
Java JMH进行基准测试的使用小结
作者:终点就在前方
在 Java 的依赖库中,有个大名鼎鼎的 JMH(Java Microbenchmark Harness),是由 Java虚拟机团队开发的 Java 基准测试工具。
在 JMH 中,正如 单元测试框架 JUnit 一样,我们也可以通过大量的注解来进行一定的配置,一个典型的 JMH 程序执行如下图所示[2]:
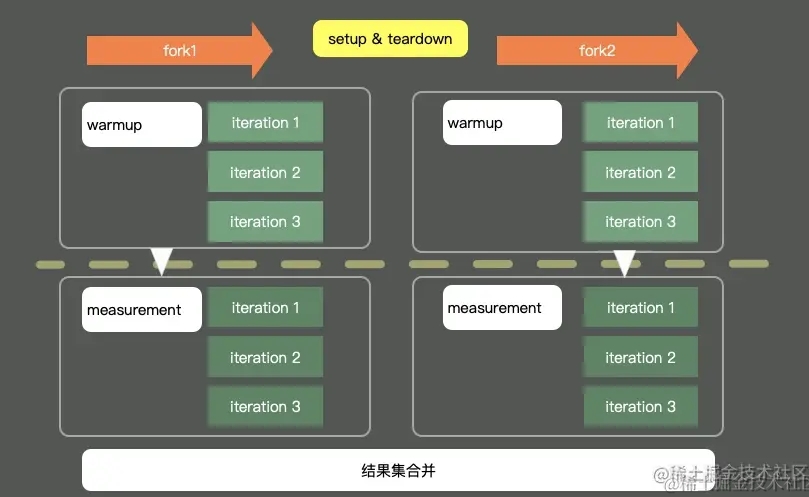
也即,通过开启多个进程,多个线程,先执行预热,然后执行迭代,最后汇总所有的测试数据进行分析,这就是 JMH 的执行流程,听起来是不是不难理解。
1.示例
学习新技能通常先通过一个 case 来帮准我们怎么用,有什么结果,这里我们通过改写官方的一个 sample 来看看。
package org.example;
import org.openjdk.jmh.annotations.Benchmark;
import org.openjdk.jmh.annotations.Measurement;
import org.openjdk.jmh.annotations.Warmup;
import org.openjdk.jmh.results.format.ResultFormatType;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.concurrent.TimeUnit;
@Warmup(iterations = 1, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 2, time = 1, timeUnit = TimeUnit.SECONDS)
public class HelloWorldBenchmark {
private static int num = 0;
@Benchmark
public void helloWorld() {
++num;
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(HelloWorldBenchmark.class.getSimpleName())
.forks(1)
.result("helloWorld.json")
.resultFormat(ResultFormatType.JSON)
.build();
new Runner(opt).run();
}
}示例很简单,就是简单对 static 变量做自增,最后将结果输出到 json 文件中,下面是运行结果:
# JMH version: 1.23 # VM version: JDK 21, Java HotSpot(TM) 64-Bit Server VM, 21+35-LTS-2513 # VM invoker: C:\Program Files\Java\jdk-21\bin\java.exe # VM options: -javaagent:D:\chromedownload\ideaIC-2023.2.3.win\lib\idea_rt.jar=55507:D:\chromedownload\ideaIC-2023.2.3.win\bin -Dfile.encoding=UTF-8 -Dsun.stdout.encoding=UTF-8 -Dsun.stderr.encoding=UTF-8 # Warmup: 1 iterations, 1 s each # Measurement: 2 iterations, 1 s each # Timeout: 10 min per iteration # Threads: 1 thread, will synchronize iterations # Benchmark mode: Throughput, ops/time # Benchmark: org.example.HelloWorldBenchmark.helloWorld # Run progress: 0.00% complete, ETA 00:00:03 # Fork: 1 of 1 # Warmup Iteration 1: 1659899825.872 ops/s Iteration 1: 1646745186.884 ops/s Iteration 2: 1681125023.980 ops/s Result "org.example.HelloWorldBenchmark.helloWorld": 1663935105.432 ops/s # Run complete. Total time: 00:00:03 REMEMBER: The numbers below are just data. To gain reusable insights, you need to follow up on why the numbers are the way they are. Use profilers (see -prof, -lprof), design factorial experiments, perform baseline and negative tests that provide experimental control, make sure the benchmarking environment is safe on JVM/OS/HW level, ask for reviews from the domain experts. Do not assume the numbers tell you what you want them to tell. Benchmark Mode Cnt Score Error Units HelloWorldBenchmark.helloWorld thrpt 2 1663935105.432 ops/s Benchmark result is saved to helloWorld.json
通过简单的设置,我们在基准测试中可以看到多次测试的每秒吞吐量,最后结果输出到 helloWorldjson 文件:
[
{
"jmhVersion" : "1.23",
"benchmark" : "org.example.HelloWorldBenchmark.helloWorld",
"mode" : "thrpt",
"threads" : 1,
"forks" : 1,
"jvm" : "C:\Program Files\Java\jdk-21\bin\java.exe",
"jvmArgs" : [
"-javaagent:D:\chromedownload\ideaIC-2023.2.3.win\lib\idea_rt.jar=55507:D:\chromedownload\ideaIC-2023.2.3.win\bin",
"-Dfile.encoding=UTF-8",
"-Dsun.stdout.encoding=UTF-8",
"-Dsun.stderr.encoding=UTF-8"
],
"jdkVersion" : "21",
"vmName" : "Java HotSpot(TM) 64-Bit Server VM",
"vmVersion" : "21+35-LTS-2513",
"warmupIterations" : 1,
"warmupTime" : "1 s",
"warmupBatchSize" : 1,
"measurementIterations" : 2,
"measurementTime" : "1 s",
"measurementBatchSize" : 1,
"primaryMetric" : {
"score" : 1.6639351054317546E9,
"scoreError" : "NaN",
"scoreConfidence" : [
"NaN",
"NaN"
],
"scorePercentiles" : {
"0.0" : 1.6467451868835843E9,
"50.0" : 1.6639351054317546E9,
"90.0" : 1.6811250239799252E9,
"95.0" : 1.6811250239799252E9,
"99.0" : 1.6811250239799252E9,
"99.9" : 1.6811250239799252E9,
"99.99" : 1.6811250239799252E9,
"99.999" : 1.6811250239799252E9,
"99.9999" : 1.6811250239799252E9,
"100.0" : 1.6811250239799252E9
},
"scoreUnit" : "ops/s",
"rawData" : [
[
1.6467451868835843E9,
1.6811250239799252E9
]
]
},
"secondaryMetrics" : {
}
}
]看完怎么用,接下来看看在项目中注意的点和值得注意的参数注解。
2.JMH的使用
引入依赖
由于这不是标准库有的依赖,所以这里我们依然用 Maven 管理依赖,在我们构建的 Maven 项目中的 pom.xml 添加下列依赖:
<dependencies>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.23</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.23</version>
</dependency>接下来看看代码应用。
代码示例基于参考编写:
package org.example;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.results.format.ResultFormatType;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.concurrent.TimeUnit;
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@State(Scope.Thread)
@Warmup(iterations = 3, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Fork(1)
@Threads(2)
public class MyBenchmarkTest {
@Benchmark
public long shift() {
long t = 455565655225562L;
long a = 0;
for (int i = 0; i < 1000; i++) {
a = t >> 30;
}
return a;
}
@Benchmark
public long div() {
long t = Long.MAX_VALUE;
long a = 0;
for (int i = 0; i < 1000; i++) {
a = t / 1024 / 1024 / 1024;
}
return a;
}
public static void main(String[] args) throws RunnerException {
Options opts = new OptionsBuilder()
.include(MyBenchmarkTest.class.getSimpleName())
.result("MyBenchmarkTest.json")
.resultFormat(ResultFormatType.JSON)
.build();
new Runner(opts).run();
}
}在示例中,其实我们的目的就是测试 移位和整除 两个方法的性能,看看每秒的吞吐量如何,最后将结果汇总在 MyBenchmarkTest.json 文件中,当然运行测试,我们也可以在控制台得到相应输出。
注解
在上面的 demo 中,我们在类上加了很多注解,注解的作用又是啥呢?
