
Java优先队列PriorityQueue超全解析
作者:Porunarufu
一、基本定义与特性
- 本质:PriorityQueue 是 Java 集合框架中 Queue 接口的实现类,基于堆(Heap) 数据结构实现(默认是最小堆),底层通过数组存储元素。
- 核心特性:
- 队列中的元素会按照优先级顺序出队,而非先进先出(FIFO);
- 不允许存储
null元素; - 非线程安全,多线程场景需使用
PriorityBlockingQueue; - 容量可自动扩容(默认初始容量为 11,扩容规则:容量 < 64 时翻倍,≥64 时扩容 50%);
- 迭代器遍历的结果不保证有序,仅出队(
poll()/remove())时保证优先级顺序。
二、关于堆
| 堆的核心维度 | 具体内容 |
| 定义 | 完全二叉树结构,满足 “堆序性”:- 最小堆:任意节点值 ≤ 其子节点值(根节点为全局最小值);- 最大堆:任意节点值 ≥ 其子节点值(根节点为全局最大值)。 |
| 存储结构 | 基于数组实现(利用完全二叉树的特性):- 根节点:数组索引 0;- 索引 i 的节点 → 左子节点 2i+1、右子节点 2i+2、父节点 (i-1)/2(整数除法);- 无需连续存储空节点,空间利用率高。 |
| 核心操作 | 1. 插入(siftUp / 向上调整):新元素插入数组尾部,从下往上对比父节点,不满足堆序性则交换,直到堆序性恢复(时间复杂度 O (log n));2. 删除堆顶(siftDown / 向下调整):移除根节点,将数组最后一个元素移到根节点,从上往下对比子节点,不满足堆序性则交换(选更小 / 更大的子节点),直到堆序性恢复(时间复杂度 O (log n));3. 堆化(heapify):将无序数组转换为堆结构,从最后一个非叶子节点(索引 size/2 - 1)开始,逐个执行 siftDown(时间复杂度 O (n))。 |
| 特性 | - 仅能高效获取 / 删除堆顶元素(优先级最高);- 遍历无序(完全二叉树的特性决定,仅堆顶有序);- 支持动态扩容(数组满时扩容,规则由实现决定)。 |
1.优先级规则 ↔ 堆的类型
- PriorityQueue默认实现最小堆:依赖元素的
Comparable接口(compareTo()定义自然顺序),本质是维护最小堆的堆序性; - 自定义优先级(如最大堆):传入
Comparator比较器,本质是修改堆的 “堆序性判断逻辑”,例如:
// 最大堆:Comparator修改siftUp/siftDown的比较规则,让父节点≥子节点 PriorityQueue<Integer> maxHeap = new PriorityQueue<>((a, b) -> b - a);
- 异常根源:若元素未实现
Comparable且无Comparator,堆序性无法判断,运行时抛ClassCastException。
2. 存储结构 ↔ 堆的数组存储
- PriorityQueue 底层直接复用堆的数组存储逻辑:
- 初始容量 11(数组初始长度),扩容规则:容量 < 64 时翻倍,≥64 时扩容 50%(堆的数组存储需要连续空间,扩容是为了满足堆的动态插入);
- 空队列时数组为默认空数组,添加第一个元素时初始化长度为 11。
3. 核心方法 ↔ 堆的核心操作
PriorityQueue 的所有核心方法,本质都是调用堆的插入 / 删除 / 堆化操作:

堆的存储是基于数组的完全二叉树映射—— 利用完全二叉树 “层序排列无空洞” 的特性,将树节点按层序顺序存入数组,无需额外存储指针(如链式存储),空间效率和索引计算效率极高,这也是 Java PriorityQueue 底层选择数组存储堆的核心原因。
4.存储核心原理
