
一文梳理Java超大型文件读取的18种方法和性能
作者:五阳
Java 读取超大文本文件最快速、最可靠的方式是哪几种?
网上相当多的文档都存在错误,不要轻信。如乱码问题、半读问题、资源泄露、性能问题、内存溢出问题!
如果面试问到这个问题,也许 10 个人中仅有 1 个人能写出合格的代码!虽然Java 程序员不经常遇到文件读写场景,但这是一个优秀程序员的基本功。
首先列出测评结论,稍后给出详细介绍和代码。 建议收藏慢慢看~
性能评测结果
1 按字节(字符)读取
InputStreamReader+ BufferedReader 方式较好,推荐使用。
| 序号 | 方式 | 耗时 (秒) | 备注 |
|---|---|---|---|
| 1 | Files.readAllBytes (字节) | 1.2384915 | 一次性加载到内存,存在 OOM 风险。且不支持指定字符编码,存在乱码问题 |
| 2 | 推荐 InputStreamReader+ BufferedReader (字符) | 0.987749583 | 性能最好,无 OOM 风险,大小文件均适合。且支持指定字符编码 |
| 3 | FileReader + BufferedReader (字符) | 1.058886583 | 性能较好,但不支持指定字符编码,存在乱码问题,不推荐使用! |
| 4 | Scanner | / | 不支持按字符读取 |
| 5 | RandomAccessFile (字节) | 0.374973291 | 仅支持按字节读取,不支持字符读取,因此不推荐读取文本文件 |
| 6 | Guava Files | / | 不支持按字符读取 |
| 7 | FileChannel + ByteBuffer + CharBuffer (字节,字符) | 0.852993416 | 支持指定字符编码,性能虽好,但不如 BIO 方式。并且代码非常复杂,容易出错,谨慎使用 |
| 8 | FileChannel + 直接内存(字节,字符) | 3.082011625 | 支持指定字符编码,读取文本文件到堆内存的使用场景,不推荐使用直接内存,并且性能较差 |
| 9 | FileChannel + MappedByteBuffer | 4.111039792 | 支持指定字符编码,读取文本文件到堆内存的使用场景,不推荐使用内存映射,并且性能较差 |
2 按行读取
推荐三种方式
- Files.lines
- InputStreamReader+ BufferedReader
- Guava Files.readLines
| 序号 | 方式 | 耗时 | 备注 |
|---|---|---|---|
| 1.1 | Files.readAllLines | 3.154415958 | 内部按行读取参考 BufferedReader,然而需要将全部数据存放到 List 中,存在 GC 压力 |
| 1.2 | 推荐 Files.lines | 2.486005583 | 内部通过BufferedReader实现按行读取,无需全部数据到内存,每次循环处理前读取文件,无GC 压力。使用方式简单 |
| 1.3 | common-io FileUtils.readLines | 3.59483125 | 内部实现原理和 Files.readAllLines相同 |
| 2 | 推荐 InputStreamReader+ BufferedReader | 2.549001042 | 支持指定字符编码,性能较好,很多工具类均依赖此类实现按行读取 |
| 3 | FileReader + BufferedReader | 2.433327333 | 不支持指定字符编码,存在乱码问题,不推荐使用 |
| 4 | Scanner | 15.108729042 | 支持指定字符编码,性能极差,适合读取小文件和正则表达式扫描读取文件 |
| 5 | RandomAccessFile | 699.56510667 | 不支持指定字符编码,存在乱码问题,性能极差。不推荐使用 |
| 6 | 推荐 Guava Files.readLines | 3.248319917 秒 | 支持指定字符编码,无需全部读取后进行业务处理,性能较好,使用简单,无需释放 IO 流 |
| 7 | FileChannel + ByteBuffer+ CharBuffer | 3.10733875 | 支持指定字符编码,性能较好,但使用方式复杂。这是因为需要处理半读问题,自行处理按行读取问题 |
| 8 | FileChannel + 直接内存 | 7.09936925 | 支持指定字符编码,性能较差。使用方式复杂。这是因为需要处理半读问题,自行处理按行读取问题 |
| 9 | FileChannel + MappedByteBuffer | 8.264657084 | 支持指定字符编码,性能较差。使用方式复杂。这是因为需要处理半读问题,自行处理按行读取问题 |
接下来,五阳将介绍读取文件的几种方式!
0. 前期准备工作
0.1 文件读取方式
大部分情况下,文件读取包含以下两种形式。
- 按行读取字符文件
- 按字节读取文件
0.2 生成大文件
为了测试大文件读取的性能,需要生成一个大文件!
以下命令在 Mac下测试通过,它可以随机生成 字符文件,1500000 行,每行 1000 个字符,文件大小约 1.4G。
cat /dev/urandom | LC_ALL=C tr -dc 'a-zA-Z0-9' | fold -w 1000 | head -n 1500000 > random.txt
生成文件后,发现该文件字符集为 us-ascii 编码。因为在实际开发中经常遇到文件读取乱码问题,如果文件包含中文,若文件读取代码块未正确处理编码,就会有问题。
因此我在文件中手动补充 稀土掘金 4 个汉字方便排查乱码 bug,保存文件后,文件字符编码为 UTF-8。
0.3 JVM 配置
- java 8
- JVM 新生代 4G,堆大小 6G
- 最大堆外内存 2g
JVM 启动参数如下,其中 -Xloggc 参数指定将记录GC 日志文件路径。
-Xmx6g -Xms6g -XX:SurvivorRatio=8 -Xmn4g -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=1g -XX:MaxDirectMemorySize=2g -XX:+HeapDumpOnOutOfMemoryError -XX:+PrintGCCause -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -XX:+UnlockDiagnosticVMOptions -XX:ParGCCardsPerStrideChunk=32768 -XX:+PrintCommandLineFlags -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:ParallelCMSThreads=6 -XX:+CMSClassUnloadingEnabled -XX:+UseCMSCompactAtFullCollection -XX:+CMSParallelInitialMarkEnabled -XX:+CMSParallelRemarkEnabled -XX:+CMSScavengeBeforeRemark -XX:+PrintHeapAtGC -XX:CMSFullGCsBeforeCompaction=1 -XX:CMSInitiatingOccupancyFraction=70 -XX:+UseCMSInitiatingOccupancyOnly -XX:+PrintReferenceGC -XX:+ParallelRefProcEnabled -XX:ReservedCodeCacheSize=256M -Xloggc:/Users/user/log/gc.log
1. 一次性加载文件
通过 java.nio.file.Files 一次性将文件内容读取到内存,使用此种方式适合读取小文件。Files 提供了两种方式,字节方式和按行读取方式。 由于封装了文件读取操作,使用方无需关闭 Channel、File、InputStream ,不存在遗漏关闭文件的风险,似乎 File 非常简洁安全,然而并非如此(后面有讨论!)
