
Pytorch中关于RNN输入和输出的形状总结
作者:会唱歌的猪233
Pytorch对RNN输入和输出的形状总结
个人对于RNN的一些总结。
RNN的输入和输出
RNN的经典图如下所示
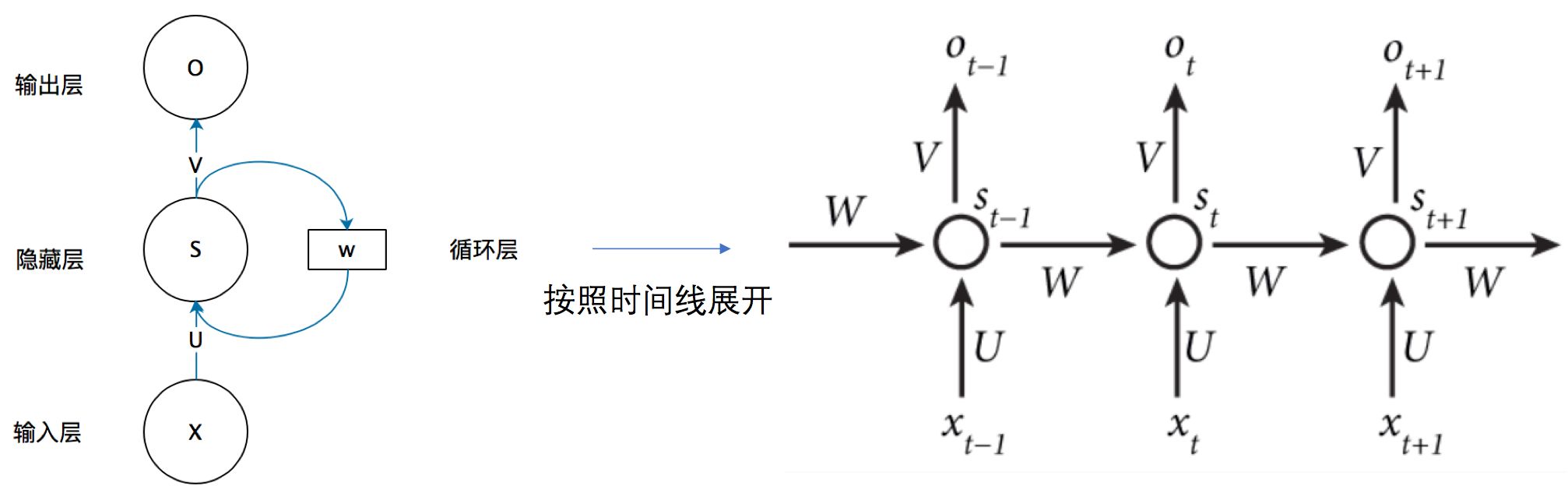
各个参数的含义
- Xt: t时刻的输入,形状为[batch_size, input_dim]。对于整个RNN来说,总的X输入为[seq_len, batch_size, input_dim],具体如何理解batch_size和seq_len在下面有说明。
- St: t时刻隐藏层的状态,也有时用ht表示,形状为[batch_size, hidden_size],St=f(U·Xt+W·St-1),通过W和U矩阵的映射,将embedding后的Xt和上一状态St-1转为St
- Ot: t时刻的输出,Ot=g(V·St),形状为[batch_size, hidden_size],总的为输出O为[seq_len, batch_size, hidden_size]
Pytorch中的使用
Pytorch中RNN函数如下
RNN的主要参数如下
nn.RNN(input_size, hidden_size, num_layers=1, bias=True)
参数解释
input_size: 输入特征的维度,一般rnn中输入的是词向量,那么就为embedding-dimhidden_size: 隐藏层神经元的个数,或者也叫输出的维度num_layers: 隐藏层的个数,默认为1
output=输出O, 隐藏状态St,其中输出O=[time_step, batch_size, hidden_size],St为t时刻的隐藏层状态
理解RNN中的batch_size和seq_len
深度学习中采用mini-batch的方法进行迭代优化,在CNN中batch的思想较容易理解,一次输入batch个图片,进行迭代。但是RNN中引入了seq_len(time_step), 理解较为困难,下面是我自己的一些理解。
首先假如我有五句话,作为训练的语料。
sentences = ["i like dog", "i love coffee", "i hate milk", "i like music", "i hate you"]
那么在输入RNN之前要先进行embedding,比如one-hot encoding,容易得到这里的embedding-dim为9.
那么输入的sentences可以表示为如下方式
| t=0 | t=1 | t=2 | |
|---|---|---|---|
| batch1 | i | like | dog |
| batch2 | i | love | coffee |
| batch3 | i | hate | milk |
| batch4 | i | like | music |
| batch5 | i | hate | you |
那么在RNN的训练中。
- t=0时, 输入第一个batch[i, i, i, i, i]这里用字符表示,其实应该是对应的one-hot编码。
- t=1时,输入第二个batch[like, love, hate, like, hate]
- t=2时,输入第三个batch[dog, coffee, milk, music, you]
那么对应的时间t来说,RNN需要对先后输入的batch_size个字符进行前向计算迭代,得到输出。
Pytorch双向RNN隐藏层和输出层结果拆分
1 RNN隐藏层和输出层结果的形状
从Pytorch官方文档可以得到,对于批量化输入的RNN来讲,其隐藏层的shape为(num_directions*num_layers, batch_size, hidden_size)。

