
R语言中rbind() 与 merge() 的区别与应用场景
作者:烟锁池塘柳0
R语言中rbind()与merge()区别:rbind按行拼接,要求列结构一致;merge按键(如ID)合并,类似SQL JOIN,允许不同结构,前者用于纵向叠加数据,后者用于根据键列关联数据,适用于不同场景的数据整合需求,感兴趣的朋友跟随小编一起看看吧
R语言中rbind()与merge()的区别详解
在R语言中,对两个数据框(data.frame)进行合并操作的常用函数有 rbind() 和 merge(),但它们的用途和逻辑完全不同。本文就来详细介绍一下这两个函数的区别与应用场景。
1rbind()—— 按行拼接
1.1 基本功能
- 作用:把两个数据框按照“行”的维度进行拼接(row bind),也就是增加数据的“条数”,但是每个数据的“属性”不变化。
- 要求:两个数据框必须具有 相同的列名 和 相同的列数,否则会报错或强制补
NA。 - 常见用途:当两个数据框结构相同,只是观测值不同,需要纵向叠加时。
1.2 示例
df1 <- data.frame(id = 1:3, value = c("A", "B", "C"))
df2 <- data.frame(id = 4:5, value = c("D", "E"))
rbind(df1, df2)结果:
id value
1 1 A
2 2 B
3 3 C
4 4 D
5 5 E
👉 df2 的数据被直接拼接在 df1 的下面。
2merge()—— 按键合并
2.1 基本功能
- 作用:根据一个或多个键列(key),把两个数据框进行 数据库式的合并,非常类似 SQL 的
JOIN,或者GIS中的表连接。 - 参数:
by:指定键列。如果不写,默认使用两个数据框中同名的列。all、all.x、all.y:控制是否保留不匹配的行,类似 SQL 中的全连接、左连接、右连接。
all:逻辑值,all = L 是 all.x = L 和 all.y = L 的简写,L 可以是 TRUE 或 FALSE。
all.x:逻辑值,默认为 FALSE。如果为 TRUE, 显示 x 中匹配的行,即便 y 中没有对应匹配的行,y 中没有匹配的行用 NA 来表示。
all.y:逻辑值,默认为 FALSE。如果为 TRUE, 显示 y 中匹配的行,即便 x 中没有对应匹配的行,x 中没有匹配的行用 NA 来表示。
2.2 示例
df1 <- data.frame(id = 1:3, score = c(90, 85, 88))
df2 <- data.frame(id = c(2, 3, 4), name = c("Tom", "Jerry", "Lucy"))
merge(df1, df2, by = "id", all = TRUE)结果:
id score name
1 1 90 <NA>
2 2 85 Tom
3 3 88 Jerry
4 4 <NA> Lucy
👉 可以看到,id 相同的行被合并到一起,不匹配的地方用 NA 填充。
3 详细解释 merge() 函数和 SQL 的 JOIN 功能的相似性
(此处参考:R 数据重塑 | 菜鸟教程 。)
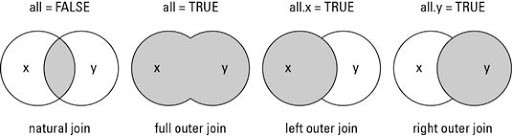
| merge() 设置 | SQL 等价 | 保留哪些行 |
|---|---|---|
默认(all = FALSE) | INNER JOIN | 仅键匹配成功的行 |
all.x = TRUE | LEFT JOIN | 左表全部 + 右表匹配,不匹配右侧补 NA |
all.y = TRUE | RIGHT JOIN | 右表全部 + 左表匹配,不匹配左侧补 NA |
all = TRUE 或 all.x=TRUE & all.y=TRUE | FULL OUTER JOIN | 两表全部,任何一侧不匹配的用对侧列 NA 补齐 |
3.1 示例与结果对照
x <- data.frame(id = 1:3, score = c(90, 85, 88))
y <- data.frame(id = c(2, 3, 4), name = c("Tom", "Jerry", "Lucy"))3.1.1 内连接(默认)—— 只要公共部分
merge(x, y, by = "id")
id score name 1 2 85 Tom 2 3 88 Jerry
3.1.2 左连接 —— 保留 x 的所有行
merge(x, y, by = "id", all.x = TRUE)
id score name 1 1 90 <NA> # y 中没有 id=1,用 NA 补 2 2 85 Tom 3 3 88 Jerry
3.1.3 右连接 —— 保留 y 的所有行
merge(x, y, by = "id", all.y = TRUE)
id score name 1 2 85 Tom 2 3 88 Jerry 3 4 <NA> Lucy # x 中没有 id=4,用 NA 补
3.1.4 全连接 —— 两边都不丢
merge(x, y, by = "id", all = TRUE) # 同等写法:merge(x, y, by = "id", all.x = TRUE, all.y = TRUE)
id score name 1 1 90 <NA> 2 2 85 Tom 3 3 88 Jerry 4 4 <NA> Lucy
3.2 几个实用细节(容易忽略)
- 键列的指定
by = "id":两表键列同名。by.x = "key_in_x",by.y = "key_in_y":两表键列不同名时这样写。- 可以是多个键:
by = c("id", "date")。
- 重复键会产生“乘法效应”
- 如果两边同一个键各有多行,
merge()会做笛卡尔匹配(m×n 行)。这是预期行为,非 Bug。 - 必要时先
unique()去重或在键上汇总。
- 如果两边同一个键各有多行,
- 排序
- 默认
sort = TRUE,结果会按键列排序; - 要尽量保持原表顺序(尤其左连接),用
sort = FALSE:
- 默认
merge(x, y, by = "id", all.x = TRUE, sort = FALSE)
- 同名非键列的冲突
- 两表中键以外有同名列,
merge()会保留两列,并自动加后缀: suffixes = c(".x", ".y")(可自定义)。
- 两表中键以外有同名列,
- 缺失值匹配
- 默认
NA不参与匹配;可用incomparables = NA阻止某些值匹配(较少用)。
- 默认
4rbind()vsmerge()核心区别
| 函数 | 合并方式 | 要求/特点 | 适用场景 |
|---|---|---|---|
rbind() | 直接拼行(纵向叠加) | 两个数据框必须有相同的列名和结构 | 数据框结构完全相同,只是增加观测值 |
merge() | 按键匹配合并(类似 SQL JOIN) | 根据某些列进行匹配,不要求列结构相同 | 两个数据框包含不同的变量,需要根据键对齐 |
5 总结
- 如果你的数据框结构一致,只是想简单地“上下拼接”,用
rbind()。 - 如果你需要根据某些列进行类似数据库表的连接,用
merge()。
掌握这两个函数的区别,有助于在数据预处理阶段更高效地完成任务。
📌 推荐用法选择:
rbind()更适合批量读取多个同结构数据(比如多个 Excel sheet)。merge()更适合数据关联(比如学生成绩表和学生信息表的合并)。
到此这篇关于R语言中rbind() 与 merge() 的区别详解的文章就介绍到这了,更多相关R语言 rbind() 与 merge() 区别内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!