
对HashMap的数据结构的学习解读
作者:找不到、了
1、介绍
JDK1.8之前HashMap由数组+链表组成。数组是HshMap的主体,链表则是主要为了解决哈希冲突。
JDK1.8及以后的版本在解决哈希冲突时有了较大的变化,当链表长度大于阈值(或者红黑树的边界值,默认为8,且数组中桶的数量大于64,此时此索引位置上的所有数据改为使用红黑树存储。
1.1、数据结构
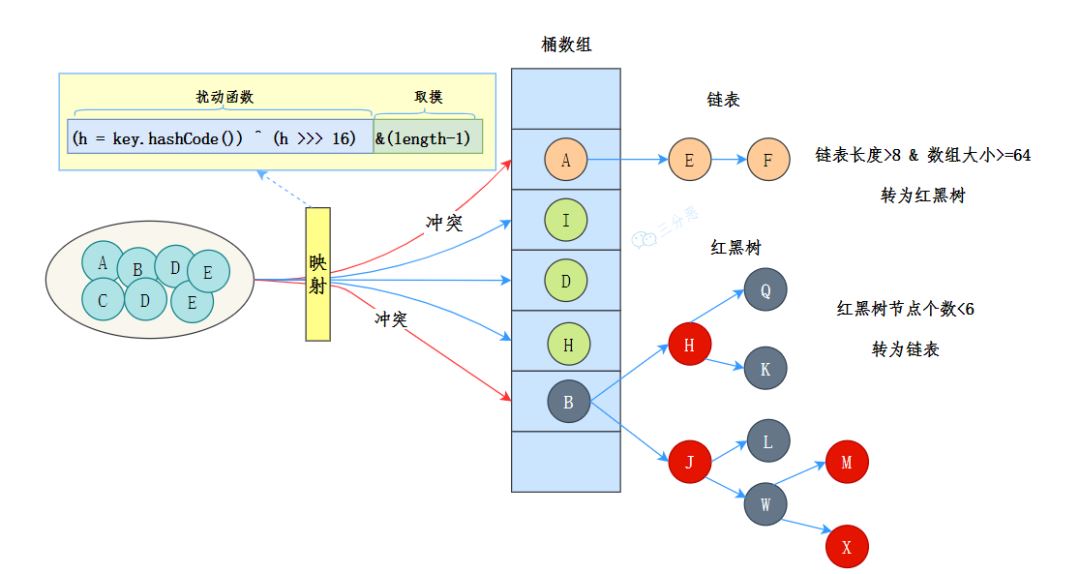
如下图所示:
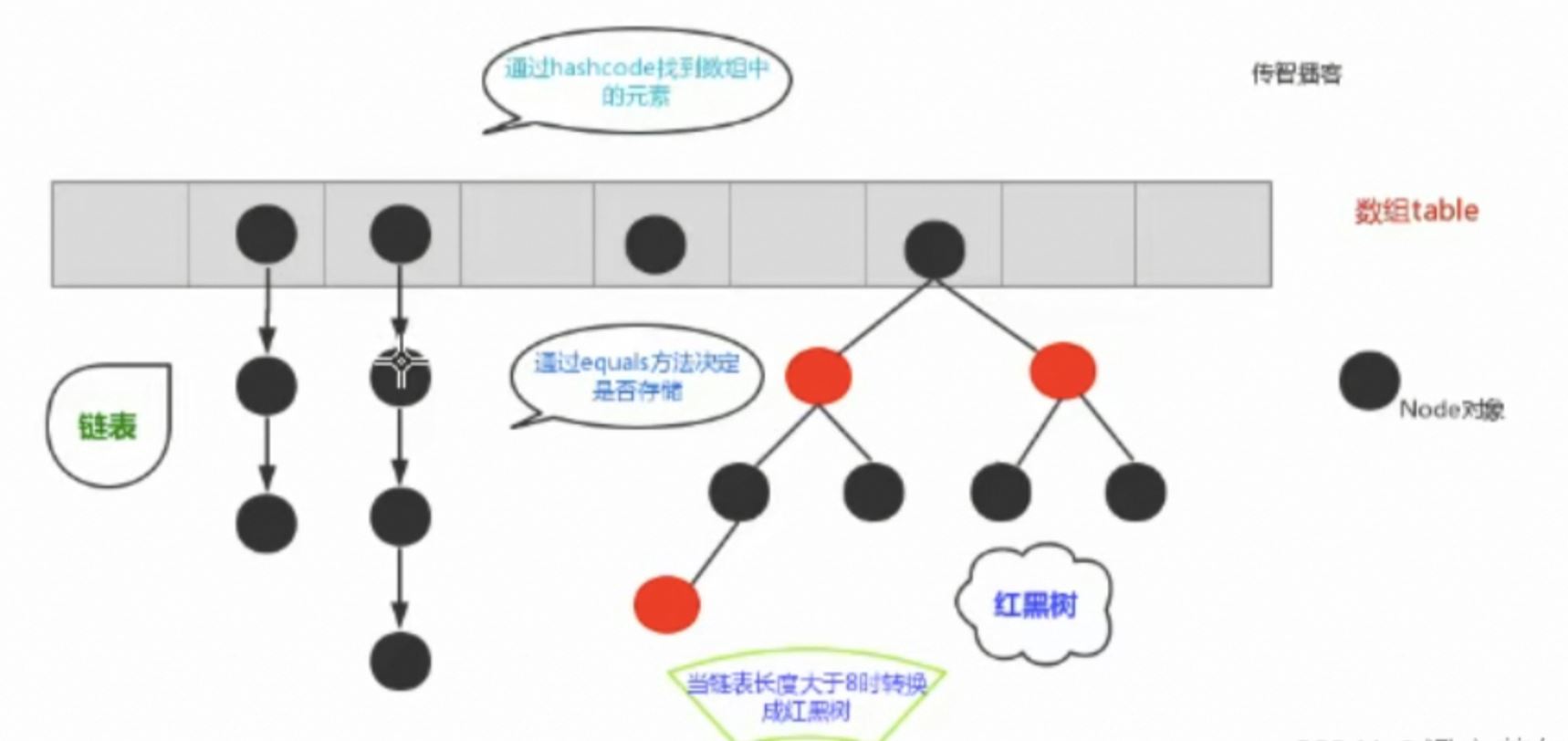
桶数组是用来存储数据元素,链表是用来解决冲突,红黑树是为了提高查询的效率。
数据元素通过映射关系,也就是散列函数,映射到桶数组对应索引的位置。
1.如果发生冲突,从冲突的位置拉一个链表,插入冲突的元素。
- 如果链表长度>8&数组大小>=64,链表转为红黑树。
- 如果红黑树节点个数<6 ,转为链表。
2.但是数组长度小于64,此时并不会将链表变为红黑树。而是选择进行数组扩容。
- 目的是因为数组比较小,尽量避开红黑树结构,这种情况下变为红黑树结构,反而会降低效率,因为红黑树需要进行左旋,右旋,变色这些操作来保持平衡 。同时数组长度小于64时,搜索时间相对要快些。
