
简单分析JDK中「SPI」的原理
作者:七号楼
一、SPI简介
1、概念
SPI即service-provider-interface的简写;
JDK内置的服务提供加载机制,可以为服务接口加载实现类,解耦是其核心思想,也是很多框架和组件的常用手段;
2、入门案例
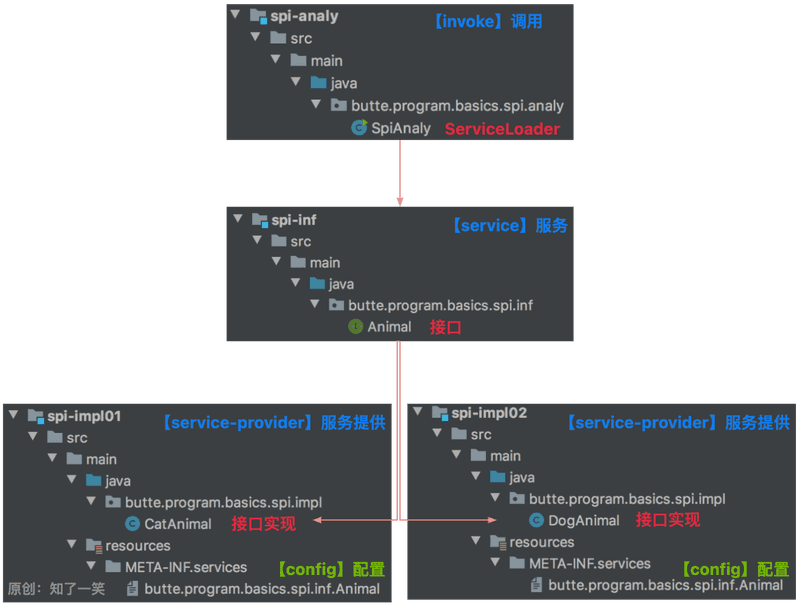
2.1 定义接口
就是普通的接口,在SPI的机制中称为【service】,即服务;
public interface Animal {
String animalName () ;
}
2.2 两个实现类
提供两个模拟用来测试,就是普通的接口实现类,在SPI的机制中称为【service-provider】即服务提供方;
CatAnimal实现类;
public class CatAnimal implements Animal {
@Override
public String animalName() {
System.out.println("Cat-Animal:布偶猫");
return "Ragdoll";
}
}
DogAnimal实现类;
public class DogAnimal implements Animal {
@Override
public String animalName() {
System.out.println("Dog-Animal:哈士奇");
return "husky";
}
}
2.3 配置文件
文件目录:在代码工程中创建META-INF.services文件夹;
文件命名:butte.program.basics.spi.inf.Animal,即全限定接口名称;
文件内容:添加相应实现类的全限定命名;
butte.program.basics.spi.impl.CatAnimal butte.program.basics.spi.impl.DogAnimal
2.4 测试代码
通过ServiceLoader加载配置文件中指定的服务实现类,然后遍历并调用Animal接口方法,从而执行不同服务提供方的具体逻辑;
public class SpiAnaly {
public static void main(String[] args) {
ServiceLoader<Animal> serviceLoader = ServiceLoader.load(Animal.class);
Iterator<Animal> animalIterator = serviceLoader.iterator();
while(animalIterator.hasNext()) {
Animal animal = animalIterator.next();
System.out.println("animal-name:" + animal.animalName());
}
}