- 为什么选数组?堆的本质是完全二叉树(除最后一层外,每一层节点数都满;最后一层节点靠左排列),这种结构的节点可以通过 “层序遍历” 的顺序无间隙地填入数组,且父 / 子节点的索引可通过简单数学公式计算,无需像普通二叉树那样存储左 / 右子节点指针,空间利用率接近 100%。
- 核心映射规则(必记)假设堆的底层数组为
queue,节点的数组索引为i(从 0 开始),则: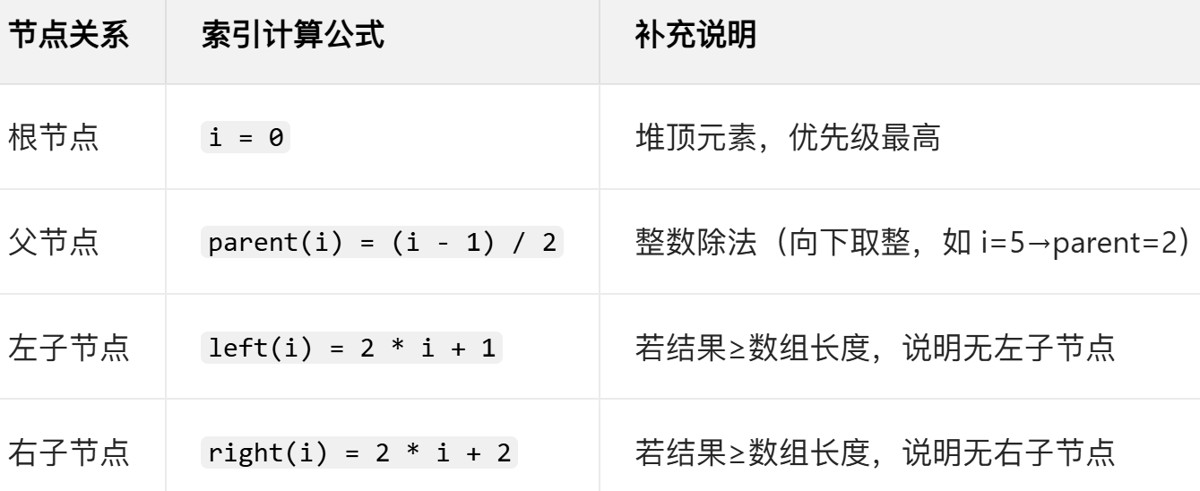

5.可视化示例(最小堆)
以最小堆 [1, 3, 8, 5, 4] 为例,完全二叉树结构与数组存储的对应关系:
1 (索引0) ← 堆顶
/ \
3(1) 8(2)
/ \
5(3) 4(4)对应的底层数组 queue = [1, 3, 8, 5, 4],验证映射规则:
- 索引 1(节点 3)的父节点:(1-1)/2 = 0(节点 1);
- 索引 0(节点 1)的左子节点:2*0+1=1(节点 3),右子节点:2*0+2=2(节点 8);
- 索引 3(节点 5)的父节点:(3-1)/2=1(节点 3),无左右子节点(2*3+1=7 ≥ 5)。
6.关键节点类型的索引判断(堆操作的基础)
基于数组存储的特性,可快速判断节点类型,这是堆化、siftUp/siftDown 的核心依据:
- 叶子节点:索引范围
[size/2, size-1](size为堆的元素个数);示例:上述堆 size=5,叶子节点索引为[2,4](节点 8、5、4),叶子节点无需执行 siftDown(无后代可比较)。 - 非叶子节点:索引范围
[0, size/2 - 1];示例:size=5,非叶子节点索引为[0,1](节点 1、3),堆化时仅需遍历这些节点执行 siftDown。
7.关于siftUp/siftDown
siftUp(向上调整) 和 siftDown(向下调整),二者是堆(优先队列底层)维护「堆序性」的核心操作
| 操作 | 触发场景 | 核心目的 | 核心逻辑(以最小堆为例) |
| siftUp | 往堆中插入新元素(如 offer) | 让新元素找到正确位置,保证堆序性 | 1. 新元素先放到数组尾部(堆的最后一个节点);2. 不断和父节点比较,若更小则交换;3. 直到满足「父≤子」或到根节点。 |
| siftDown | 1. 删除堆顶元素(如 poll);2. 堆化(heapify) | 让替换到堆顶 / 非叶子节点的元素归位,保证堆序性 | 1. 从当前节点(堆顶 / 非叶子节点)开始;2. 不断和左右子节点比较,选更小的子节点交换;3. 直到满足「父≤子」或到叶子节点。 |
总结:siftUp 是「自下而上」找位置(插入用),siftDown 是「自上而下」找位置(删堆顶 / 堆化用),最终都是为了让堆满足「最小 / 最大堆」的核心规则。
8.建堆的时间复杂度
建堆(heapify)的时间复杂度是 O(n)(而非直觉上的 O (n log n)),这是堆操作中极易混淆的关键点,以下用「结论 + 原理 + 对比」讲清楚:
8.1核心结论

8.2为什么堆化是 O (n)?(通俗推导)
堆化的核心是「从最后一个非叶子节点反向遍历,执行 siftDown」,不同层级的节点执行 siftDown 的次数不同,叶子节点甚至无需调整,整体操作次数远低于 O (n log n):
- 堆的结构基础:堆是完全二叉树,假设堆的高度为
h(根节点层级为 0,叶子节点层级为h),节点总数n ≈ 2^(h+1) - 1; - 分层计算操作次数:
- 层级
k的节点数:2^k个; - 该层级节点执行 siftDown 的最大次数:
h - k(越靠近根节点,需要向下调整的次数越多;叶子节点层级h,调整次数为 0);
- 层级
- 总操作次数求和:总次数 =
2^0*(h) + 2^1*(h-1) + 2^2*(h-2) + ... + 2^(h-1)*1;数学求和后可推导:总次数 ≈2n(收敛到 O (n))。
8.3对比理解(为什么不是 O (n log n)?)