所以综上所述为了提高性能和减少搜索时间,底层在阈值大于8并且数组长度大于64时,链表才转换为红黑树。
至于为什么要转变从链表转到红黑树,以及红黑树转链表:JDK8 HashMap红黑树退化为链表的机制解读
1.2、红黑树
为什么要使用红黑树:
如果链表非常长(特别是在某些不均匀分布的哈希情况下),查找、插入和删除的性能会降到 O(n) 的水平,因为需要遍历整个链表。
在这里简单介绍下红黑树:
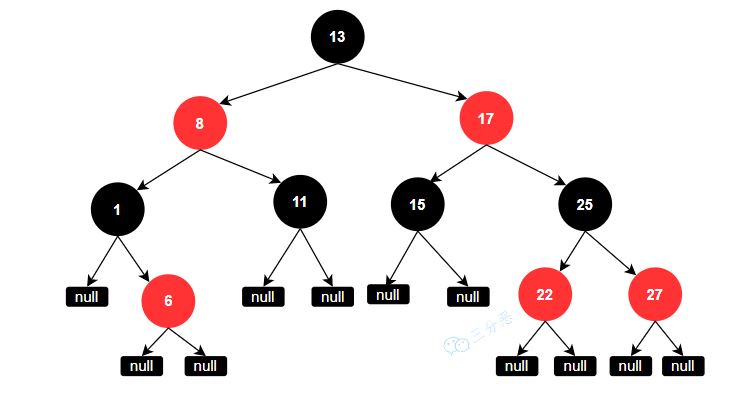
由上图可知:
红黑树本质上是一种二叉查找树,为了保持平衡,它又在二叉查找树的基础上增加了一些规则:
1、每个节点要么是红色,要么是黑色;
2、根节点永远是黑色的;
3、所有的叶子节点都是是黑色的(注意这里说叶子节点其实是图中的 NULL 节点);
4、每个红色节点的两个子节点一定都是黑色;
从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点;
这种方式可以在最坏情况下将查找、插入和删除的时间复杂度降低到 O(log n)。
红黑树怎么保持平衡?