1.1 按字节读取文件
Files.readAllBytes(path) 一次性加载字节数组到 JVM 堆内存中。
StopWatch stopWatch = new StopWatch();
stopWatch.start();
Path path = Paths.get(FILE_NAME_1400M);
byte[] bytes = Files.readAllBytes(path);
stopWatch.stop();
String msg = String.format("文件字节长度:%s,耗时:%s秒", bytes.length, stopWatch.getTotalTimeSeconds());
System.out.println(msg);
输出 文件字节长度:1501500012,耗时:1.2384915秒
由于此种方式是一次性将文件读取到内存中,要注意它仅适合读取小文件,如果目标文件是大文件,可能会出现 OOM。
1.2 堆外内存
Java 在读取文件时,会首先将文件内存读取到 堆外内存,再从堆外内存拷贝到堆内存。
为什么呢?
因为JVM 在调用操作系统 API 读取文件时,需要指定内存地址。如果该内存地址指向的是Java堆内内存的话,那么如果操作系统正在访问这个内存地址的时候,Java在这个时候进行了GC操作,而GC操作会涉及到对象移动操作。GC 完成后,将导致传递给操作系统的内存地址并非 GC后的对象地址,进而导致无法预期的行为! 例如GC时对象从Eden区移动到 Survivor区,或者被拷贝到老年代。
而 堆外的直接内存是 JVM 从操作系统 malloc 申请的内存,不在堆内,不会有 GC,不存在被 GC 移动地址的情况!所以堆外内存地址传递给操作系统是可靠的!(虽然多一次的内存拷贝,导致性能存在损耗)
因此如果需要将文件读取到堆内存,首先 JVM 会将其读取到堆外直接内存。 如果堆外直接内存空间不足,就会出现 OOM 异常。
我遇到了如下的异常堆栈问题。起初我在设置 JVM 启动参数时,指定了 -XX:MaxDirectMemorySize=1g,也就是将最大堆外内存限制为 1G。但由于文件大小达 1.4 G,导致程序出现OOM 异常。后来我将堆外内存的上限提高到 2G,问题便得以解决。 然而第一次读取顺利,但是第二次读取时依然出现了直接内存不足的问题。
猜测是因为直接内存分配后没有被及时释放,导致了内存泄露!果不其然,当粗略追踪了JDK代码,我发现 jdk 在申请直接内存用来读取文件后,并没有释放直接内存,而是保存在线程局部变量中用来复用。申请的直接内存较小时,问题不明显。但是一旦当直接内存过大时,会出现明显的内存泄漏!
java.lang.OutOfMemoryError: Direct buffer memory at java.nio.Bits.reserveMemory(Bits.java:695) at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123) at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:311) at sun.nio.ch.Util.getTemporaryDirectBuffer(Util.java:241) at sun.nio.ch.IOUtil.read(IOUtil.java:195) at sun.nio.ch.FileChannelImpl.read(FileChannelImpl.java:159) at sun.nio.ch.ChannelInputStream.read(ChannelInputStream.java:65) at sun.nio.ch.ChannelInputStream.read(ChannelInputStream.java:109) at sun.nio.ch.ChannelInputStream.read(ChannelInputStream.java:103) at java.nio.file.Files.read(Files.java:3105) at java.nio.file.Files.readAllBytes(Files.java:3158)
这表明程序在尝试分配直接内存时,直接内存不足,导致内存溢出错误。
1.3 Files.readAllLines 一次性按行读取
内部实现时委托了 BufferedReader(第二节会介绍) 按行读取,读取的数据按行放在 List 中,因此存在较大的 GC 压力,对于超大文件,有 OOM 风险。
List<String> lines = Files.readAllLines(path, StandardCharsets.UTF_8);
StopWatch stopWatch = new StopWatch();
stopWatch.start();
Path path = Paths.get(FILE_NAME_1400M);
List<String> lines = Files.readAllLines(path, StandardCharsets.UTF_8);
stopWatch.stop();
String msg = String.format("文件行数:%s,耗时:%s秒", lines.size(), stopWatch.getTotalTimeSeconds());
System.out.println(msg);
输出 文件行数:1500000,耗时:3.154415958秒 耗时 3.15 秒,比按字节方式(1.2 秒)读取慢!
1.4 Files.lines 分行读取
JDK 自带的 Files 类不仅提供了将所有数据加载到内存中的文件读取方法,还提供了 Files.lines 方法。该方法实现了 Itemator 的迭代接口,使得每次循环时才逐行读取文件,不会将所有行全部加载到内存中再进行业务处理。
StopWatch stopWatch = new StopWatch();
stopWatch.start();
Path path = Paths.get(FILE_NAME_1400M);
AtomicLong lineNum = new AtomicLong(0);
AtomicLong sum = new AtomicLong(0);
try (Stream<String> stream = Files.lines(path, StandardCharsets.UTF_8);) {
stream.forEach((c) -> {
// 业务逻辑处理
sum.addAndGet(c.length());
lineNum.incrementAndGet();
});
}
stopWatch.stop();
String msg = String.format("文件字符数:%s, 文件行数:%s,耗时:%s秒", sum.get(), lineNum.get(), stopWatch.getTotalTimeSeconds());
System.out.println(msg);
输出:文件字符数:1500000004, 文件行数:1500000,耗时:2.486005583
在 stream.forEach() 方法中统计行数和字符数。
以下代码片段展示了 Files.lines 方法的内部实现。Files.lines 返回一个 Stream,该流内部封装了一个迭代器 Iterator。在通过 Stream 进行循环处理时,每次循环之前都会按行读取文件。
public Stream<String> lines() {
Iterator<String> iter = new Iterator<String>() {
String nextLine = null;
@Override
public boolean hasNext() {
if (nextLine != null) {
return true;
} else {
try {
nextLine = readLine();
return (nextLine != null);
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
}
@Override
public String next() {
if (nextLine != null || hasNext()) {
String line = nextLine;
nextLine = null;
return line;
} else {
throw new NoSuchElementException();
}
}
};
return StreamSupport.stream(Spliterators.spliteratorUnknownSize(
iter, Spliterator.ORDERED | Spliterator.NONNULL), false);
}
对于超大文件,直接将所有数据读取到内存中可能会带来 OOM 风险和 GC 压力。而使用 Files.lines 方法则无需在读取过程中将所有数据加载到内存后再进行业务处理,因此是一种更为有效的方案。
需要特别注意的是,Files.lines 返回的 Stream 内部包含了 BufferedReader 等 IO 流,这些流在读取完文件后需要关闭。此外,Files.lines 创建的 Stream 也不支持二次读取。因此,应通过使用 try-with-resources 代码块来确保 IO 流在使用完毕后被正确关闭。
// 自动关闭 io 流
try (Stream<String> stream = Files.lines(path, StandardCharsets.UTF_8);) {
stream.forEach((lineData) -> {
//处理业务逻辑
});
}
1.5 common-io FileUtils 按行读取
