
python爬虫将js转化成json实现示例
作者:ponponon
这篇文章主要为大家介绍了python爬虫将js转化成json实现示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪
正文
有一个优秀的库可以使用————demjson
示范链接
http://fcd.5173.com/commondat...
请求上面链接,会得到如下图的一个js文件

我们需要把这个js文件转成为dict,方便提取其中需要的字段(这在爬虫任务中非常常见)
失败的方法
传统方法
通常转js文件为dict的过程:
1.先通过切片掐头去尾,去掉头部的 “callarea(” 和尾部的 “)” 。
2.再次导入json这个库,使用loads,json.loads(resposne.text[9:-1]),实现json转dict。
但是,这个方法在这里行不通。
import requests
import json
url = 'http://fcd.5173.com/commondata/Category.aspx?type=area&cache=&id=20c8bbc1b9794fc98bd96859624d4769&jsoncallback=callarea'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36',
}
resposne = requests.get(url, headers=headers)
print(json.loads(resposne.text[9:-1]))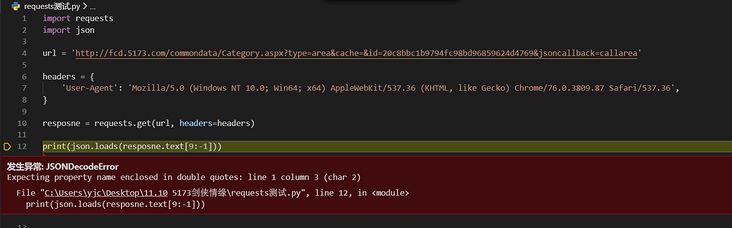
错误原因
js文件并不一定是json的超集,这此处的js文件key不包含双引号,value中的内容是单引号。
上诉方法行得通的前提是这个js需要时json的超集,key和value都由双引号包围。
天无绝人之路
通过demjson可以一步到位
import requests
import demjson
url = 'http://fcd.5173.com/commondata/Category.aspx?type=area&cache=&id=20c8bbc1b9794fc98bd96859624d4769&jsoncallback=callarea'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36',
}
resposne = requests.get(url, headers=headers)
for item in demjson.decode(resposne.text[9:-1]):
id = item.get('id')
name = item.get('name')
print(id, name)得到如下结果
写代码千万不要睡着了
以上就是python爬虫将js转化成json实现示例的详细内容,更多关于python将js转化成json的资料请关注脚本之家其它相关文章!