红黑树有两种方式保持平衡:旋转和染色。
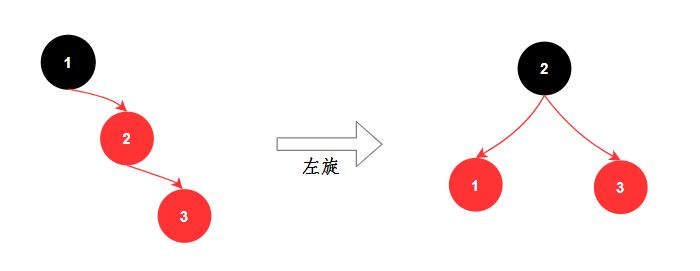
旋转分为左旋和右旋。
1、左旋
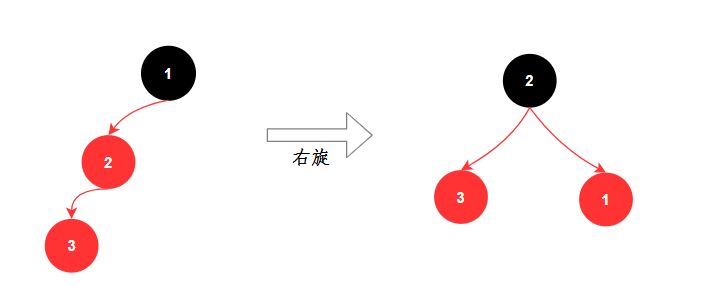
2、右旋
1.3、参数
查看HashMap源码,可以看到以下常用的变量,因此先在这里进行归类:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4:默认的table初始容量 static final float DEFAULT_LOAD_FACTOR = 0.75f:默认的负载因子 static final int TREEIFY_THRESHOLD = 8: 链表长度大于等于该参数转红黑树 static final int UNTREEIFY_THRESHOLD = 6: 当树的节点数小于等于该参数转成链表 transient Node<K,V>[] table:这是一个Node类型的数组(也有称作Hash桶)
可以从下面源码中看到静态内部类Node在这边可以看做就是一个节点,多个Node节点构成链表,当链表长度大于8的时候转换为红黑树。
2、成员变量
Node 类
HashMap 内部使用的一个重要结构是 Node,通常定义为一个静态内部类,用于存储键值对。
static class Node<K, V> {
final int hash; // 键的哈希值
final K key; // 键
V value; // 值
Node<K, V> next; // 指向下一个节点,处理链表冲突
}1. Node<K,V>[] table
- 类型:
Node<K,V>[] - 描述: 这是一个数组,存储了 HashMap 的所有 "桶"(bucket)。
- 作用: 每个桶对应一个链表(或红黑树)以解决哈希冲突。桶的 index 通过取键的哈希值并与数组的长度进行模运算得到。
2. int size
- 类型:
int - 描述: 当前 HashMap 中键值对的数量。
- 作用: 用于追踪 HashMap 中的元素数量,便于在执行操作时(如添加或删除元素)进行容量检查。
3. int threshold
- 类型:
int - 描述: 扩容阈值,即当 HashMap 中的元素数量达到该值时,将触发扩容。
- 作用: 阈值由
capacity * load factor计算得出。它帮助管理 HashMap 的容量和负载因子,防止在高负载下性能下降。
4. float loadFactor
- 类型:
float - 描述: 负载因子是一个决定 HashMap 扩容策略的参数。默认值是 0.75。
- 作用: 它用于衡量 HashMap 中使用的空间与实际容纳的空间之间的比率。当 HashMap 中的元素数量超过这个比率所计算的阈值时,它将扩容。
通过合理的负载因子设置:
不同的负载因子会影响 HashMap 的性能。较低的负载因子(例如 0.5)会使得 HashMap 更频繁地扩容,从而减少冲突并提高快速访问的性能,但会浪费内存。
高负载因子的影响:
较高的负载因子(例如 0.9)可以提高内存使用效率,但同时也增加了哈希冲突的风险,这可能导致访问性能下降(例如,查询、插入和删除的时间复杂度从 O(1) 变为 O(n))。
以下代码示例比较了使用不同负载因子的 HashMap 在大量插入元素时的性能差异:
import java.util.HashMap;
public class HashMapPerformanceTest {
public static void main(String[] args) {
int numberOfElements = 1_000_000; // 要插入的元素数量
// 测试负载因子为默认值 (0.75)
long timeWithDefaultLoadFactor = testHashMapPerformance(0.75f, numberOfElements);
System.out.println("Time taken with default load factor (0.75): " + timeWithDefaultLoadFactor + " ms");
// 测试负载因子为 0.5