@BenchmarkMode
该注解用来指定基准测试类型,对应 Mode 选项,修饰类和方法,这里我们修饰类,注解的 value 是 Mode[] 类型,我们这里填入的是 Throughput ,表示整体吞吐量,即单位时间内的调用量,查看 Mode 源码就可以发现,其实总的类型有以下:
Throughput: 略
AverageTime: 平均耗时,指的是每次执行的平均时间。如果这个值很小不好辨认,可以把统计的单位时间调小一点。
SampleTime: 随机取样。
SingleShotTime: 如果你想要测试仅仅一次的性能,比如第一次初始化花了多长时间,就可以使用这个参数,其实和传统的main方法没有什么区别。
All: 所有的指标,都算一遍。
从 控制台的结果可以看看相关输出:
Benchmark Mode Cnt Score Error Units
MyBenchmarkTest.div thrpt 5 500758.115 ± 3350.796 ops/ms
MyBenchmarkTest.shift thrpt 5 500045.811 ± 1609.779 ops/ms
如果填入 Mode.All 看看结果输出:
Benchmark Mode Cnt Score Error Units
MyBenchmarkTest.div thrpt 5 500554.176 ± 8015.731 ops/ms
MyBenchmarkTest.shift thrpt 5 499731.423 ± 4635.160 ops/ms
MyBenchmarkTest.div avgt 5 ≈ 10⁻⁵ ms/op
MyBenchmarkTest.shift avgt 5 ≈ 10⁻⁵ ms/op
MyBenchmarkTest.div sample 316909 ≈ 10⁻⁴ ms/op
MyBenchmarkTest.div:div·p0.00 sample ≈ 0 ms/op
MyBenchmarkTest.div:div·p0.50 sample ≈ 0 ms/op
MyBenchmarkTest.div:div·p0.90 sample ≈ 10⁻⁴ ms/op
MyBenchmarkTest.div:div·p0.95 sample ≈ 10⁻⁴ ms/op
MyBenchmarkTest.div:div·p0.99 sample ≈ 10⁻⁴ ms/op
MyBenchmarkTest.div:div·p0.999 sample ≈ 10⁻⁴ ms/op
MyBenchmarkTest.div:div·p0.9999 sample 0.002 ms/op
MyBenchmarkTest.div:div·p1.00 sample 0.025 ms/op
MyBenchmarkTest.shift sample 315964 ≈ 10⁻⁴ ms/op
MyBenchmarkTest.shift:shift·p0.00 sample ≈ 0 ms/op
MyBenchmarkTest.shift:shift·p0.50 sample ≈ 0 ms/op
MyBenchmarkTest.shift:shift·p0.90 sample ≈ 10⁻⁴ ms/op
MyBenchmarkTest.shift:shift·p0.95 sample ≈ 10⁻⁴ ms/op
MyBenchmarkTest.shift:shift·p0.99 sample ≈ 10⁻⁴ ms/op
MyBenchmarkTest.shift:shift·p0.999 sample ≈ 10⁻⁴ ms/op
MyBenchmarkTest.shift:shift·p0.9999 sample 0.001 ms/op
MyBenchmarkTest.shift:shift·p1.00 sample 0.024 ms/op
MyBenchmarkTest.div ss 5 0.052 ± 0.091 ms/op
MyBenchmarkTest.shift ss 5 0.015 ± 0.023 ms/op
此时可以看到十分详尽的输出,每秒的吞吐量,每个操作的耗费时间等,因为本例简单,时间耗费建议填入 ns 等单位。
@BenchmarkMode 表示单位时间的操作数或者吞吐量,或者每个操作耗费的时间等,注意我们都没有限定时间单位,所以通常这个注解也会和 @OutputTimeUnit 结合使用。
