
f.write(b"<td>%s</td>" % escape(fmtime).encode('ascii'))
f.write(b"<td><a href=\"/delete/%s\">delete</a>" % escape(relativePath).encode('utf-8'))
f.write(b"</tr>")
# 遍历所有的文件夹名字,其实在上面walk已经遍历过了
# for d in dirs:
# print(d)
# 如果是链接文件
elif os.path.islink(fullname):
linkname = linkname + "/"
print("real===", linkname)
display_name = name + "@"
# Note: a link to a directory displays with @ and links with /
f.write(b'<li><a href="%s" rel="external nofollow" rel="external nofollow" rel="external nofollow" >%s</a>\n' % (quote(linkname).encode('ascii'), escape(display_name).encode('ascii')))
else:
#其他直接在根目录下的文件直接显示出来
st = os.stat(display_name)
fsize = st.st_size
fmtime = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(st.st_mtime))
f.write(b"<tr>")
f.write(b'<td><a href="%s" rel="external nofollow" rel="external nofollow" rel="external nofollow" >%s</a></td>' % (quote(linkname).encode('utf-8'), escape(display_name).encode('utf-8')))
f.write(b"<td>%d</td>" % fsize)
f.write(b"<td>%s</td>" % escape(fmtime).encode('ascii'))
f.write(b"<td><a href=\"/delete/%s\">delete</a>" % escape(display_name).encode('utf-8'))
f.write(b"</tr>")
f.write(b"</table>")
f.write(b"\n<hr>\n</body>\n</html>\n")
length = f.tell()
f.seek(0)
self.send_response(200)
self.send_header("Content-type", "text/html;charset=utf-8")
self.send_header("Content-Length", str(length))
self.end_headers()
return f
def guess_type(self, path):
"""Guess the type of a file.
Argument is a PATH (a filename).
Return value is a string of the form type/subtype,
usable for a MIME Content-type header.
The default implementation looks the file's extension
up in the table self.extensions_map, using application/octet-stream
as a default; however it would be permissible (if
slow) to look inside the data to make a better guess.
"""
base, ext = posixpath.splitext(path)
if ext in self.extensions_map:
return self.extensions_map[ext]
ext = ext.lower()
if ext in self.extensions_map:
return self.extensions_map[ext]
else:
return self.extensions_map['']
if not mimetypes.inited:
mimetypes.init() # try to read system mime.types
extensions_map = mimetypes.types_map.copy()
extensions_map.update({
'': 'application/octet-stream', # Default
'.py': 'text/plain',
'.c': 'text/plain',
'.h': 'text/plain',
})
def traversal_file(self, url):
print("url:", url)
files = os.listdir(r''+url)
for file in files:
myfile = url + "//" + file
size = os.path.getsize(myfile)
if os.path.isfile(myfile):
MyHTTPRequestHandler.mylist.append(str(MyHTTPRequestHandler.myspace)+"|____"+file +" "+ str(size)+"\n")
if os.path.isdir(myfile) :
MyHTTPRequestHandler.mylist.append(str(MyHTTPRequestHandler.myspace)+"|____"+file + "\n")
#get into the sub-directory,add "| "
MyHTTPRequestHandler.myspace = MyHTTPRequestHandler.myspace+"| "
self.traversal_file(myfile)
#when sub-directory of iteration is finished,reduce "| "
MyHTTPRequestHandler.myspace = MyHTTPRequestHandler.myspace[:-5]
def get_all_file_list(self):
listofme = []
for root, dirs, files in os.walk(translate_path(self.path)):
files.sort()
for fi in files:
display_name = os.path.join(root, fi)
#删除前面的XXX个字符,取出相对当前目录的路径
relativePath = display_name[len(os.getcwd()):].replace('\\','/')
st = os.stat(display_name)
fsize = st.st_size
fmtime = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(st.st_mtime))
listofme.append(relativePath+"\t")
listofme.append(str(fsize)+"\t")
listofme.append(str(fmtime)+"\t\n")
return listofme
def write_list(self,url):
f = open(url,'w')
f.write("http://"+str(MyHTTPRequestHandler.address)+":8001/ directory tree\n")
MyHTTPRequestHandler.mylist.sort()
f.writelines(MyHTTPRequestHandler.mylist)
f.write("\nFile Path\tFile Size\tFile Modify Time\n")
f.writelines(self.get_all_file_list())
MyHTTPRequestHandler.mylist = []
MyHTTPRequestHandler.myspace = ""
f.close()
print("write_list end")
def translate_path(path):
path = path.split('?', 1)[0]
path = path.split('#', 1)[0]
path = posixpath.normpath(unquote(path))
words = path.split('/')
words = filter(None, words)
path = os.getcwd()
for word in words:
drive, word = os.path.splitdrive(word)
head, word = os.path.split(word)
if word in (os.curdir, os.pardir):
continue
path = os.path.join(path, word)
return path
def signal_handler(signal, frame):
print(signal, frame)
exit()
def main():
print('python version:', sys.version_info.major, sys.version_info.minor)
if sys.argv[1:]:
port = int(sys.argv[1])
else:
port = 18081
#server_address = ('', port)
address = ('127.0.0.1', port)
signal.signal(signal.SIGINT, signal_handler)
signal.signal(signal.SIGTERM, signal_handler)
signal.signal(signal.SIGQUIT, signal_handler)
#忽略ctrl+z:SIGTSTP(挂起信号)
signal.signal(signal.SIGTSTP, signal.SIG_IGN)
server = HTTPServer(address, MyHTTPRequestHandler)
server_info = server.socket.getsockname()
print("server info: " + str(server_info[0]) + ", port: " + str(server_info[1]) + " ...")
server.serve_forever()
def test_url_code():
values = {'username': 'hello 你好', 'password': 'pass'}
data = urllib.parse.urlencode(values)
print("data = ", data)
name = '狄仁杰'
name = urllib.parse.quote(name)
print("name = ", name)
dname = urllib.parse.unquote(name)
print("dname = " + dname)
if __name__ == '__main__':
test_url_code()
main()运行效果如下:

到此这篇关于python3中http协议提供文件服务器功能详解的文章就介绍到这了,更多相关python3 http文件服务器内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!