long timeWithLowLoadFactor = testHashMapPerformance(0.5f, numberOfElements);
System.out.println("Time taken with low load factor (0.5): " + timeWithLowLoadFactor + " ms");
// 测试负载因子为 0.9
long timeWithHighLoadFactor = testHashMapPerformance(0.9f, numberOfElements);
System.out.println("Time taken with high load factor (0.9): " + timeWithHighLoadFactor + " ms");
}
private static long testHashMapPerformance(float loadFactor, int numberOfElements) {
long startTime = System.currentTimeMillis();
HashMap<Integer, String> map = new HashMap<>(16, loadFactor); // 初始化 HashMap
// 插入元素
for (int i = 0; i < numberOfElements; i++) {
map.put(i, "Value " + i);
}
long endTime = System.currentTimeMillis();
return endTime - startTime; // 返回耗时
}
}输出结果:
Time taken with default load factor (0.75): 197 ms
Time taken with low load factor (0.5): 716 ms
Time taken with high load factor (0.9): 552 ms
5. int modCount
- 类型:
int - 描述: 记录 HashMap 进行结构性修改的次数。
- 作用: 用于实现 fail-fast 机制,能够检测到在迭代 HashMap 时是否发生了并发修改,通过与迭代器中的记录值进行比较来判断。
关于fail-fast机制:可参考JDK8 HashMap红黑树退化为链表的机制解析
3、构造方法
以下有四种不同的初始化方式。
1、无参构造
//构造一个空的HashMap,默认初始容量16和负载因子0.75
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
2、有初始化容量构造
//构造一个指定初始容量的HashMap,默认负载因子0.75。
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}3、指定容量和负载因子
//构造一个指定的HashMap,指定默认初始容量和负载因子
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}4、映射Map
//构造一个映射的map
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}HashMap和HashSet都允许你指定负载因子的构造器,表示当负载情况达到负载因子水平的时候,容器会自动扩容,HashMap默认使用的负载因子值为0.75f(当容量达到四分之三进行再散列(扩容))。当负载因子越大的时候能够容纳的键值对就越多但是查找的代价也会越高。
4、常用方法
4.1、put方法
在使用默认构造器初始化一个HashMap对象的时候,首次Put键值对的时候会先计算对应Key的hash值通过hash值来确定存放的地址。
原理:
计算哈希值:
- 首先,根据键的
hashCode()方法计算出键的哈希值,并通过某种哈希算法对其进行整合,以找到适合当前HashMap容量的索引。
关于更多的哈希值的介绍可参考:HashMap中哈希值与数组坐标的关联
检查桶(bucket):
- 使用计算出的索引在内部数组
table中查找对应的桶。如果该桶已经有元素,则需要检查是否存在哈希冲突(即多个键经过哈希计算后映射到了同一个桶)。
处理冲突:
- 如果找到了冲突,