}
结果输出
Cat-Animal:布偶猫 \n animal-name:ragdoll Dog-Animal:哈士奇 \n animal-name:husky
二、原理分析
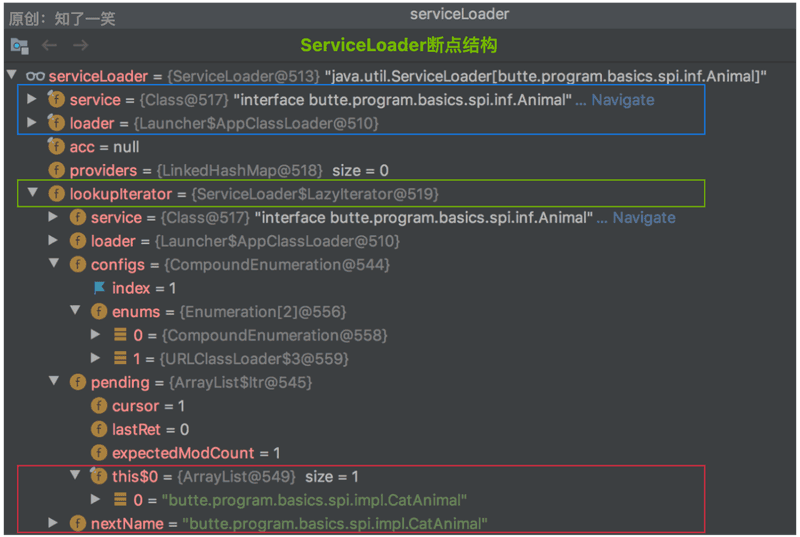
1、ServiceLoader结构
很显然,分析SPI机制的原理,从ServiceLoader源码中load方法切入即可,但是需要先从核心类的结构开始分析;
public final class ServiceLoader<S> implements Iterable<S> {
// 配置文件目录
private static final String PREFIX = "META-INF/services/";
// 表示正在加载的服务的类或接口
private final Class<S> service;
// 类加载器用来定位,加载,实例化服务提供方
private final ClassLoader loader;
// 创建ServiceLoader时采用的访问控制上下文
private final AccessControlContext acc;
// 按实例化的顺序缓存服务提供方
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
// 惰性查找迭代器
private LazyIterator lookupIterator;
/**
* service:表示服务的接口或抽象类
* loader: 类加载器
*/
public static <S> ServiceLoader<S> load(Class<S> service) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
/**
* ServiceLoader构造方法
*/
private ServiceLoader(Class<S> svc, ClassLoader cl) {
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
reload();
}
public void reload() {
providers.clear();
// 实例化迭代器
lookupIterator = new LazyIterator(service, loader);
}
public static <S> ServiceLoader<S> load(Class<S> service,ClassLoader loader) {
return new ServiceLoader<>(service, loader);
}
private class LazyIterator implements Iterator<S> {
// 服务接口
Class<S> service;