在 common-io 代码库中,FileUtils 提供了按行读取、一次返回全部行数据的能力。其实现原理 1.3节 中的 Files 类似,因此两者的性能基本相当。考虑到这一点,建议优先使用 JDK 自带的 Files 类,避免引入额外的外部代码库。
StopWatch stopWatch = new StopWatch();
stopWatch.start();
File file = new File(FILE_NAME_1400M);
List<String> lines = org.apache.commons.io.FileUtils.readLines(file, "UTF-8");
stopWatch.stop();
String msg = String.format("文件行数:%s,耗时:%s秒", lines.size(), stopWatch.getTotalTimeSeconds());
System.out.println(msg);
输出:文件行数:1500000,耗时:3.59483125秒
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-io</artifactId>
<version>1.3.2</version>
</dependency>
2. InputStreamReader + BufferedReader
BufferedReader 方式提供了 字节和按行读取两种方式。如果是字节方式,需要使用方指定 char 缓冲区大小,缓冲区大小决定了读取性能。
2.1 按字符方式读取代码示例
StopWatch stopWatch = new StopWatch();
stopWatch.start();
File file = new File(FILE_NAME_1400M);
try (FileInputStream fileInputStream = new FileInputStream(file);
InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream, StandardCharsets.UTF_8);
BufferedReader reader = new BufferedReader(inputStreamReader, 1 * 1024 * 1024);) {
char[] chars = new char[1024 * 1024 * 1];
int n = 0;
int sum = 0;
while ((n = reader.read(chars)) > 0) {
sum += n;
}
stopWatch.stop();
System.out.println("文件字符长度:" + sum + ": 时间:" + stopWatch.getTotalTimeSeconds());
}
输出 文件字符长度:1501500004: 时间:0.987749583
为什么字符长度是 1501500004? 因为每行 1000 个字符,行末尾包含一个换行符,所以一共 1501500000,我在文件开头手动添加了 4 个汉字,所以总字符数在 1501500004。 每个汉字 共 3 个字节,所以文件的总字节数 是1501500012。
代码解读
- 可以将 FileInputStream、BufferedReader等 需要关闭的流对象,放在 try () 代码块中,JVM会自动调用 close 方法关闭流。这样做代码更加简洁和安全。
- BufferedReader 需要声明缓冲区大小。 其中 BufferedReader 中缓冲区大小是指 JVM 调用操作系统读取文件时的每批次大小。 而 BufferReader#read 的缓冲区大小,是指开发者指定从 BufferedReader 中每次读取多少数据。可以指定两者为相同值。(建议设置为 1M 即可,不要太大或太小)
- BufferedReader#read 方法返回了读取的字符数量,如到达文件末尾会返回-1。通过 sum+= n 即可获取读取的字符数。会出现读取的字符数小于 char 缓冲区大小的情况,要注意这个问题,避免读取无效数据!
- InputStreamReader 指定了字符集! 读取字符文件一定要声明字符文件的编码,不然遇到中文一定会出现编码问题。
因为 中文编码使用 UTF-8 时,是变长的,如稀土掘金一共 12 个字节,每个汉字 3 字节。如果按照 ASCII 方式读取,将读取 12 个字符,就会出现乱码问题!
后续的其他文件读取模版也会出现乱码问题,届时我再提醒大家注意!
2.2 按行读取文件示例
BufferedReader.readLine() 按行读取文件
StopWatch stopWatch = new StopWatch();
stopWatch.start();
File file = new File(FILE_NAME_1400M);
try (FileInputStream fileInputStream = new FileInputStream(file); InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream, StandardCharsets.UTF_8); BufferedReader reader = new BufferedReader(inputStreamReader, 1 * 1024 * 1024);) {
int lineNum = 0;
for (; ; ) {
String str = reader.readLine();
if (str == null) {
break;
}
lineNum++;
}
stopWatch.stop();
System.out.println("文件行数:" + lineNum + ": 时间:" + stopWatch.getTotalTimeSeconds());
}
输出 文件行数:1500000: 时间: 2.549001042秒 比按字节方式(0.98 秒)读取慢!
3. FileReader + BufferedReader
FileReader 的构造方法无法指定字符集,其内部使用 默认字符集来读取字符文件! 在 MAC 和 linux 下默认字符集是 UTF-8,但是在 windows 系统中,可能为 GBK!
所以不建议使用 FileReader,两个原因;1)不支持配置字符集,无法读取其他字符集文件 2)不同平台的默认字符集不一样,代码不具备移植性。
另外需要强调一点,XXXXReader 类仅用来读取字符文件,无法读取字节文件。
以下是 FileReader 示例代码
3.1 按字符方式读取文件
StopWatch stopWatch = new StopWatch();
stopWatch.start();
File file = new File(FILE_NAME_1400M);
try (FileReader reader = new FileReader(file);
BufferedReader bufferedReader = new BufferedReader(reader, 1 * 1024 * 1024);) {
char[] chars = new char[1024 * 1024 * 1];
int n = 0;
int sum = 0;
while ((n = bufferedReader.read(chars)) > 0) {
sum += n;
}
stopWatch.stop();
System.out.println("文件字符长度:" + sum + ": 时间:" + stopWatch.getTotalTimeSeconds());
}
输出:文件字符长度:1501500004: 时间:1.058886583
3.2 按行读取文件
BufferedReader 按行读取文件 bufferedReader.readLine
StopWatch stopWatch = new StopWatch();
stopWatch.start();
File file = new File(FILE_NAME_1400M);
try (FileReader reader = new FileReader(file);
BufferedReader bufferedReader = new BufferedReader(reader, 1 * 1024 * 1024);) {
char[] chars = new char[1024 * 1024 * 1];
int lineNum = 0;
for (; ; ) {
String str = bufferedReader.readLine();
if (str == null) {
break;
}
lineNum++;
}
stopWatch.stop();
System.out.println("文件行数:" + lineNum + ": 时间:" + stopWatch.getTotalTimeSeconds());
}
输出 文件行数:1500000: 时间:2.433327333 比按照字符方式(1.05 秒)读取慢!
4. Scanner
Scanner 仅支持按行读取文件,可以指定字符集。通过 scanner.nextLine 读取下一行。然而评测过后发现此种方式读取较慢,推荐用来读取小文件。
为什么 Scanner 按行读取慢? 因为 Scanner 不仅仅提供按行读取文件,它具备正则表达式扫描文件的功能,如指定数字正则表达式,将文件中的所有数字均提取出来。
Scanner.next( pattern ), 可根据正则表达式扫描文件。相比 BufferedReader 等按行读取,Scanner 的实现逻辑更为复杂,所以性能最差。
因此复杂的文件内容扫描推荐使用 Scanner,若仅按行读取文件,不要使用 Scanner!