HashMap将采用链表(Java 7及之前)或红黑树(Java 8引入,当链表长度超过一定阈值时)来存储冲突的元素。 - 遍历桶中的元素,看是否已有相同的键。如果找到了,更新其对应的值;如果没找到,就将新键值对添加到链表或树的末尾。
更新大小和阈值:
- 在插入后更新当前的元素数量(
size),并检查是否需要扩容(即判断当前数量与负载因子乘积的关系)
每当元素数量增加到阈值时(即 size >= threshold),HashMap 会调用 resize() 方法来扩大底层数组的大小。
以下是put的简化版代码示例:
import java.util.Arrays;
class MyHashMap<K, V> {
static class Node<K, V> {
final int hash; // 存储哈希值
final K key; // 存储键
V value; // 存储值
Node<K, V> next; // 指向下一个节点
Node(int hash, K key, V value, Node<K, V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
private Node<K, V>[] table; // 存储节点的数组
private int size; // 当前大小
private int threshold; // 扩容阈值
private float loadFactor; // 负载因子
public MyHashMap(int initialCapacity, float loadFactor) {
this.loadFactor = loadFactor;
this.table = new Node[initialCapacity];
this.threshold = (int)(initialCapacity * loadFactor);
}
public void put(K key, V value) {
int hash = key == null ? 0 : key.hashCode();
int index = (hash & (table.length - 1)); // 计算桶的索引
Node<K, V> existingNode = table[index];
// 检查桶是否为空
if (existingNode == null) {
// 如果桶为空,创建一个新节点
table[index] = new Node<>(hash, key, value, null);
size++;
} else {
// 遍历链表,检查是否已有相同的键
Node<K, V> currentNode = existingNode;
while (true) {
if (currentNode.hash == hash && (currentNode.key == key || (key != null && key.equals(currentNode.key)))) {
// 找到相同的键,更新值
currentNode.value = value;
return;
}
if (currentNode.next == null) {
// 没有找到,添加新节点
currentNode.next = new Node<>(hash, key, value, null);
size++;
break;
}
currentNode = currentNode.next;
}
}
// 检查是否需要扩容
if (size >= threshold) {
resize();
}
}
private void resize() {
// 扩容逻辑,目前省略具体实现
}
}4.2、get方法
扩展:
在 Java 中,hashCode() 函数的返回值是一个 int 类型,意味着哈希码的值占用 32 位(4 字节)。hashCode() 函数计算出的值可以在范围 [-2,147,483,648, 2,147,483,647] 之间。
高位与低位的解释
- 低位(Least Significant Bits, LSB):在这个上下文中,低位是指哈希码的最右边的位。对于一个
int类型,32 位中最右边的 16 位即为低位部分(即得到的结果是0x0000FFFF)。 - 高位(Most Significant Bits, MSB):这是指哈希码的最左边的位。对于一个