// 类加载器
ClassLoader loader;
// 实现类URL
Enumeration<URL> configs = null;
// 实现类全名
Iterator<String> pending = null;
// 下个实现类全名
String nextName = null;
}
}
断点截图:
2、iterator迭代方法
在ServiceLoader类的迭代器方法中,实际使用的是LazyIterator内部类的方法;
public Iterator<S> iterator() {
return new Iterator<S>() {
Iterator<Map.Entry<String,S>> knownProviders = providers.entrySet().iterator();
public boolean hasNext() {
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}
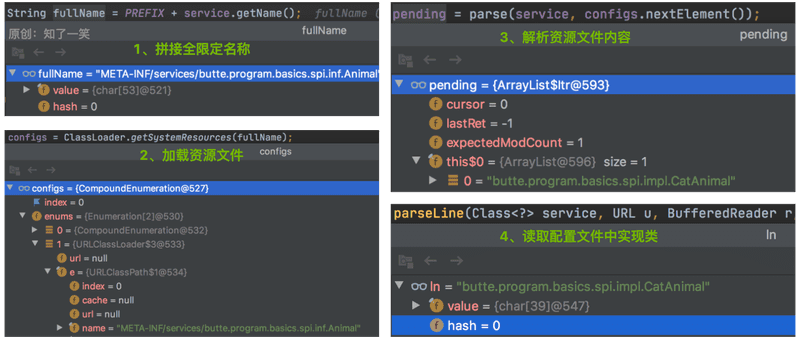
3、hasNextService方法
从上面迭代方法的源码中可知,最终执行的是LazyIterator#hasNextService判断方法,该方法通过解析最终会得到实现类的全限定名称;
private class LazyIterator implements Iterator<S> {
private boolean hasNextService() {
// 1、拼接名称
String fullName = PREFIX + service.getName();
// 2、加载资源文件
configs = loader.getResources(fullName);
// 3、解析文件内容
pending = parse(service, configs.nextElement());
nextName = pending.next();
return true;
}
}
断点截图:
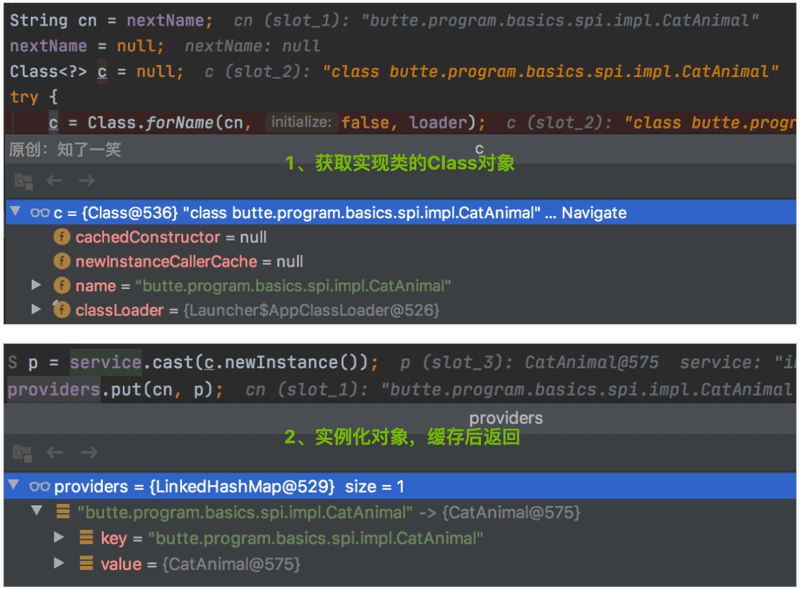
4、nextService方法
迭代器的next方法最终执行的是LazyIterator#nextService获取方法,会基于上面hasNextService方法获取的实现类全限定名称,获取其Class对象,进而得到实例化对象,缓存并返回;
private class LazyIterator implements Iterator<S> {
private S nextService() {
// 1、通过全限定命名获取Class对象
String cn = nextName;
Class<?> c = Class.forName(cn, false, loader);
// 2、实例化对象
S p = service.cast(c.newInstance());