如果用「逐个 offer 元素(每次 siftUp)」的方式建堆,时间复杂度是 O (n log n):
- 每个元素插入时,最多需要从叶子节点调整到根节点(最多
h=log n次操作); n个元素总操作次数 =n * log n,即 O (n log n)。
而堆化用 siftDown,仅非叶子节点需要调整,且越靠近叶子的节点调整次数越少,整体效率远高于逐个插入 —— 这也是 PriorityQueue 初始化集合时选择 heapify(而非循环 offer)的核心原因。
总结:堆化(O (n))是「批量优化版」建堆,利用完全二叉树的层级特性减少无效调整;逐个插入(O (n log n))是「动态零散版」,无批量优化,效率更低。
三、堆(PriorityQueue)常用接口 / API 全解析
Java 中堆的操作完全通过 PriorityQueue 类暴露(实现 Queue 接口),以下是开发中最常用的接口,按「核心操作、查询操作、辅助操作」分类,结合堆的底层逻辑讲解(默认最小堆,最大堆仅比较器不同):
1.接口体系背景
PriorityQueue 实现了 java.util.Queue 接口,间接继承 Collection/Iterable,所有接口均围绕「堆的核心特性(堆顶为极值、O (log n) 插入 / 删除)」设计,底层关联 siftUp/siftDown 等堆操作。
2.核心操作(堆的插入 / 删除)
| 方法签名 | 功能说明 | 关键细节(参数 / 返回 / 异常 / 底层堆操作) |
| boolean offer(E e) | 向堆中插入元素(推荐使用,非阻塞) | - 参数: - 返回:插入成功返回 true(堆自动扩容,几乎不会返回 false); - 底层:元素插入数组尾部 → 执行 |
| boolean add(E e) | 向堆中插入元素(推荐使用,非阻塞) | - 异常:元素为 null 抛 - 底层:同 |
| E poll() | 删除并返回堆顶元素(优先级最高,最小堆为最小值) | - 返回:堆为空时返回 null;非空时返回堆顶元素; - 底层:尾元素替换堆顶 → 执行 |
| boolean remove(Object o) | 删除堆中指定元素(若存在) | - 参数: - 返回:删除成功返回 true,失败返回 false; - 底层:遍历数组找元素索引(O (n))→ 尾元素替换目标位置 → 执行 siftUp/siftDown 调整,时间复杂度 O (n)(遍历占主导)。 |
3.辅助操作(堆的清空 / 遍历)
| 方法签名 | 功能说明 | 关键细节 |
| void clear() | 清空堆中所有元素 | - 底层:将数组元素置为 null,size 置 0,无堆调整,O (n)(需遍历置空)。 |
| Iterator<E> iterator() | 获取堆的迭代器 | - 返回:Iterator 实例; - 关键:迭代器遍历的是堆的底层数组,结果无序(仅堆顶有序); - 注意:遍历过程中修改堆(如 offer/poll)会触发快速失败( |
总结
到此这篇关于Java优先队列PriorityQueue的文章就介绍到这了,更多相关Java优先队列PriorityQueue内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!