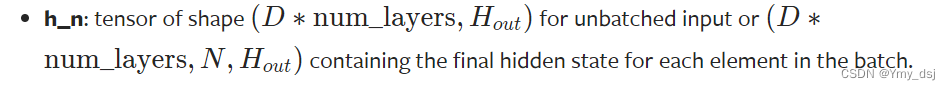
其输出的shape为(seq_len, batch_size, D*hidden_size)。

2 双向RNN情况下,隐藏层和输出层结果拆分
当采用双向RNN时,其输出的结果包含正向和反向两个方向输出的结果。
2.1 输出层结果拆分
其中对于输出output来讲,从官方文档我们可以得到,其拆分正向和反向两个方向结果的方法为:
output.shape = (seq_len, batch_size, num_directions*hidden_size)
output.view(seq_len, batch, num_directions, hidden_size)
其中,对于(num_directions)方向维度,正向和反向的维度值分别为0和1。

2.2 隐藏层结果拆分
而对于隐藏层,包括初始值h_0以及最终输出h_n,也都包含两个方向的隐藏状态,但是其拆分方式跟输出层不一样。
方法如下:
h_0, h_n.shape = (num_directions*num_layers, batch_size, hidden_size)
h_0, h_n.view(num_layers, num_directions, batch_size, hidden_size)
可以从简单单层双向RNN的输出结果来验证,此时RNN的输出结果与最后一层的隐藏层结果是一样的。
import torch
import torch.nn as nn
if __name__ == "__main__":
# input_size: 3, hidden_size: 5, num_layers: 3
BiRNN_Net = nn.RNN(3, 5, 3, bidirectional=True, batch_first=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# batch_size: 1, seq_len: 1, input_size: 3
inputs = torch.zeros(1, 1, 3, device=device)
# state: (num_directions*num_layers, batch_size, hidden_size)
state = torch.randn(6, 1, 5, device=device)
BiRNN_Net.to(device)
output, hidden = BiRNN_Net(inputs, state)
output_re = output.reshape((1, 1, 2, 5))
hidden_re = hidden.reshape((3, 2, 1, 5))
print(output)
print(output_re)
print(hidden)
print(hidden_re)输出结果可以看出,隐藏层的结果是优先num_layers网络层数这一个维度来构成的。
tensor([[[ 0.3939, -0.9160, 0.5054, 0.2949, -0.5225, 0.0533, 0.4197, -0.7200, -0.1262, -0.7975]]], device='cuda:0', grad_fn=<CudnnRnnBackward0>) tensor([[[[ 0.3939, -0.9160, 0.5054, 0.2949, -0.5225], [ 0.0533, 0.4197, -0.7200, -0.1262, -0.7975]]]], device='cuda:0', grad_fn=<ReshapeAliasBackward0>) tensor([[[-0.2606, 0.5410, -0.2663, 0.6418, -0.2902]], [[ 0.1367, 0.7222, -0.3051, -0.6410, -0.3062]], [[ 0.2433, 0.3287, -0.4809, -0.1782, -0.5582]], [[ 0.4824, -0.8529, 0.7604, 0.8508, -0.1902]], [[ 0.3939, -0.9160, 0.5054, 0.2949, -0.5225]], [[ 0.0533, 0.4197, -0.7200, -0.1262, -0.7975]]], device='cuda:0', grad_fn=<CudnnRnnBackward0>) tensor([[[[-0.2606, 0.5410, -0.2663, 0.6418, -0.2902]], [[ 0.1367, 0.7222, -0.3051, -0.6410, -0.3062]]], [[[ 0.2433, 0.3287, -0.4809, -0.1782, -0.5582]], [[ 0.4824, -0.8529, 0.7604, 0.8508, -0.1902]]], [[[ 0.3939, -0.9160, 0.5054, 0.2949, -0.5225]], [[ 0.0533, 0.4197, -0.7200, -0.1262, -0.7975]]]], device='cuda:0', grad_fn=<ReshapeAliasBackward0>)
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。