
关于ZooKeeper原理剖析
作者:Hello.Reader
1. ZooKeeper简介
ZooKeeper是一个分布式、高可用性的协调服务。在大数据产品中主要提供两个功能:
- 帮助系统避免单点故障,建立可靠的应用程序。
- 提供分布式协作服务和维护配置信息。
2. ZooKeeper结构
ZooKeeper集群中的节点分为三种角色:Leader、Follower和Observer,其结构和相互关系如下图所示。通常来说,需要在集群中配置奇数个(2N+1)ZooKeeper服务,至少(N+1)个投票才能成功的执行写操作。
ZooKeeper结构
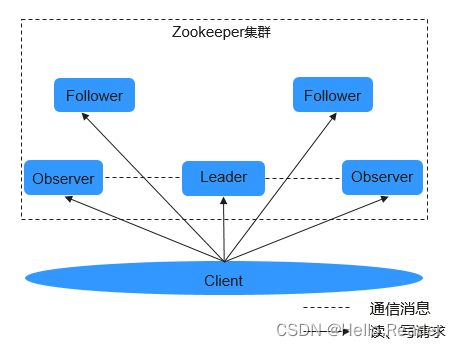
上图中各部分的功能说明如下表所示。
| 名称 | 描述 |
|---|---|
| Leader | 在ZooKeeper集群中只有一个节点作为集群的领导者,由各Follower通过ZooKeeper Atomic Broadcast(ZAB)协议选举产生,主要负责接收和协调所有写请求,并把写入的信息同步到Follower和Observer。 |
| Follower | Follower的功能有两个:1.每个Follower都作为Leader的储备,当Leader故障时重新选举Leader,避免单点故障。2.处理读请求,并配合Leader一起进行写请求处理。 |
| Observer | Observer不参与选举和写请求的投票,只负责处理读请求、并向Leader转发写请求,避免系统处理能力浪费。 |
| Client | ZooKeeper集群的客户端,对ZooKeeper集群进行读写操作。例如HBase可以作为ZooKeeper集群的客户端,利用ZooKeeper集群的仲裁功能,控制其HMaster的“Active”和“Standby”状态。 |
如果集群启用了安全服务,在连接ZooKeeper时需要进行身份认证,认证方式有以下两种:
- keytab方式:需要从MRS集群管理员处获取一个“人机”用户,用于登录MRS平台并通过认证,并且获取到该用户的keytab文件。
- 票据方式:从MRS集群管理员处获取一个“人机”用户,用于后续的安全登录,开启Kerberos服务的renewable和forwardable开关并且设置票据刷新周期,开启成功后重启kerberos及相关组件。
注意:
- 默认情况下,用户的密码有效期是90天,所以获取的keytab文件的有效期是90天。
- Kerberos服务的renewable、forwardable开关和票据刷新周期的设置在Kerberos服务的配置页面的“系统”标签下,票据刷新周期的修改可以根据实际情况修改“kdc_renew_lifetime”和“kdc_max_renewable_life”的值。
3. ZooKeeper原理
写请求
- Follower或Observer接收到写请求后,转发给Leader。
- Leader协调各Follower,通过投票机制决定是否接受该写请求。
- 如果超过半数以上的Leader、Follower节点返回写入成功,那么Leader提交该请求并返回成功,否则返回失败。
- Follower或Observer返回写请求处理结果。
只读请求
- 客户端直接向Leader、Follower或Observer读取数据。
4. ZooKeeper和HDFS的关系
ZooKeeper与HDFS的关系如下图所示。
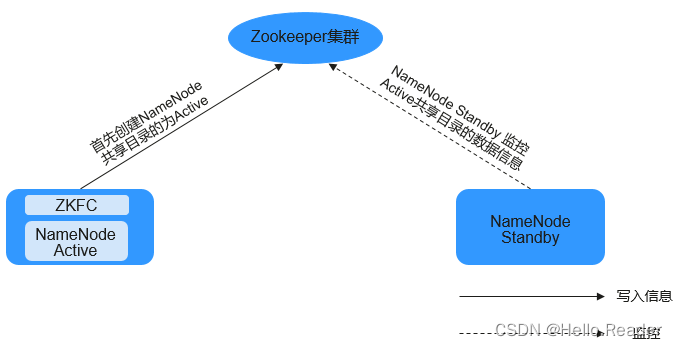
ZKFC(ZKFailoverController)作为一个ZooKeeper集群的客户端,用来监控NameNode的状态信息。ZKFC进程仅在部署了NameNode的节点中存在。HDFS NameNode的Active和Standby节点均部署有zkfc进程。
