
使用java编写一个字符串词频统计工具
作者:风轻云淡的开发
许多英语培训机构(如新东方)都会出几本“高频词汇”的书,主要内容是统计近几年来各类外语考试中屡次出现的高频词汇,帮助考生减少需要背的生词的数量。但这些高频是如何被统计出来的呢?显然不会用手工去计算。
假如我们已经将一篇文章存在一字符串(String)对象中,为了统计词汇出现频率,最简单直接的做法是另外建一个Map:key是单词,value是 次数。将文章从头读到尾,读到一个单词就到Map里查一下,如果查到了则次数加一,没查到则往Map里一扔。
/**
* Java中提供一个非常棒的HashMap函数,只需要一步就可以统计单词的频率
*/
import java.util.HashMap;
public class WordMap {
public static void main(String[] args) {
String input = "a1,b2,3c,d4d,a1,b2,a1";
String[] ws = input.split(",");
// 做的单词分割,
// 如果你要空格分割 String[] ws = input.split(" ");
HashMap<String, Integer> hm = new HashMap<String, Integer>();
// 初始化HashMap
for (String s : ws) {
if (s.matches("[a-zA-Z]\\w+"))
// 这里是一个正则表达式,
// 判断的是第一个必须是字母,
// 后面的是一个字母或多个字母,
// 一个数字或多个数字
{
Integer cou = hm.get(s);
// get()方法将产生一个与键相关联的Integer值,
// 然后这个值被递增,为的是记录标识符的个数
hm.put(s, cou == null ? 1 : cou + 1);
// 保存到HashMap中以单词做key,判断单词是否为空,空为1,或则加1
}
}
System.out.println(hm);
// 打印HashMap
}
}这样做虽然代码写起来简单,但性能却非常差。首先查询Map的代价是O(logn),假设文章的字母数为m,则整个统计程序的时间复杂度为O(mlogn)不说,如果要拿高频词可能还需要对统计结果进行排序。即便对结构上进行优化性能仍然不高。如果能够将时间复杂度从O(mlogn)减少到O(m)的话不是更好?
为了改进算法我们首先引进单词树。与单词前缀树不同,单词树的结构相当简单,结构如图所示:
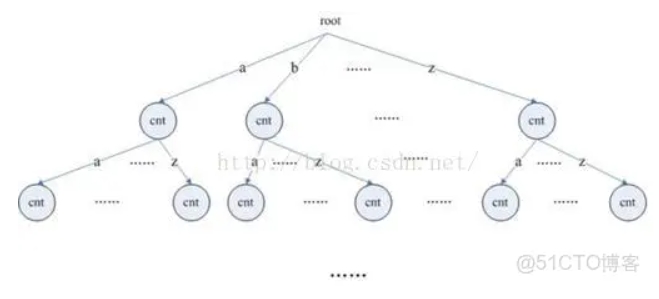
从图中我们可以看出,树中每个结点保存属性值cnt与指向其26个子结点的指针(每一条路径代表一个英文字母),其中cnt为到达该结点经过路 径所对应的英文单词在文章中出现的次数。也就是说,我们开始读文章时让一个指针指向单词数的根结点,之后每读一个字母就让该指针指向当前结点对应路径上的子结点(若子结点为空则新建一个),一个单词读完后让当前结点的cnt值加一,并让指针重新指向根结点。而当一篇文章读完之后我们的单词树也就已经建立完 毕了。之后只要去遍历它并把取到的单词根据次数进行排序就行了(时间复杂度为O(nlogn))。
程序代码如下,
首先是存放单词及出现次数的JavaBean
public class WordCount {
private String word;
private int count;
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
}其次是实现词频表生成算法的类:
public class WordCountService {
/**
* 根据文章生成单词树
* @param text
* @return
*/
private static CharTreeNode geneCharTree(String text){
CharTreeNode root = new CharTreeNode();
CharTreeNode p = root;
char c = ' ';
for(int i = 0; i < text.length(); ++i){
c = text.charAt(i);
if(c >= 'A' && c <= 'Z')
c = (char)(c + 'a' - 'A');
if(c >= 'a' && c <= 'z'){
if(p.children[c-'a'] == null)
p.children[c-'a'] = new CharTreeNode();
p = p.children[c-'a'];
}
else{
p.cnt ++;
p = root;
}
}
if(c >= 'a' && c <= 'z')
p.cnt ++;
return root;
}
/**
* 使用深度优先搜索遍历单词树并将对应单词放入结果集中
* @param result
* @param p
* @param buffer
* @param length
*/
private static void getWordCountFromCharTree(List result,CharTreeNode p, char[] buffer, int length){
for(int i = 0; i < 26; ++i){
if(p.children[i] != null){
buffer[length] = (char)(i + 'a');
if(p.children[i].cnt > 0){
WordCount wc = new WordCount();
wc.setCount(p.children[i].cnt);
wc.setWord(String.valueOf(buffer, 0, length+1));
result.add(wc);
}
getWordCountFromCharTree(result,p.children[i],buffer,length+1);
}
}
}
private static void getWordCountFromCharTree(List result,CharTreeNode p){
getWordCountFromCharTree(result,p,new char[100],0);
}
/**
* 得到词频表的主算法,供外部调用
* @param article
* @return
*/
public static List getWordCount(String article){
CharTreeNode root = geneCharTree(article);
List result = new ArrayList();//此处也可用LinkedList链表,以避免数组满了扩容导致的性能损失
getWordCountFromCharTree(result,root);
Collections.sort(result, new Comparator(){
public int compare(Object o1, Object o2) {
WordCount wc1 = (WordCount)o1;
WordCount wc2 = (WordCount)o2;
return wc2.getCount() - wc1.getCount();
}
});
return result;
}
}
/**
* 单词树结点的定义
* @author FlameLiu
*
*/
class CharTreeNode{
int cnt = 0;
CharTreeNode[] children = new CharTreeNode[26];
}到此这篇关于使用java编写一个字符串词频统计工具的文章就介绍到这了,更多相关java词频统计内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!