
mybatis-plus的分页拦截器(PaginationInterceptor)分页失败问题及解决
作者:thewindkee
这篇文章主要介绍了mybatis-plus的分页拦截器(PaginationInterceptor)分页失败问题及解决,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教
背景
项目中使用到了mybatis-plus的3.0.5版本,分页拦截器是PaginationInterceptor。
代码如下:
@Transactional(readOnly = true)
public void test() {
int current =1;
while (true) {
final LambdaQueryWrapper<Foo> query = Condition.<Foo>lambda().gt(AppProject::getBusiId, 1);
//传入增长页数来查询
Page<Foo> page = new Page<>(current++, 1000);
Page<Foo> result = fooMapper.selectPage(page, query);
//...业务
if (result .getRecords() == null && || CollectionUtils.isEmpty(result .getRecords())) {
break;
}
}
}现象
1.无法从while中跳出循环。
2.打印sql日志只打印了一次。
猜测
- 怀疑分页失败了。
- 由于只有一次日志,怀疑之后都走到了缓存。
证明过程
1.使用arthas看看sql是怎样的
tt org.apache.ibatis.mapping.SqlSource getBoundSql '{params,returnObj,throwExp}'拿出来的sql的确没有LIMIT
- TODO 待修改
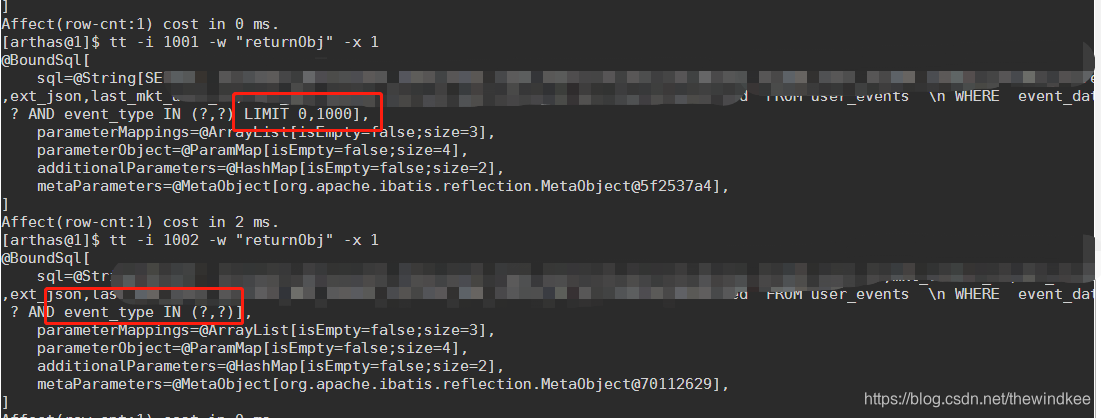
打开sql日志,也有观察到Limit语句,虽然只出现了一次,但说明是有分页的。
因此:猜测1不成立。
2.查看PaginationInterceptor
PaginationInterceptor拦截的是StatementHandler#prepare,在prepare方法执行的时候,才会添加Limit语句。而在调用添加Limit语句之前,已经拿了缓存中的数据,不会真正执行查询了。
- 调用顺序为:

由上图可以看出,当生成cacheKey的时候,由于此时的boundSql还未被拦截,不含有Limit语句,每次boundSql都一样,导致cacheKey都一样。
因此:
- 只有第一次查询会走不到缓存,然后被prepare阶段被拦截,添加Limit语句后查询数据库。将数据放入一级缓存中。
- 第二次查询开始,由于有事务,会尝试利用一级缓存中的数据,且cacheKey一样,缓存有对应的数据,就直接返回了缓存中的数据。
生成缓存key
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameter);
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}优先查一级缓存,无缓存则查数据库
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}添加Limit语句
/**
* <p>
* MYSQL 数据库分页语句组装实现
* </p>
*
* @author hubin
* @since 2016-01-23
*/
public class MySqlDialect implements IDialect {
@Override
public String buildPaginationSql(String originalSql, long offset, long limit) {
StringBuilder sql = new StringBuilder(originalSql);
sql.append(" LIMIT ").append(offset).append(StringPool.COMMA).append(limit);
return sql.toString();
}
}问题出现原因
- PaginationInterceptor拦截时期太晚,导致虽然传了不同的页数,但是提前生成的cacheKey一样。
- 使用了事务,导致用到同一sqlSession,走到了一级缓存。
解决方法
- 升级Mybatis-Plus,高版本的MybatisPlusInterceptor来分页。(MybatisPlusInterceptor的拦截在cacheKey生成之前,可以避免上述问题)
- 不在事务中使用分页查询。
总结
分页太深,查询太慢,最后还是放弃了这种分页查询方式。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。