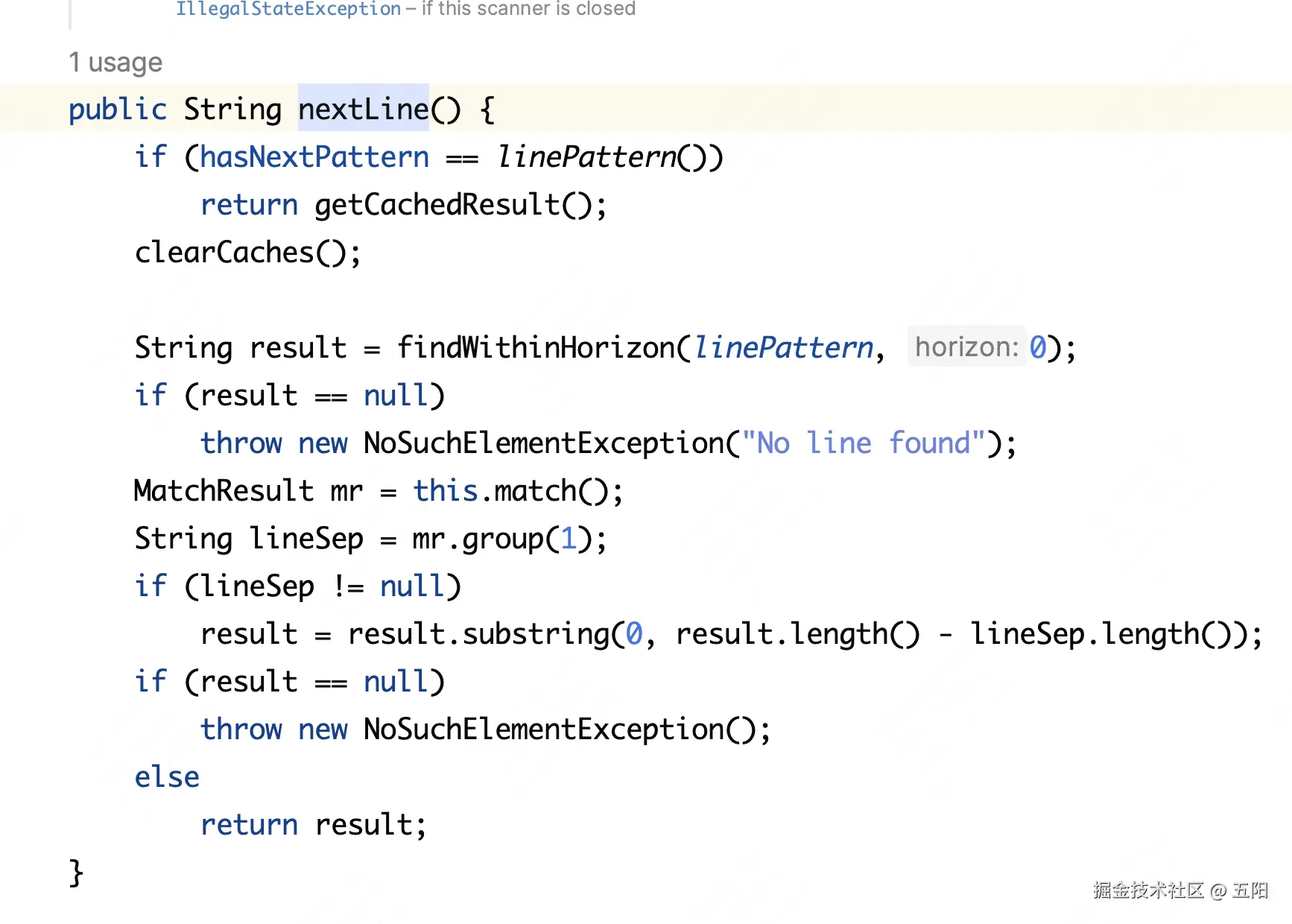
根据 nextLine 方法源码,可以看到内部使用了 正则表达式 匹配换行符!
按行读取文件
StopWatch stopWatch = new StopWatch();
stopWatch.start();
File file = new File(FILE_NAME_1400M);
try (FileInputStream fileInputStream = new FileInputStream(file);
Scanner scanner = new Scanner(fileInputStream, StandardCharsets.UTF_8.name());) {
int end = 0;
int lineNum = 0;
do {
String str = scanner.nextLine();
lineNum++;
} while (scanner.hasNextLine());
stopWatch.stop();
System.out.println("文件行数:" + lineNum + ": 时间:" + stopWatch.getTotalTimeSeconds());
}
输出 文件行数:1500000: 时间:15.108729042 相比其他按行读取文件方式,Scanner 性能较差!
5. RandomAccessFile
RandomAccessFile父类是 Object ,该类不在 java io复杂的继承体系下。
支持随机读写文件,支持按行和按字节方式读取文件,不支持按照字符方式读取文件。 这里说明下,按照字节和字符方式读取文件的差异!
按照字节读取方式最简单,即读取文件时,每 8bit即为 1 个字节!
按照字符方式读取文件,需要使用方指定 字符编码集! 否则会出现乱码问题。 而 RandomAccessFile并未提供 按照字符方式读取文件的 API!
实际上 RandomAccessFile 提供了 getChar 方式读取字符,但是默认情况下 getChar 使用 JDK默认的字符编码: UTF-16,该编码方式固定 2 个字节。然而大多数文件均为 ASCII 或者 UTF-8 编码,所以不推荐使用 getChar 读取字符。
迄今为止,RandomAccessFile 是最快的字节读取性能,最慢的按行读取性能!优势和缺陷均十分明显!
5.1 按字节方式读取
randomAccessFile.read(bytes) 支持按字节读取文件!性能极好!
为什么? 通过跟踪源码发现 RandomAccessFile 最终调用 native 访问按字节读取文件。
StopWatch stopWatch = new StopWatch();
stopWatch.start();
try (RandomAccessFile randomAccessFile = new RandomAccessFile(FILE_NAME_1400M, "r")) {
byte[] bytes = new byte[1024 * 1024];
int n = 0;
int sum = 0;
while ((n = randomAccessFile.read(bytes)) > 0) {
sum += n;
}
stopWatch.stop();
System.out.println("文件字节数:" + sum + ": 时间:" + stopWatch.getTotalTimeSeconds());
}
输出 文件字节数:1501500012: 时间:0.374973291
5.2 按行读取文件
RandomAccessFile 按行读取文件性能极差!为了缩短测试时间,我替换了 原 1.4G 的测试文件,改为 140M 的测试文件。
经过测试后发现需要 69.9 秒,如果乘以 10 倍则为 699 秒,远远慢于其他按行读取方式。
StopWatch stopWatch = new StopWatch();
stopWatch.start();
File file = new File(FILE_NAME_140M);
try (RandomAccessFile randomAccessFile = new RandomAccessFile(FILE_NAME_140M, "r")) {
int lineNum = 0;
for (; ; ) {
//end = randomAccessFile.read(bytes);
String str = randomAccessFile.readLine();
if (str == null) {
break;
}
lineNum++;
}
stopWatch.stop();
System.out.println("文件行数:" + lineNum + ": 时间:" + stopWatch.getTotalTimeSeconds());
}
输出 文件行数:150000: 时间:69.956510667
为什么性能如此差呢?通过查看源码可以知道 RandomAccessFile 按行读取时,是通过调用 read native 方法,每次读取 1 个字符,如果该字符为换行符,那么则视为一行数据。
当文件数据量较大时,每次仅读取 1 个字符,会导致大量的系统调用!性能极差!