int类型,最左边的 16 位即为高位部分(即得到的结果是0xFFFF0000)。
先右移异或
首先会根据hashcode函数的到hash值,然后右移16位,然后将原始值和右移后的值进行异或(相同为0,不同为1)。
int hash = key.hashCode(); // 分两次右移,并进行异或,减少碰撞 hash ^= (hash >>> 16);
为什么右移16位和异或:
- 右移 16 位的操作是为了将高位(通常低位 bits 可能更有可能重复)与低位进行混合。这是一种减小碰撞的方式,通过与高位进行异或运算,使得哈希值更加复杂,概率上减少哈希冲突。
- 右移之后的结果与原始哈希码进行异或,进一步打散哈希值。这样,无论哈希码的某部分和另外一部分如何重复,通过这一步都会产生不同的结果,减少哈希冲突的概率。
再计算哈希值:
- 使用键的
hashCode()方法计算哈希值,然后通过与当前数组长度的模运算(通常为数组长度减去 1)来找到该键应存储在数组中的桶(bucket)位置。
int index = (hash & (table.length - 1));
查找桶(bucket):
根据计算出的索引,从内部数组 table 中获取相应的桶(Node[])。如果桶是空的,直接返回 null,表示所查询的键不存在。
遍历链表或红黑树 (处理哈希冲突):
如果桶中有多个元素(即形成了链表或红黑树),则需要遍历链表或树来查找对应的键。
使用 equals() 方法比较每个节点的键,找到匹配的键时返回对应的值。
返回值:
如果找到了匹配的键,返回其对应的值;如果未找到,则返回 null。
以下是get方法的代码示例图:
class Node<K, V> {
final int hash;
final K key;
V value;
Node<K, V> next;
Node(int hash, K key, V value, Node<K, V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
public class MyHashMap<K, V> {
private Node<K, V>[] table; // 存储节点的数组
private int size;
public MyHashMap(int initialCapacity) {
this.table = new Node[initialCapacity];
}
public V get(K key) {
if (key == null) {
return null; // 处理空键
}
int hash = key.hashCode(); // 计算哈希值
int index = (hash & (table.length - 1)); // 计算索引
Node<K, V> node = table[index]; // 获取对应的桶
// 遍历链表或红黑树
while (node != null) {
if (node.hash == hash && (node.key.equals(key))) {
return node.value; // 找到键,返回对应的值
}
node = node.next; // 移动到下一个节点
}
return null; // 未找到
}
}小结:
时间复杂度:
get操作的平均时间复杂度为 O(1),在理想情况下,若没有发生冲突。- 在最坏的情况下(所有元素都发生冲突,组成链表或红黑树),时间复杂度为 O(n) 或 O(log n),分别取决于链表或树的实现方式。
处理哈希冲突:
- 若两个或多个键的哈希值相同,会发生哈希冲突,使用链表或红黑树来解决冲突。
5、扩容
关于HashMap的原理图。
主要用于存储键值对。其内部实现包含了数组和链表(或红黑树)以处理哈希冲突。HashMap 在使用过程中会发生扩容,以确保其存储性能及均匀分布。
下面是 HashMap 扩容的详细原理。
5.1、扩容介绍
HashMap 的扩容是指当 HashMap 的当前容量不足以存储新的键值对时,自动调整其容量和结构,以提高其性能。
扩容通常会在 put() 方法中触发,这个方法用于将键值对添加到哈希表中。
5.2、扩容的触发条件
扩容会在以下情况下触发:
- 当