- HDFS NameNode的ZKFC连接到ZooKeeper,把主机名等信息保存到ZooKeeper中,即“/hadoop-ha”下的znode目录里。先创建znode目录的NameNode节点为主节点,另一个为备节点。HDFS NameNode Standby通过ZooKeeper定时读取NameNode信息。
- 当主节点进程异常结束时,HDFS NameNode Standby通过ZooKeeper感知“/hadoop-ha”目录下发生了变化,NameNode会进行主备切换。
5. ZooKeeper和YARN的关系
ZooKeeper与YARN的关系如下图所示。
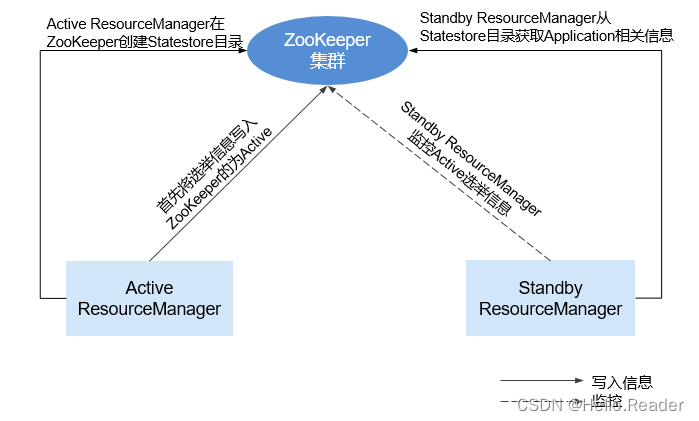
- 在系统启动时,ResourceManager会尝试把选举信息写入ZooKeeper,第一个成功写入ZooKeeper的ResourceManager被选举为Active ResourceManager,另一个为Standby ResourceManager。Standby ResourceManager定时去ZooKeeper监控Active ResourceManager选举信息。
- Active ResourceManager还会在ZooKeeper中创建Statestore目录,存储Application相关信息。当Active ResourceManager产生故障时,Standby ResourceManager会从Statestore目录获取Application相关信息,恢复数据。
6. ZooKeeper和HBase的关系
ZooKeeper与HBase的关系如下图所示。
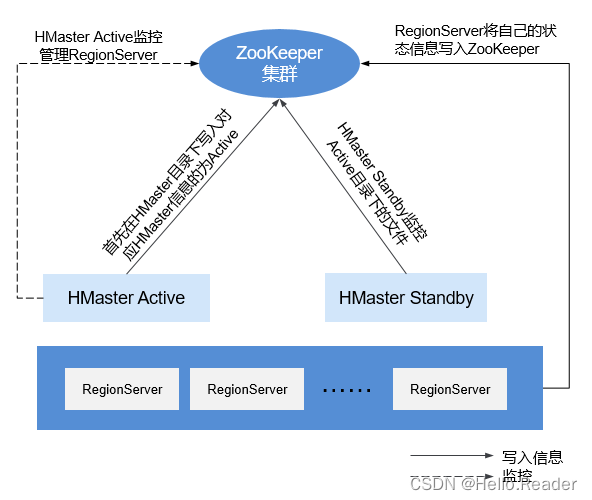
- HRegionServer以Ephemeral node的方式注册到ZooKeeper中。其中ZooKeeper存储HBase的如下信息:HBase元数据、HMaster地址。
- HMaster通过ZooKeeper随时感知各个HRegionServer的健康状况,以便进行控制管理。
- .HBase也可以部署多个HMaster,类似HDFS NameNode,当HMaster主节点出现故障时,HMaster备用节点会通过ZooKeeper获取主HMaster存储的整个HBase集群状态信息。即通过ZooKeeper实现避免HBase单点故障问题的问题。
7. Zookeeper和SmallFS的配合关系
FGCService的部署模式为HA模式。HA(High Availability)模式目的是防止单节点故障导致服务不可用。为了支持HA模式,FGCService依赖于ZooKeeper。
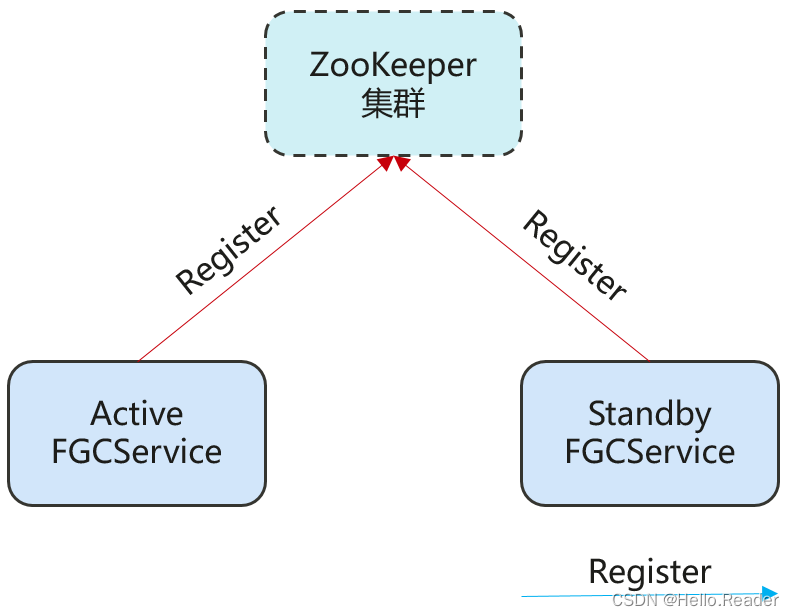
8. ZooKeeper和Kafka的配合关系
ZooKeeper与Kafka的关系如下图 ZooKeeper和Kafka的关系所示。
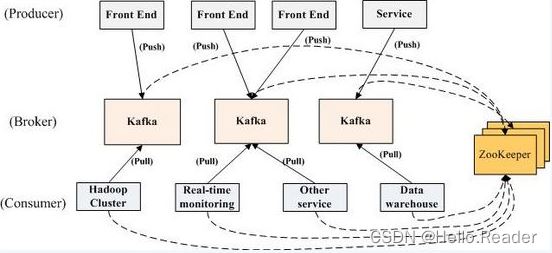
Broker端使用ZooKeeper用来注册broker信息,并进行partition leader选举Consumer端使用ZooKeeper用来注册consumer信息,其中包括consumer·消费的partition列表等,同时也用来发现broker列表,并和partition leader建立socket连接,并获取消息。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。