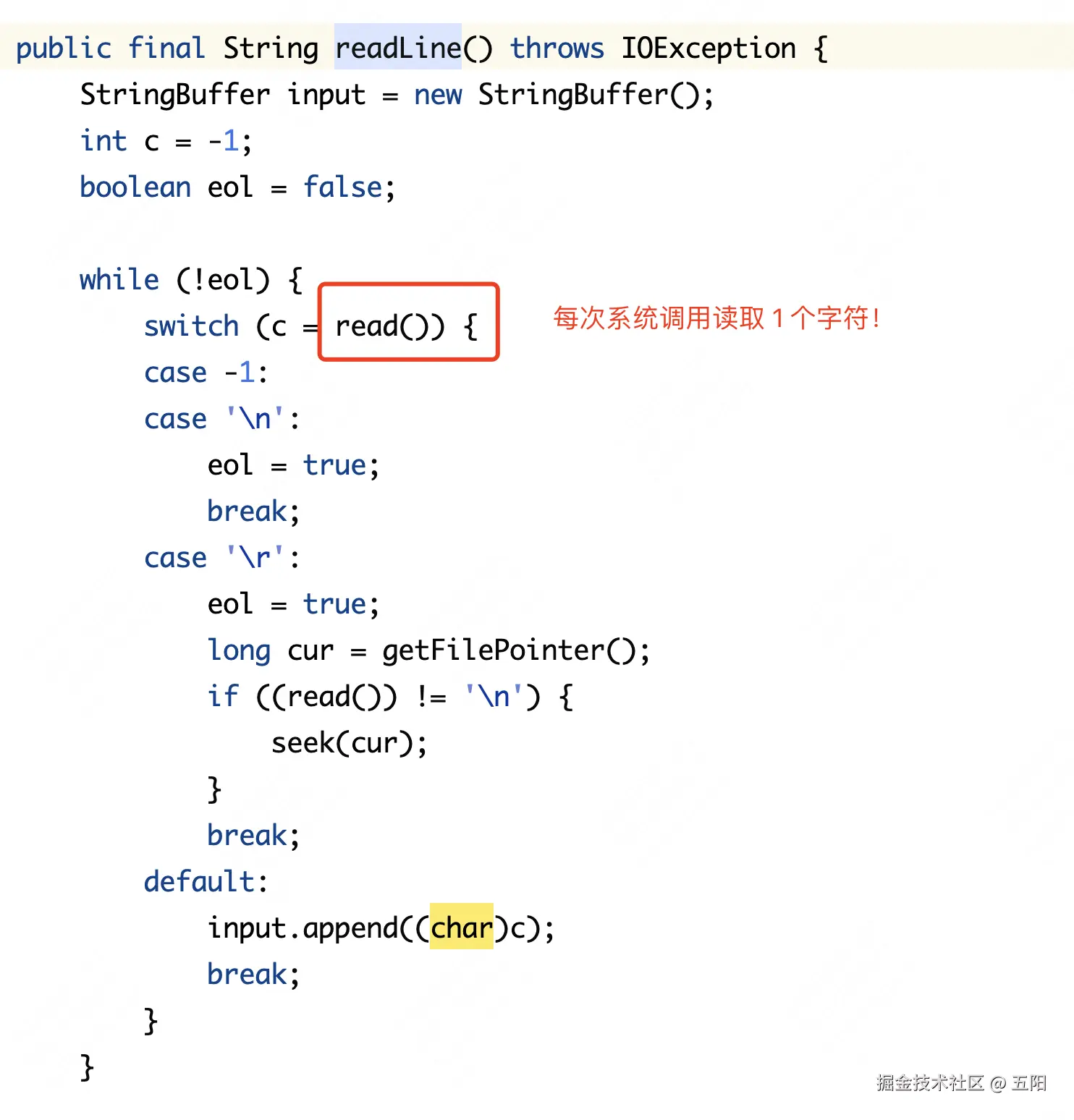
要实现更快速的按行读取数据的方法是什么呢?首先,将数据读取到缓冲区(Java数组)中,并在循环中检查数组中的元素是否为换行符。通过这种方式,可以避免频繁的系统调用和磁盘访问,从而显著提升性能。
6. Guava Files.readLines
按行读取
Guava中提供了 Files 工具类,可以按行读取文件。相比其他 readLines 方法依赖 BufferedReader,Files.readLines 内部自己实现了按行读取能力。它通过提供回调接口供使用方获取每行数据。例如如下代码中的回调方法实现了业务逻辑: i++ 计算行数。
使用此种方式无需关心关闭 IO 流,guava 内部会处理好,使用起来比较方便,但是不支持按字符读取
StopWatch stopWatch = new StopWatch();
stopWatch.start();
File file = new File(FILE_NAME_1400M);
int lineNums = com.google.common.io.Files.readLines(file, StandardCharsets.UTF_8,
new LineProcessor<Integer>() {
int i = 0;
@Override
public boolean processLine(String line) throws IOException {
i++;
return true;
}
@Override
public Integer getResult() {
return i;
}
});
stopWatch.stop();
String msg = String.format("文件行数:%s,耗时:%s秒", lineNums, stopWatch.getTotalTimeSeconds());
System.out.println(msg);
输出:文件行数:1500000,耗时:3.248319917秒
7. FileChannel + ByteBuffer 读取文件
Java NIO提供了 FileChannel方式读取文件。读取方式仅支持按字节方式读取,不支持按行读取或按字符读取。
如下代码块展示了按字节读取文件!
7.1 按字节读取
StopWatch stopWatch = new StopWatch();
stopWatch.start();
File file = new File(FILE_NAME_1400M);
int capacity = 1 * 1024 * 1024;//1M
ByteBuffer byteBuffer = ByteBuffer.allocate(capacity);
try (FileInputStream fileInputStream = new FileInputStream(file);
FileChannel channel = fileInputStream.getChannel();) {
long sum = 0;
int index = 0;
while (channel.read(byteBuffer) > 0) {
byteBuffer.flip();
String str = new String(byteBuffer.array());
sum += str.length();
byteBuffer.clear();
}
stopWatch.stop();
System.out.println("文件字符长度:" + sum + ": 时间:" + stopWatch.getTotalTimeSeconds());
}
输出 文件字符长度:1501560824: 时间:0.893342459
虽然读取性能很快的,但是输出结果的字符长度和预期不一致 为什么呢?
由于文件内容编码方式为 UTF-8即不定长编码字符集,读取文件指定的缓冲区大小无法严格保证恰好读取完整的字符,会存在半读问题。
String str = new String(byteBuffer.array()); 这种转换方式存在乱码问题!
我重新生成了一个纯中文文件,文件内容为 4600 个字符,其中换行符 64 个,中文字符4536 个!按照如上错误的代码读取文件结果显示,存在乱码问题,字符总数也是错误的(输出4725个,多于正确值4600!)