HashMap中的元素数量超过了负载因子(load factor)与当前容量的乘积,即:threshold=capacity×load 。
默认为 0.75 的负载因子。
举个例子:
- 初始容量: 默认
HashMap初始容量为 16。 - 负载因子: 默认负载因子为 0.75。
- 阈值: 计算得出的阈值为 16×0.75=12。
所以,当插入的元素数量达到 12 时,HashMap 会触发扩容。
5.3、扩容过程
当需要进行扩容时,HashMap 的扩容过程如下:
当前容量翻倍:
- 新容量是当前容量的 2 倍。
重新计算哈希:
- 每个键的哈希值会基于新的容量重新计算,并通过新的桶数组插入到相应的桶中。
- 为了保持元素的分布处理,
HashMap使用“链地址法”或拉链法处理哈希冲突。
元素迁移:
- 在扩容过程中,所有的键值对会被重新计算位置并拷贝到新的桶数组。
- 这需要遍历当前所有的链表或红黑树并重新插入到新位置。
示例:
public class HashMapDemo {
public static void main(String[] args) {
MyHashMap<String, Integer> map = new MyHashMap<>(4, 0.75f); // 初始化容量为4,负载因子为0.75
map.put("one", 1); → 当前大小为 1(没有触发扩容)。
map.put("two", 2); → 当前大小为 2(没有触发扩容)。
map.put("three", 3); → 当前大小为 3(这时已达到阈值,因此将触发扩容)。
map.put("four", 4); → 由于已经扩容,实际中会发生元素的重新分配,现在当前数组的大小为 4。
map.put("five", 5); → 当前大小为 5 (但是不会再触发扩容,因为数组容量已增加到 8)。
// 你可以扩展上面代码来实现 get 方法等
}
}HashMap是先插入还是先扩容:HashMap是先插入数据再进行扩容的,但是如果是刚刚初始化容器的时候是先扩容再插入数据。
5.4、扩容失败
通常会导致 OutOfMemoryError 异常,当前的操作(例如添加元素)将会失败。之后,HashMap 仍然保持不变,已经加入的元素也不会被丢失。
扩容属于原子操作,不会重试,因为扩容是同步操作,失败意味着资源不足,无法继续。
当扩容成功后的代码示例如下:
package com.example.test;
import java.lang.reflect.Field;
import java.util.HashMap;
public class HashMapTest {
public static void main(String[] args) {
HashMap<String, Object> map = new HashMap<>(4,0.75f);
map.put("one",1);
map.put("two",2);
map.put("three",3);
map.put("four",4);
try {
// 获取底层数组长度
Field tableField = HashMap.class.getDeclaredField("table");
tableField.setAccessible(true);
Object[] table = (Object[]) tableField.get(map);
System.out.println("键值对数量(map.size): " + map.size());
System.out.println("底层数组长度: " + (table != null ? table.length : 0));
} catch (NoSuchFieldException e) {
throw new RuntimeException(e);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
}
System.out.println("map.size="+map.size());
}
}结果输出:
键值对数量(map.size): 4
底层数组长度: 8
map.size=4
6、迭代异常
迭代器的remove()可以安全使用,而直接操作Map会触发异常。通过fast-fail机制可以有效的进行检测。
代码示例如下:
// 正确方式(使用迭代器的remove)
Iterator<String> it = map.keySet().iterator();
while (it.hasNext()) {
if (it.next().equals("remove")) {
it.remove(); // 不会增加modCount
}
} 这个是正常的, Map<String, Integer> map = new HashMap<>();
map.put("A", 1);
map.put("B", 2);Iterator<String> it = map.keySet().iterator();
while (it.hasNext()) {
String key = it.next();
map.put("C", 3); // 这里会触发fail-fast
} 而这个会触发fail-fast6.1、区别对比

6.2、源码解析
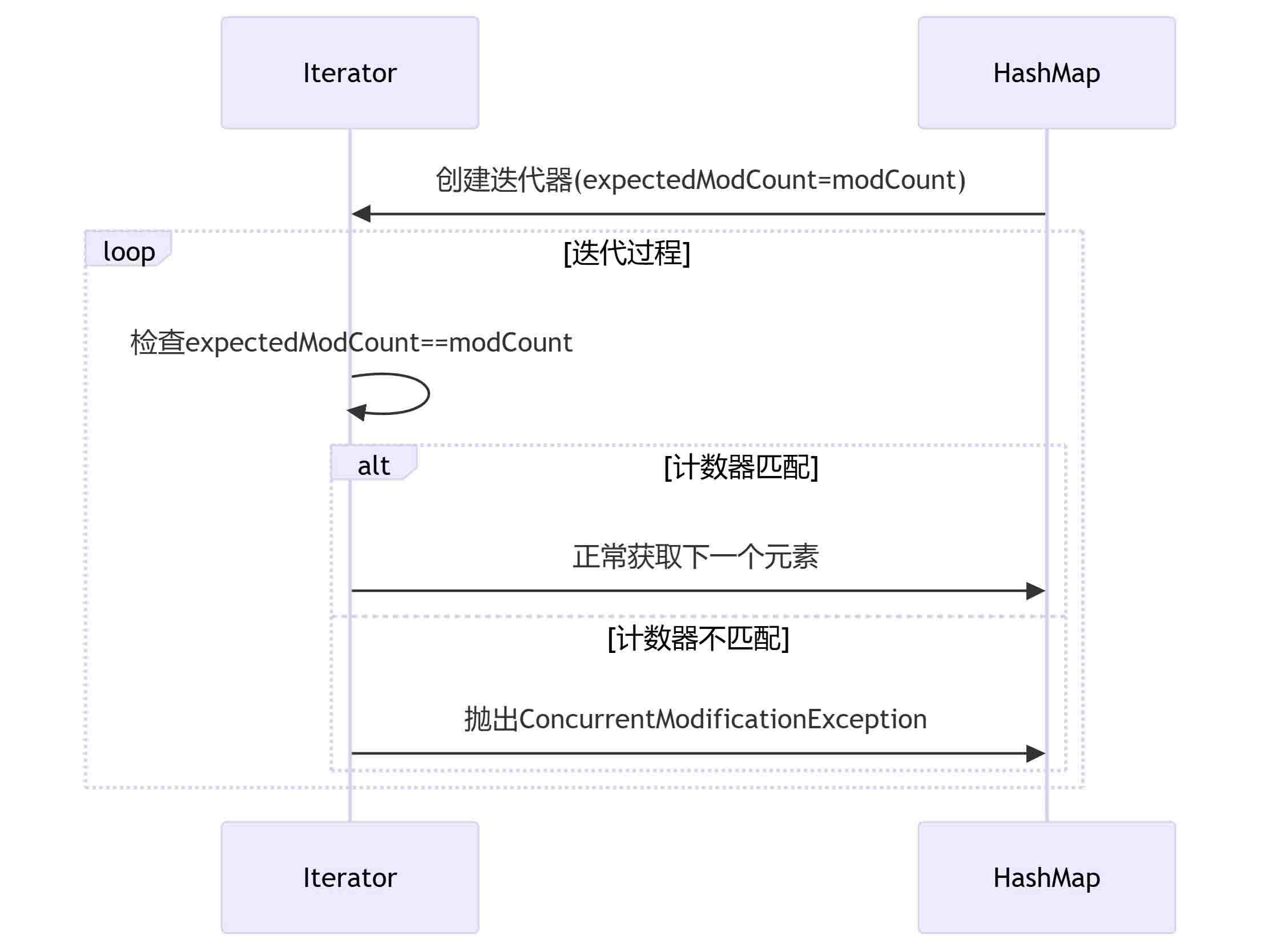
1. 迭代器remove实现
// HashMap.HashIterator.remove()
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount; // 关键点:同步更新!
}关键步骤:
- 检查合法性
- 实际删除节点
- 同步更新expectedModCount
2. 直接put操作
// HashMap.put()
public V put(K key, V value) {
// ...省略其他代码...
++modCount; // 修改计数器增加
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}此时expectedModCount不会更新,导致下次迭代检查时:
// HashIterator.nextNode()
final Node<K,V> nextNode() {
if (modCount != expectedModCount) // 此时不相等!
throw new ConcurrentModificationException();
// ...
}6.3、结构图
比较expectedModCount和ModCount值是否相等。通常在hashmap的clear(),remove(),put()方法里面都会进行modcount++;
如下图所示:
6.4、线程安全
即使单线程环境,两种操作也有本质区别:
迭代器remove:
- 操作路径:迭代器→Map
- 迭代器全程掌握修改控制权
直接修改Map:
- 操作路径:直接访问Map
- 迭代器无法感知外部修改
6.5、开发建议
1. 安全删除模式
// 安全删除示例
List<String> toRemove = new ArrayList<>();
for (Entry<String, Integer> entry : map.entrySet()) {
if (entry.getValue() < 0) {
toRemove.add(entry.getKey());
}
}
toRemove.forEach(map::remove); // 迭代完成后再批量删除2. 多线程替代方案
// 使用ConcurrentHashMap
ConcurrentHashMap<String, Integer> safeMap = new ConcurrentHashMap<>();
// 迭代时修改不会抛异常
for (String key : safeMap.keySet()) {
if (key.startsWith("test")) {
safeMap.remove(key); // 安全操作
}
}6.6、底层设计
契约式设计:
- 迭代器与Map约定:只有通过迭代器的修改才被认可
防御式编程:
- 假设外部修改都可能破坏一致性
- 通过fail-fast快速暴露问题
最小惊讶原则:
- 直接修改集合产生异常符合开发者直觉
- 迭代器提供专用修改方法更安全
这种设计确保了集合在迭代过程中的状态可控性,虽然限制了灵活性,但大幅提高了代码的可靠性。理解这一机制可以帮助开发者避免常见的并发修改错误。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。