// 3、放入缓存并返回该对象
providers.put(cn, p);
return p;
}
}
断点截图:
三、SPI实践
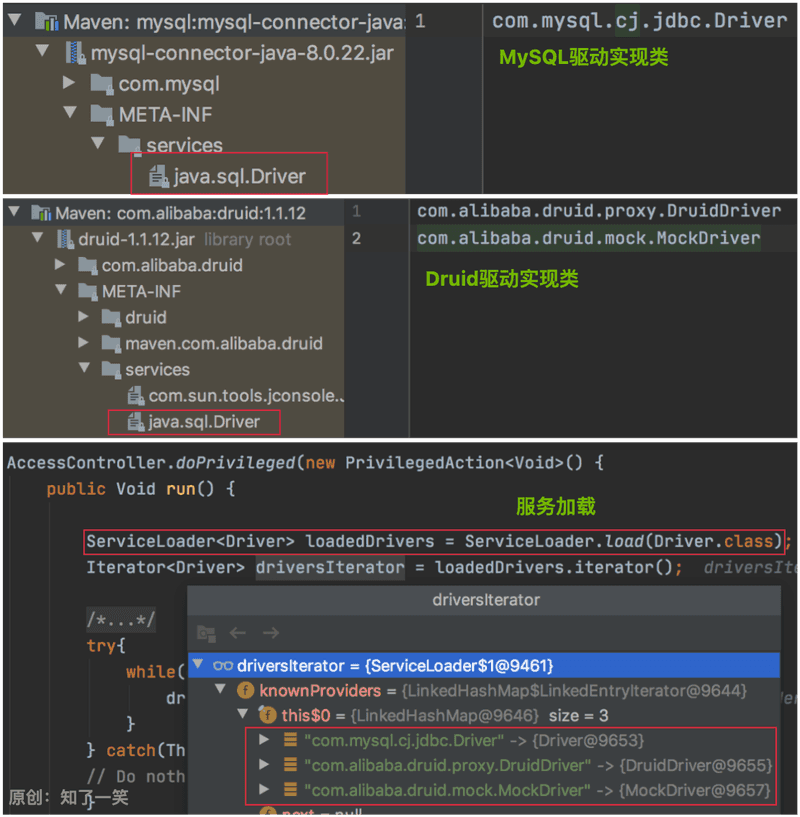
1、Driver驱动接口
在JDK中提供了数据库驱动接口java.sql.Driver,无论是MySQL驱动包还是Druid连接池,都提供了该接口的实现类,通过SPI机制可以加载到这些驱动实现类;
public class DriverManager {
private static void loadInitialDrivers() {
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(java.sql.Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
}
});
}
}
断点截图:
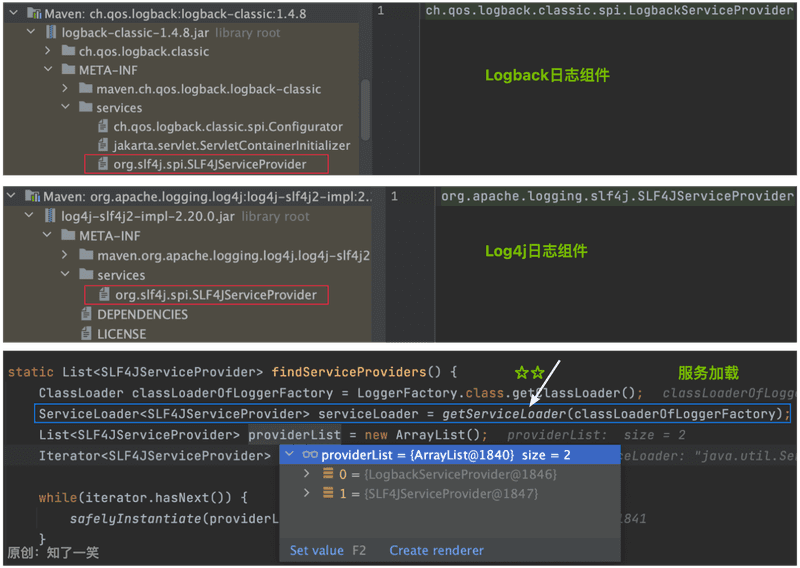
2、Slf4j日志接口
SLF4J是门面模式的日志组件,提供了标准的日志服务SLF4JServiceProvider接口,在LogFactory日志工厂类中,负责加载具体的日志实现类,比如常用的Log4j或Logback日志组件;
public final class LoggerFactory { static List<SLF4JServiceProvider> findServiceProviders() { // 服务加载 ClassLoader classLoaderOfLoggerFactory = org.slf4j.LoggerFactory.class.getClassLoader(); // 重点看该方法:【getServiceLoader()】 ServiceLoader<SLF4JServiceProvider> serviceLoader = getServiceLoader(classLoaderOfLoggerFactory); // 迭代方法 List<SLF4JServiceProvider> providerList = new ArrayList(); Iterator<SLF4JServiceProvider> iterator = serviceLoader.iterator(); while(iterator.hasNext()) { safelyInstantiate(providerList, iterator); } return providerList; } }
断点截图:
到此这篇关于简单分析JDK中「SPI」的原理的文章就介绍到这了,更多相关JDK中「SPI」的原理内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!