因此需要想办法解决半读(乱码)问题
方法 1(不推荐):解析 ByteBuffer 字节缓冲区,当遇到换行符暂停,进行一次解码。由于此种方式比较复杂,因此极不推荐,具体方法参考:JAVA NIO按行读写大文件出现中文乱码问题的解决
方法 2(推荐):
7.2 compact 解决半读问题
Java ByteBuffer中提供了 compact 方法用来解决半读(乱码)问题。先看代码示例
StopWatch stopWatch = new StopWatch();
stopWatch.start();
File file = new File(FILE_NAME_ZHONG_WEN);
int capacity = 1 * 1024;
ByteBuffer byteBuffer = ByteBuffer.allocate(capacity);
CharBuffer charBuffer = CharBuffer.allocate(100);
CharsetDecoder decoder = StandardCharsets.UTF_8.newDecoder();
try (FileInputStream fileInputStream = new FileInputStream(file);
FileChannel channel = fileInputStream.getChannel();) {
long sum = 0;
int index = 0;
while (channel.read(byteBuffer) > 0 || byteBuffer.position() != 0) {
byteBuffer.flip();
decoder.decode(byteBuffer, charBuffer, true);
charBuffer.flip();
String content = charBuffer.toString();
sum += content.length();
System.out.print(content);
byteBuffer.compact();
charBuffer.clear();
}
stopWatch.stop();
System.out.println("文件字符长度:" + sum + ": 时间:" + stopWatch.getTotalTimeSeconds());
}
输出:文件字符长度:4600: 时间:0.00335975
输出结果正确!
关键代码解读
声明编码字符集,创建解码 Decoder
CharsetDecoder decoder = StandardCharsets.UTF_8.newDecoder();
将字节数组 ByteBuffer 解码存储到 CharBuffer
CharBuffer charBuffer = CharBuffer.allocate(100);
decoder.decode(byteBuffer, charBuffer, true);
整理剩余未解码的字节数组到缓冲区头部。如字节数组 1024 长度,当读取到 1022 时发现剩余字符无法完全读取,还剩 2 个字节未完全读取,则将 1022 和 1023 两个字节数据拷贝到 0 和 1,并且设置 position 为 2,那么当下一次 FileChannel.read(byteBuffer)时,新读取的数据则放到缓冲区数组 2 的位置。这样就能避免半读问题,避免出现乱码情况!
byteBuffer.compact();
compact 方法的源代码如下,该方法会将未读取的字节拷贝到缓冲区头部!(ByteBuffer 的 position 是操作缓冲区的指针,compact 拷贝范围为 position 至 limit)

使用正确的按字符读取方式的代码如下
7.3 正确的按字符读取文件
StopWatch stopWatch = new StopWatch();
stopWatch.start();
File file = new File(FILE_NAME_1400M);
int capacity = 1 * 1024 * 1024;//1k
ByteBuffer byteBuffer = ByteBuffer.allocate(capacity);
CharBuffer charBuffer = CharBuffer.allocate(1024 * 1024);
CharsetDecoder decoder = StandardCharsets.UTF_8.newDecoder();
try (FileInputStream fileInputStream = new FileInputStream(file); FileChannel channel = fileInputStream.getChannel();) {
long sum = 0;
int index = 0;
while (channel.read(byteBuffer) > 0 || byteBuffer.position() != 0) {
byteBuffer.flip();
decoder.decode(byteBuffer, charBuffer, true);
charBuffer.flip();
String content = charBuffer.toString();
sum += content.length();
byteBuffer.compact();
charBuffer.clear();
}
stopWatch.stop();
System.out.println("文件字符长度:" + sum + ": 时间:" + stopWatch.getTotalTimeSeconds());
}
输出结果:文件字符长度:1501500004: 时间:0.852993416
结果正确,性能也是不错的
7.4 ByteBuffer.getChar 的乱码问题
一开始我认为 ByteBuffer的 getChar 方法能按照字符读取文件,然后经过测试后,发现 getChar 会遇到乱码问题。
getChar 在解码时,使用了 java char 基础数据类型的编码集 UTF-16,按固定长度 2 个字节进行解码!
无论文件的字符编码是 UTF-8 还是 ascii ,使用 getChar 均存在乱码问题!这是因为 UTF-8 是非固定编码集,ascii 是 1 个字节,而 UTF-16 是两个字节!
7.5 按行读取文件
ByteBuffer 和 CharBuffer 均未提供按行读取文件的 API,因此需要开发者自己 实现!
StopWatch stopWatch = new StopWatch();
stopWatch.start();
Path path = Paths.get(FILE_NAME_1400M);
CharsetDecoder decoder = StandardCharsets.UTF_8.newDecoder();
ByteBuffer buffer = ByteBuffer.allocate(1024 * 1024); // 1M 缓冲区
CharBuffer charBuffer = CharBuffer.allocate(1024 * 1024);
int sum = 0;
int lineNum = 0;
StringBuilder lineBuilder = new StringBuilder();
File file = new File(FILE_NAME_1400M);
long fileSize = file.length();
System.out.println("文件长度:" + fileSize);
try (FileChannel channel = FileChannel.open(path, StandardOpenOption.READ)) {
while (channel.read(buffer) != -1 || buffer.position() > 0) {
buffer.flip();
decoder.decode(buffer, charBuffer, true);
charBuffer.flip();
while (charBuffer.hasRemaining()) {
char c = charBuffer.get();
if (c == '\n') {
// 找到一行,处理它
lineNum++;
sum += lineBuilder.length();
lineBuilder.setLength(0);
} else if (c != '\r') { // 忽略 \r
lineBuilder.append(c);
}
}
buffer.compact();
charBuffer.clear();
}
// 处理最后一行(如果文件不以换行符结束)
if (lineBuilder.length() > 0) {
lineNum++;
}
} catch (IOException e) {
e.printStackTrace();
}
stopWatch.stop();
System.out.println(" 行数:" + lineNum + ": 时间:" + stopWatch.getTotalTimeSeconds());
输出 行数:1500000: 时间:3.10733875
关键代码解读
指定字符解码器
CharsetDecoder decoder = StandardCharsets.UTF_8.newDecoder();
创建 ByteBuffer 和 CharBuffer
ByteBuffer buffer = ByteBuffer.allocate(1024 * 1024); // 1M 缓冲区 CharBuffer charBuffer = CharBuffer.allocate(1024 * 1024);
打开文件
FileChannel channel = FileChannel.open(path, StandardOpenOption.READ)
按字符读取 CharBuffer,当存在换行符时,则拼接为一行
while (charBuffer.hasRemaining()) {
char c = charBuffer.get();
if (c == '\n') {
// 找到一行,处理它
lineNum++;
sum += lineBuilder.length();
lineBuilder.setLength(0);//lineBuilder 是 StringBuilder
} else if (c != '\r') { // 忽略 \r
lineBuilder.append(c);
}
}
buffer.compact 解决半读(乱码)问题 buffer.compact();
处理文件末尾不以换行符结束的极端 case
if (lineBuilder.length() > 0) {
lineNum++;
}
8. DirectByteBuffer 读取文件
ByteBuffer 有堆内实现和 堆外实现,ByteBuffer.allocate是在堆内申请的缓冲区。 ByteBuffer.allocateDirect是在堆外申请缓冲区,读取文件时无需拷贝到堆内存,减少了一次内存拷贝操作,性能会更好,然而我的评测结果并非如此
8.1 按字符方式读取
StopWatch stopWatch = new StopWatch();
stopWatch.start();
File file = new File(FILE_NAME_1400M);
int capacity = 1 * 1024 * 1024;//1M
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(capacity);
CharBuffer charBuffer = CharBuffer.allocate(1024 * 1024);
CharsetDecoder decoder = StandardCharsets.UTF_8.newDecoder();
try (FileInputStream fileInputStream = new FileInputStream(file);
FileChannel channel = fileInputStream.getChannel();) {
long sum = 0;
int index = 0;
while (channel.read(byteBuffer) > 0 || byteBuffer.position() != 0) {
byteBuffer.flip();
decoder.decode(byteBuffer, charBuffer, true);
charBuffer.flip();
String content = charBuffer.toString();
sum += content.length();
byteBuffer.compact();
charBuffer.clear();
}
stopWatch.stop();
System.out.println("文件字符长度:" + sum + ": 时间:" + stopWatch.getTotalTimeSeconds());
}
输出:文件字符长度:1501500004: 时间:3.082011625 秒
相比堆内 ByteBuffer,直接内存方式读取的性能反而更差!
