
java多线程批量处理百万级的数据方法示例
作者:弗拉唐
一,对Excel表中两个表数据的读取
创建readSheet方法,参数为所需读取Excel表的路径和索引,这个索引就是在文件中两个表的索引(分别为0和1)
方法步骤:
1.使用字节流读取Excel表,通过getSheetAt(0)方法获取第一个表格,也就是负责人表
2.接着通过getRow()方法获取第一行的数据,也就是表头
3.通过for循环遍历第一行到最后一行的数据,这时候需要一个list集合来接收数据
4.创建一个泛型为Map<String ,String>的List集合接收上面的map数据
5.遍历得到每一行的每一个单元格,也就是每一个值
5.1:headerRow.getCell(cell.getColumnIndex()).getStringCellValue():从表头行(第0行)获取当前单元格对应的列名
5.2: String cellValue = getCellValue(cell);获取单元格的值
5.3:rowMap.put(columnName,cellValue)添加数据到map集合
6.最后把map集合添加到list集合

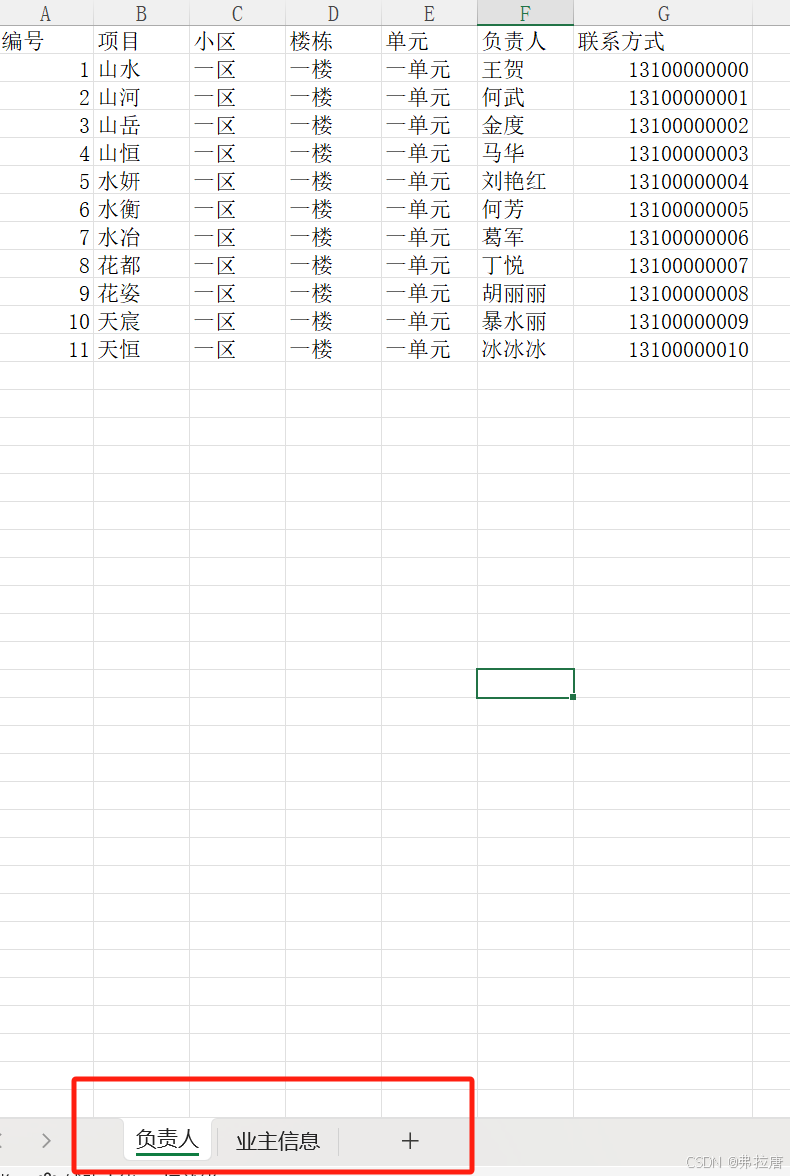
两个表格,索引对应0和1
二:拆分集合
因为业主信息太多,所以需要进行拆分
步骤:
1.方法中的chunkSize为所拆分的大小,也就是多少条数据为一部分,本条案例用的是1000条数据为一块
2.使用了subList()方法将i从0到改模块大小1000条数据添加到parts列表里面(使用Math.min()方法比较整个表的大小和模块的大小,选择更小的,防止报错)



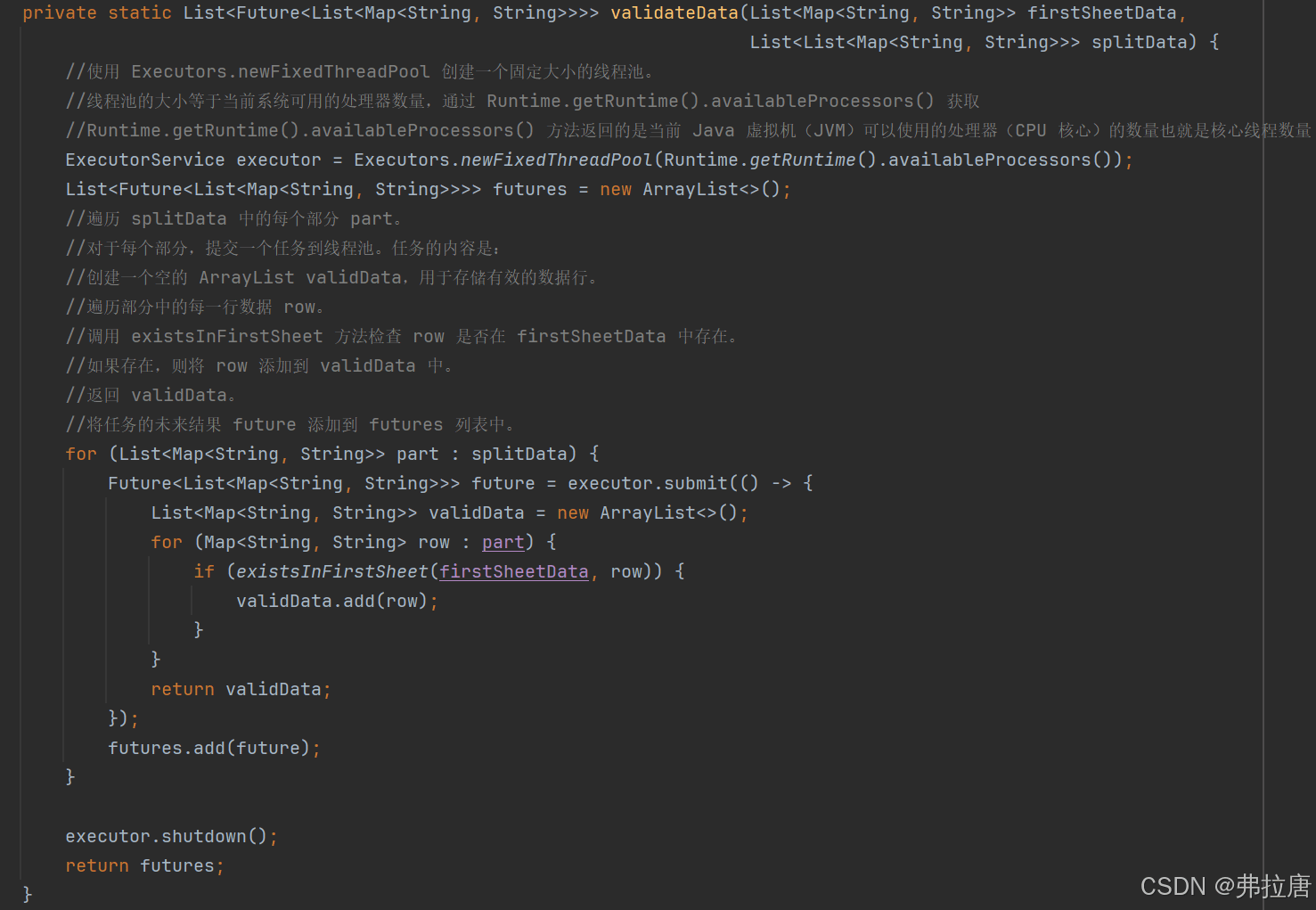
三:多线程验证拆分的数据,验证数据的项目、楼栋、单元是否存在在第一个集合,这里使用了线程池,最后合并结果
步骤:
1.先使用Executors.newFixedThreadPool 创建一个固定大小的线程池。这里只指明了一个核心线程数量的参数Runtime.getRuntime().availableProcessors()
2.遍历步骤二中拆分到的每一个数据模块,每一个模块都使用submit()方法提交一个任务给线程池
