
如何利用itertuples对DataFrame进行遍历
作者:幸运的Alina
这篇文章主要介绍了如何利用itertuples对DataFrame进行遍历问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教
用itertuples对DataFrame进行遍历
最近在做推荐系统实践的时候需要生成物品同现矩阵和用户物品矩阵,发现了对DataFrame对象进行遍历很方便的函数itertuples
与此相关的有如下:
iterrows(): 将DataFrame迭代成(index ,series)iteritems():将DataFrame迭代成(列名,series)itertuples():将DataFrame迭代成元组
示例如下:
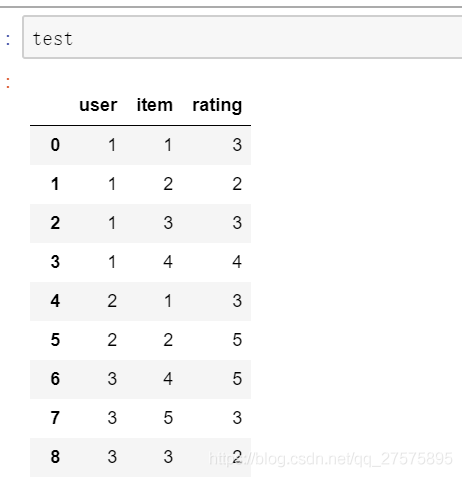
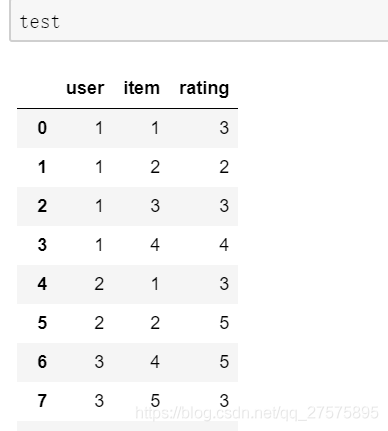
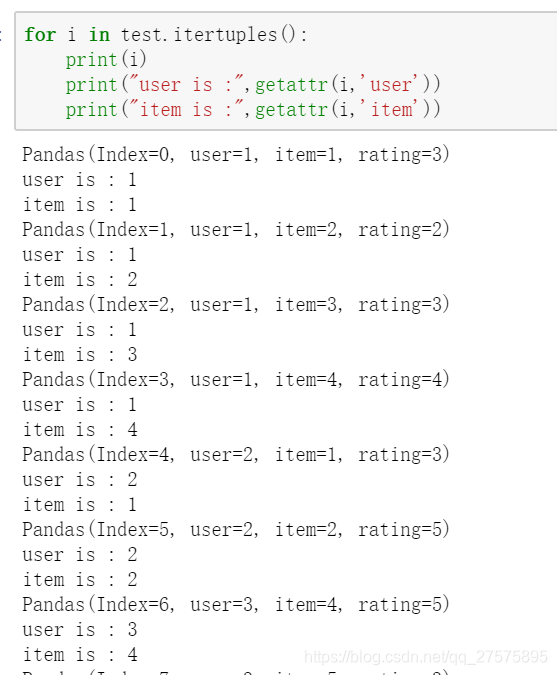
通过getattr()函数可以直接获取元组内指定的值
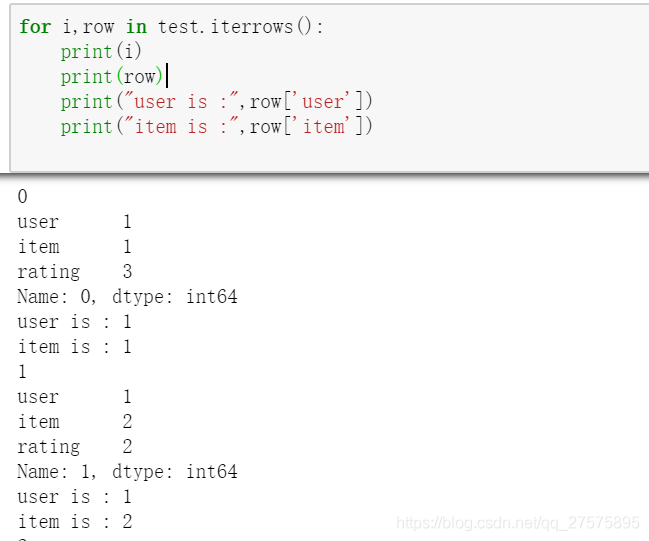
这里通过列明索引访问对应的值
这里通过Index 索引获取对应的值
Pandas——Dataframe行遍历几种常用方法性能分析
pandas作为python数据分析的一大利器,为广大数据分析人员使用。无意中,听到美女同事吐槽:dataframe好慢啊!嗯哼,瞬间引起了我这个数据人的注意,过去一看,原来是用的方法本身效率低。
日常工作中,按照行遍历数据是我们一个非常常见的场景!尤其是从sql boy转到数据分析的我,动不动就想
select * from table1;
一下,看看数据的大概情况。这一操作在pandas中的实现主要有一下几种:
1、iterrows()
原理是将Dataframe迭代为Series,再返回结果。这一过程中需要进行类型检查,所以,会花费很长的时间。(不建议使用)
for index, row in df.iterrows(): #字典方式访问 print(index, row['c1'], row['c2'])
2、itertuples()
原理是将Dataframe迭代为tuple,再进行返回,由于元组不可变的特性,此过程不需要进行类型检查。(效率高,推荐使用)
for row in student.itertuples(): # print(row) print(row.Index, row.name, row.account, row.pwd) print(row.Index, getattr(row,'name'), getattr(row,'account'), getattr(row,'pwd'))
3、for + zip
这种方法是直接手动构造原生tuple,无需关心index数据。(效率高,推荐使用)
for A, B in zip(df['A'], df['B']): print(A, B)
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。