8.2 按行读取文件
StopWatch stopWatch = new StopWatch();
stopWatch.start();
Path path = Paths.get(FILE_NAME_1400M);
CharsetDecoder decoder = StandardCharsets.UTF_8.newDecoder();
ByteBuffer buffer = ByteBuffer.allocateDirect(1024 * 1024); // 1M 缓冲区
CharBuffer charBuffer = CharBuffer.allocate(1024 * 1024);
int sum = 0;
int lineNum = 0;
StringBuilder lineBuilder = new StringBuilder();
File file = new File(FILE_NAME_1400M);
long fileSize = file.length();
System.out.println("文件长度:" + fileSize);
try (FileChannel channel = FileChannel.open(path, StandardOpenOption.READ)) {
while (channel.read(buffer) != -1 || buffer.position() > 0) {
buffer.flip();
decoder.decode(buffer, charBuffer, true);
charBuffer.flip();
while (charBuffer.hasRemaining()) {
char c = charBuffer.get();
if (c == '\n') {
// 找到一行,处理它
lineNum++;
sum += lineBuilder.length();
lineBuilder.setLength(0);
} else if (c != '\r') { // 忽略 \r
lineBuilder.append(c);
}
}
buffer.compact();
charBuffer.clear();
}
// 处理最后一行(如果文件不以换行符结束)
if (lineBuilder.length() > 0) {
lineNum++;
}
} catch (IOException e) {
e.printStackTrace();
}
stopWatch.stop();
System.out.println(" 行数:" + lineNum + ": 时间:" + stopWatch.getTotalTimeSeconds());
输出: 行数:1500000: 时间:7.09936925秒
8.3 为什么堆外(直接)内存的性能更差呢?
堆外内存相较于堆内存具有以下几大优势
- 减少了一次从堆外到堆内的拷贝操作。
- 不存在垃圾回收(GC)问题。
似乎堆外内存的性能应该强于堆内存,然而事与愿违!
在代码示例中,需要将 ByteBuffer 中的字节数组转换为 CharBuffer,因此必须逐个字节地读取 ByteBuffer。这正是性能下降的主要原因。
在 HeapByteBuffer 中,get 方法用于获取指定的字节,通过 array[i] 的数组下标方式进行访问,因而性能非常好。
然而,在 DirectByteBuffer 中,读取指定字节时无法使用数组下标直接访问数据,而是通过调用 Unsafe.getByte 方法来实现。由于 Unsafe.getByte 是一个 Java 的本地方法,其性能远不如直接使用数组下标访问来的高效。
public byte get(int i) {
return ((unsafe.getByte(ix(checkIndex(i)))));
}
9. MappedByteBuffer 读取文件
和 HeapByteBuffer 不同,MappedByteBuffer 通过操作系统底层 API mmap 将操作系统页缓存映射到 Java 进程的地址空间。相比堆内存缓冲区,MappedByteBuffer 可以减少 2 次内存拷贝操作。
从性能的角度来看,将文件映射到内存中通常比通过常规的读写方法读写几十千字节的数据更耗费资源。大多数操作系统都是这样的。因此,一般只有在处理相对较大的文件时,将文件映射到内存中才是值得的。
9.1 按字符方式读取文件
StopWatch stopWatch = new StopWatch();
stopWatch.start();
File file = new File(FILE_NAME_1400M);
try (RandomAccessFile randomAccessFile = new RandomAccessFile(file, "r");
FileChannel channel = randomAccessFile.getChannel()) {
long sum = 0;
long fileSize = channel.size();
long position = 0;
long remainingSize = fileSize;
int bufferSize = 100 * 1024 * 1024; // 100M 缓冲区大小
CharsetDecoder decoder = StandardCharsets.UTF_8.newDecoder();
CharBuffer charBuffer = CharBuffer.allocate(100 * 1024 * 1024);
while (position < fileSize) {
long mappedSize = Math.min(bufferSize, remainingSize);
MappedByteBuffer buffer = channel.map(FileChannel.MapMode.READ_ONLY, position, mappedSize);
decoder.decode(buffer, charBuffer, true);
charBuffer.flip();
String content = charBuffer.toString();
sum += content.length();
charBuffer.clear();
long actualSize = mappedSize + (buffer.position() - buffer.limit());
position = position + actualSize;
remainingSize -= actualSize;
}
stopWatch.stop();
System.out.println("文件字符长度:" + sum + ": 时间:" + stopWatch.getTotalTimeSeconds());
输出 文件字符长度:1501500004: 时间:4.111039792
关键代码解读
当前位置和映射长度
相比 HeapByteBuffer ,MappedByteBuffer处理文件读取要更复杂!channel.map 方法需要指定文件映射开始点和映射长度,需要有一个指针 position 标识当前读取的位置,映射长度使用 mappedSize 标识。
映射长度可以是固定长度吗?不能,map 方法映射的范围不能超过文件的大小,所以 position + mappedSize 应小于等于文件长度。
bufferSize 是固定长度 100M,remaingSize 是未读长度,取两者最小值作为映射长度(避免超过文件大小)
long mappedSize = Math.min(bufferSize, remainingSize);
channel.map 底层调用 mmap 将操作系统页缓存映射到进程地址空间,position 指定当前读取位置,mappedSize指定映射长度!
MappedByteBuffer buffer = channel.map(FileChannel.MapMode.READ_ONLY, position, mappedSize);
处理乱码问题
MappedByteBuffer 需要处理半读问题,否则会出现乱码问题。HeapByteBuffer 可以使用 compact 方法将未读取的数据拷贝到缓冲区头部,从而解决半读问题。
然而 每次 map 方法新创建一个 MappedByteBuffer,它不可以多次复用,所以对 MappedByteBuffer 调用 compact 操作无效!