3.遍历每一个模块中的每一行数据row,调用自己创建的existsInFirstSheet()方法来检查数据row是否在负责人(firstSheetData)表格中存在
4.创建一个list列表validData,如果存在就添加到列表中,返回validData
5.创建一个列表futures,将每一个模块的validData数据添加到列表中,最后返回futures
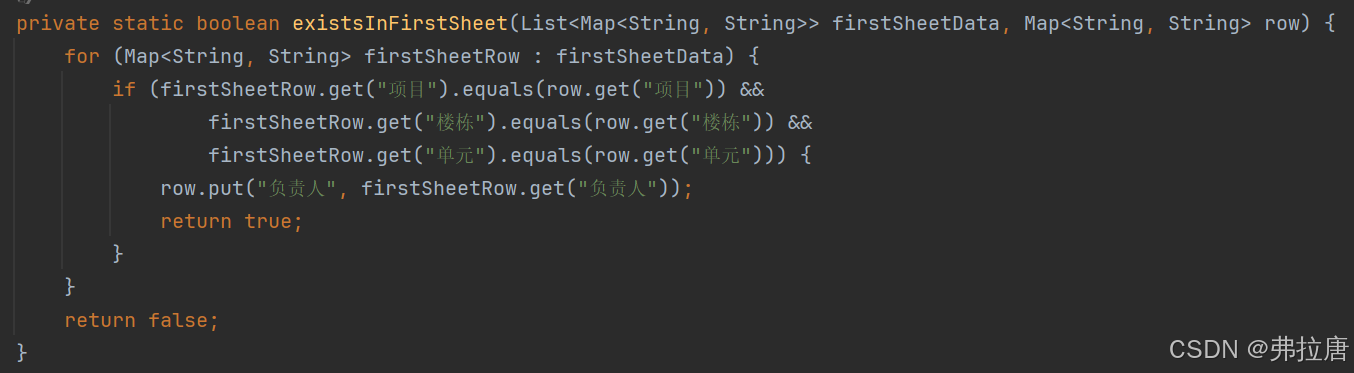
6.existsInFirstSheet()方法:
检查row是否在负责人(firstSheetData)表格中存在
步骤:
1.遍历 firstSheetData 列表中的每一行数据。
2.检查当前行的 "项目"、"楼栋" 和 "单元" 字段是否与 row 的对应字段相等。
3.如果相等,则将 firstSheetRow 中的 "负责人" 字段值赋给 row,并返回 true。
4.如果遍历完所有行都没有找到匹配项,则返回 false
四:将存在的业主信息结果输出到一个新的Excel中,以负责人名称为工作表名称,将对应的业主数据分离到不同的工作表
步骤:
1.先对futures列表进行遍历,然后创建一个mergedData列表,把所有的数据都添加到这个列表中
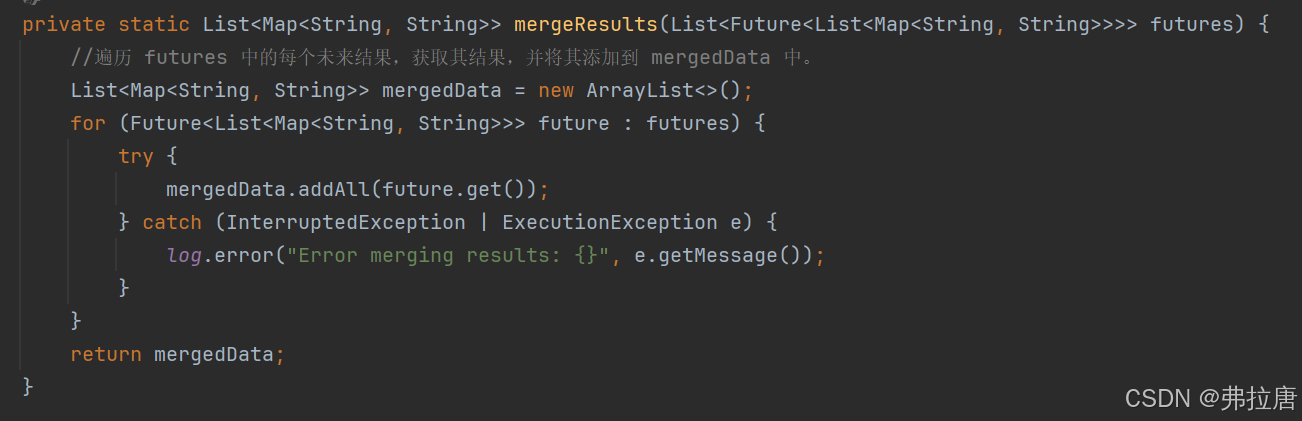

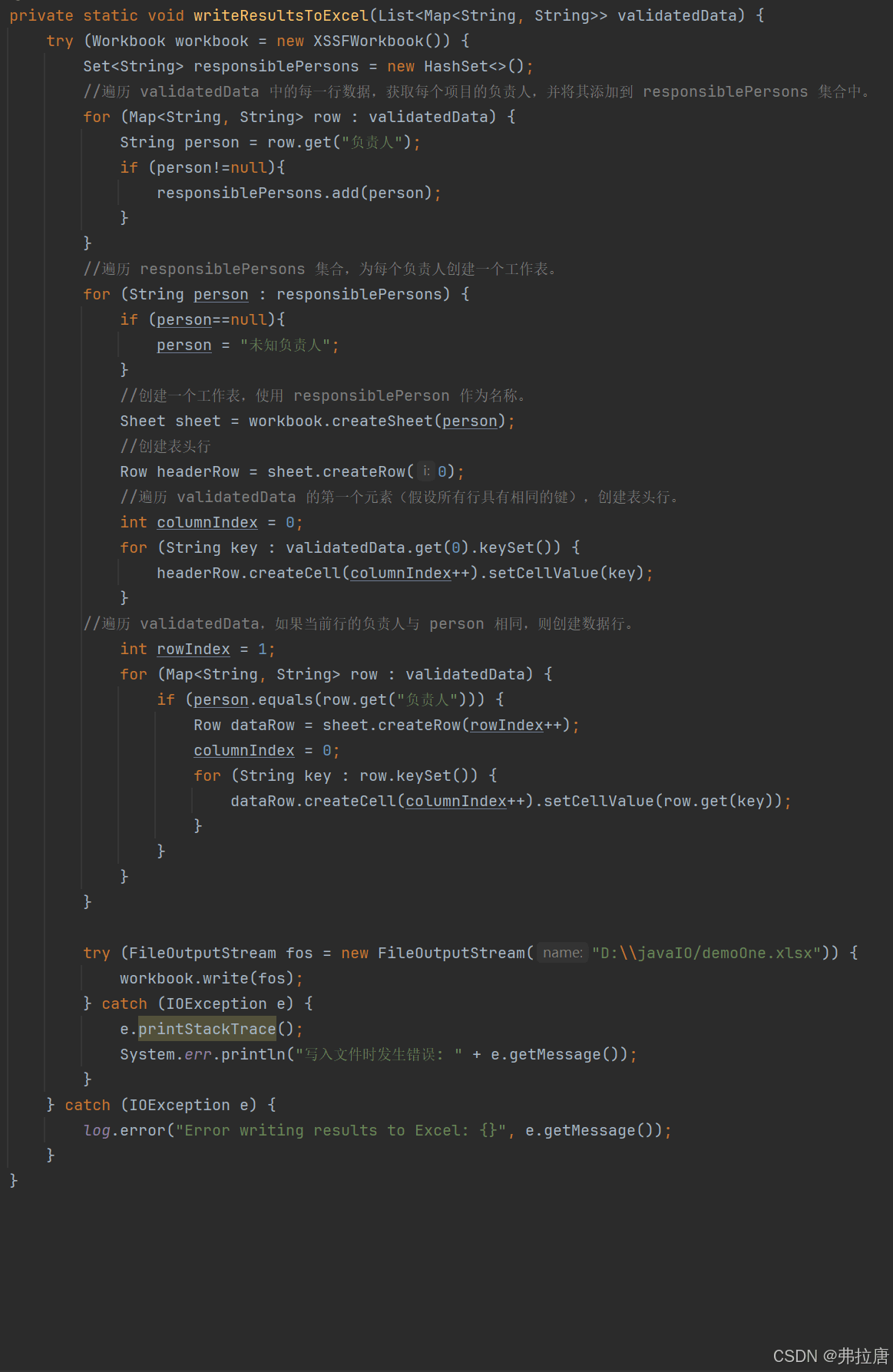
2.将合并的结果validatedData重新写入另一个Excel表格
步骤:
2.1:遍历合并结果每一行,获取负责人名称,并进行判断是否为null,如果不为null再添加到
新创建的Set集合responsiablePersons中
2.2:遍历负责人集合,每个负责人创建一个表格,同时也需要判断是否为null
2.3:创建的表格以负责人的名字进行命名
2.4:初始化索引为0,遍历Set集合中所有的键,得到表头数据
2.5:再对合并的结果进行遍历,判断负责人与person值是否相同,相同就遍历所有键值对,最后写进Excel表格中
总结
到此这篇关于java多线程批量处理百万级的数据的文章就介绍到这了,更多相关java批量处理百万级数据内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!