@OutputTimeUnit
基准测试结果的时间类型。一般选择秒、毫秒、微秒,这里填入的是 TimeUnit 这个枚举类型,涉及单位很多从纳秒到天都有,按需选择,最终输出易读的结果。
@State
@State 指定了在类中变量的作用范围。它有三个取值。
@State 用于声明某个类是一个“状态”,可以用Scope 参数用来表示该状态的共享范围。这个注解必须加在类上,否则提示无法运行。
Scope有如下3种值:
- Benchmark:表示变量的作用范围是某个基准测试类。
- Thread:每个线程一份副本,如果配置了Threads注解,则每个Thread都拥有一份变量,它们互不影响。
- Group:联系上面的@Group注解,在同一个Group里,将会共享同一个变量实例。
本例中,相关变量的作用范围是 Thread。
@Warmup
预热,可以加在类上或者方法上,预热只是测试数据,是不作为测量结果的。
该注解一共有4个参数:
- iterations 预热阶段的迭代数
- time 每次预热时间
- timeUnit 时间单位,通常秒
- batchSize 批处理大小,指定每次操作调用几次方法
本例中,我们加在类上,让它迭代3次,每次1秒,时间单位秒。
@Measurement
和预热类似,这里的注解是会影响测试结果的,它的参数和 Warmup 一样,这里不多介绍。
本例中我们在迭代中设置的是5次,每次1秒。
通常 @Warmup 和 @Measurement 两个参数会一起使用。
@Fork
表示开启几个进程测试,通常我们设为1,如果数值大于1,则启用新的进程测试,如果设置为0,程序依然进行,但是在用户的 JVM 进程上运行。
追踪一下JMH的源码,发现每个fork进程是单独运行在Proccess进程里的,这样就可以做完全的环境隔离,避免交叉影响。它的输入输出流,通过Socket连接的模式,发送到我们的执行终端。
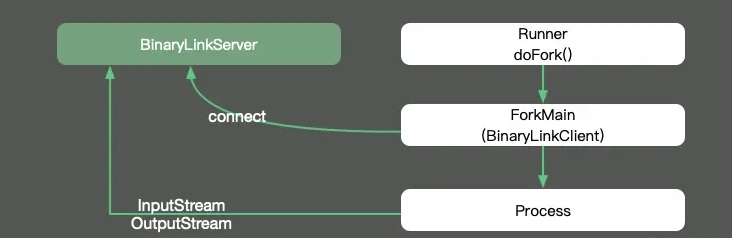
如果需要更多的设置,可以看看 Fork.class 源码,上面还有 jvm 参数设置。
@Threads
上面的注解注重开启几个进程,这里就是开启几个线程,只有一个参数 value,指定注解的value,将会开启并行测试,如果设置的 value 过大,如 Threads.Max,则使用处理机的相同线程数。
@Benchmark
加在测试方法上,表示该方法是需要进行基准测试的,类似 JUnit5 中的 @Test 注解需要单元测试的方法一样。
@Setup
注解的作用就是我们需要在测试之前进行一些准备工作,比如对一些数据的初始化之类的,这个也和Junit的@Before
@Teardown
在测试之后进行一些结束工作,主要用于资源回收
开启测试
上述的学习中主要是相关注解,这里看看具体我们怎么用。
public static void main(String[] args) throws RunnerException {
Options opts = new OptionsBuilder()
// 表示包含的测试类
.include(MyBenchmarkTest.class.getSimpleName())
// 最后结果输出文件的命名
.result("MyBenchmarkTest.json")
// 结果输出什么格式,可以是json, csv, text等
.resultFormat(ResultFormatType.JSON)
.build();
new Runner(opts).run(); // 运行
}3.JMH可视化
作为程序开发人员,看懂测试结果没难度,测试结果文本能可视化更好。
好在我们拿到了JMH 结果后,根据文件格式,我们可以二次加工,就可以图表化展示[2]。
JMH 支持的几种输出格式:
- TEXT 导出文本文件。
- CSV 导出csv格式文件。
- SCSV 导出scsv等格式的文件。
- JSON 导出成json文件。
- LATEX 导出到latex,一种基于ΤΕΧ的排版系统。
到此这篇关于Java JMH进行基准测试的使用小结的文章就介绍到这了,更多相关Java JMH基准测试内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!