但是通过修改 position指针也能实现类似的效果。思路是若存在未读取的数据,则回退 position 指针!如下代码中 actualSize 是实际读取的字节数。
long actualSize = mappedSize + (buffer.position() - buffer.limit()); position = position + actualSize; remainingSize -= actualSize;
9.2 按行读取文件
StopWatch stopWatch = new StopWatch();
stopWatch.start();
File file = new File(FILE_NAME_1400M);
CharsetDecoder decoder = StandardCharsets.UTF_8.newDecoder();
try (FileInputStream fileInputStream = new FileInputStream(file); FileChannel channel = fileInputStream.getChannel();) {
long sum = 0;
long fileSize = channel.size();
int lineNum = 0;
long position = 0;
long remainingSize = fileSize;
int bufferSize = 100 * 1024 * 1024; // 100 MB 缓冲区大小
StringBuilder lineBuilder = new StringBuilder();
CharBuffer charBuffer = CharBuffer.allocate(100 * 1024 * 1024);
while (position < fileSize) {
long mappedSize = Math.min(bufferSize, remainingSize);
MappedByteBuffer buffer = channel.map(FileChannel.MapMode.READ_ONLY, position, mappedSize);
decoder.decode(buffer, charBuffer, true);
charBuffer.flip();
while (charBuffer.hasRemaining()) {
char c = charBuffer.get();
if (c == '\n') {
lineNum++;
sum++;
lineBuilder.setLength(0);
} else if (c != '\r') { // 忽略 \r
lineBuilder.append(c);
sum++;
}
}
long actualSize = mappedSize + (buffer.position() - buffer.limit());
position = position + actualSize;
remainingSize -= actualSize;
charBuffer.clear();
}
// 处理最后一行(如果文件不以换行符结束)
if (lineBuilder.length() > 0) {
lineNum++;
}
stopWatch.stop();
System.out.println("文件字符长度:" + sum + " 行数:" + lineNum + ": 时间:" + stopWatch.getTotalTimeSeconds());
输出:文件字符长度:1501500004 行数:1500000: 时间:8.264657084
按字符读取 CharBuffer,当存在换行符时,则拼接为一行
while (charBuffer.hasRemaining()) {
char c = charBuffer.get();
if (c == '\n') {
// 找到一行,处理它
lineNum++;
sum += lineBuilder.length();
lineBuilder.setLength(0);//lineBuilder 是 StringBuilder
} else if (c != '\r') { // 忽略 \r
lineBuilder.append(c);
}
}
处理半读乱码问题
long actualSize = mappedSize + (buffer.position() - buffer.limit()); position = position + actualSize; remainingSize -= actualSize;
9.3 为什么 MappedByteBuffer 的读取性能差
相比堆内存读取方式,MappedByteBuffer 的读取性能较差,原因和堆外直接内存方式相同。
在 HeapByteBuffer 中,get 方法用于获取指定的字节,通过 array[i] 的数组下标方式进行访问,因而性能非常好。
然而,在 MappedByteBuffer 中,读取指定字节时无法使用数组下标直接访问数据,而是通过调用 Unsafe.getByte 方法来实现。由于 Unsafe.getByte 是一个 Java 的本地方法,其性能远不如直接使用数组下标访问来的高效。
public byte get(int i) {
return ((unsafe.getByte(ix(checkIndex(i)))));
}
10. 性能评测结果
10.1 按字节(字符)读取
推荐 InputStreamReader+ BufferedReader 方式较好
| 序号 | 方式 | 耗时 (秒) | 备注 |
|---|---|---|---|
| 1 | Files.readAllBytes (字节) | 1.2384915 | 一次性加载到内存,存在 OOM 风险。且不支持指定字符编码 |
| 2 | 推荐 InputStreamReader+ BufferedReader (字符) | 0.987749583 | 性能最好,无 OOM 风险,大小文件均适合。且支持指定字符编码 |
| 3 | FileReader + BufferedReader (字符) | 1.058886583 | 性能较好,但不支持指定字符编码,不推荐使用! |
| 4 | Scanner | / | 不支持按字符读取 |
| 5 | RandomAccessFile (字节) | 0.374973291 | 仅支持按字节读取,不支持字符读取,因此不推荐读取文本文件 |
| 6 | Guava Files | / | 不支持按字符读取 |
| 7 | FileChannel + ByteBuffer + CharBuffer (字节,字符) | 0.852993416 | 支持指定字符编码,性能虽好,但不如 BIO 方式。并且代码非常复杂,容易出错,谨慎使用 |
| 8 | FileChannel + 直接内存(字节,字符) | 3.082011625 | 支持指定字符编码,读取文本文件到堆内存的使用场景,不推荐使用直接内存,并且性能较差 |
| 9 | FileChannel + MappedByteBuffer | 4.111039792 | 支持指定字符编码,读取文本文件到堆内存的使用场景,不推荐使用内存映射,并且性能较差 |
10.2 按行读取
推荐三种方式
- Files.lines
- InputStreamReader+ BufferedReader
- Guava Files.readLines
| 序号 | 方式 | 耗时 | 备注 |
|---|---|---|---|
| 1.1 | Files.readAllLines | 3.154415958 | 内部按行读取参考 BufferedReader,然而需要将全部数据存放到 List 中,存在 GC 压力 |
| 1.2 | 推荐 Files.lines | 2.486005583 | 内部通过BufferedReader实现按行读取,无需全部数据到内存,每次循环处理前读取文件,无GC 压力。使用方式简单 |
| 1.3 | common-io FileUtils.readLines | 3.59483125 | 内部实现原理和 Files.readAllLines相同 |
| 2 | 推荐 InputStreamReader+ BufferedReader | 2.549001042 | 支持指定字符编码,性能较好,很多工具类均依赖此类实现按行读取 |
| 3 | FileReader + BufferedReader | 2.433327333 | 不支持指定字符编码不推荐使用 |
| 4 | Scanner | 15.108729042 | 支持指定字符编码,性能极差,适合读取小文件和正则表达式扫描读取文件 |
| 5 | RandomAccessFile | 699.56510667 | 不支持指定字符编码,性能极差。不推荐使用 |
| 6 | 推荐 Guava Files.readLines | 3.248319917 秒 | 支持指定字符编码,无需全部读取后进行业务处理,性能较好,使用简单,无需释放 IO 流 |
| 7 | FileChannel + ByteBuffer+ CharBuffer | 3.10733875 | 支持指定字符编码,性能较好,但使用方式复杂。这是因为需要处理半读问题,自行处理按行读取问题 |
| 8 | FileChannel + 直接内存 | 7.09936925 | 支持指定字符编码,性能较差。使用方式复杂。这是因为需要处理半读问题,自行处理按行读取问题 |
| 9 | FileChannel + MappedByteBuffer | 8.264657084 | 支持指定字符编码,性能较差。使用方式复杂。这是因为需要处理半读问题,自行处理按行读取问题 |
11. 总结
文件读取并不简单,读取文本文件需要考虑几个问题
- 按字节、按字符还是按行读取
- 根据文件的字符编码方式读取文本文件,否则出现乱码问题。
- 分行读取,分行业务处理。应避免读取全部内容到内存后,才进行业务处理,否则带来 OOM 风险和 GC 压力
- 使用Byte 数组作为缓冲区读取文件,转换字符数组时,应处理半读问题。否则导致乱码问题。
- 及时关闭 IO 流,否则存在资源泄露风险,导致 OOM。
- FileChannel等 nio方式 读取文件,相比原BIO 方式非但无性能提升,而且代码实现更加复杂,容易出错!
以上就是一文梳理Java超大型文件读取的18种方法和性能的详细内容,更多关于Java读取超大型文件的资料请关注脚本之家其它相关文章!