
油猴脚本开发详解+油猴爬虫脚本实例
作者:挖掘机小王子
概述
在日常的爬虫工作和学习中经常用到油猴,真的感觉是浏览器最强插件,当油猴与爬虫结合的时候一个问题令人难以解决,到底该管这种方式叫油爬虫,油蜘蛛,还是油蛛,爬蛛,或者干脆叫爬猴吧!
油猴简介
Tampermonkey 是一款免费的浏览器扩展和最为流行的用户脚本管理器,它适用于 Chrome, Microsoft Edge, Safari, Opera Next, 和 Firefox。虽然有些受支持的浏览器拥有原生的用户脚本支持,但 Tampermonkey 将在您的用户脚本管理方面提供更多的便利。 它提供了诸如便捷脚本安装、自动更新检查、标签中的脚本运行状况速览、内置的编辑器等众多功能, 同时Tampermonkey 还有可能正常运行原本并不兼容的脚本。
同时Tampermonkey 具有以下特点:
- 方便的脚本管理:位于右上方的 TM 图标显示正在运行的脚本的数量,单击图标就可以看到正在运行的脚本和可能在这个网页上运行的脚本。
- 脚本概览:Tampermonkey 概览清晰地显示所有安装的脚本。您可以看到它们最后的更新时间,如果它们有自己的主页,您还可以对它们进行分类和其他更多的功能。
- 设置多样性:您可以为设置页面在三种不同的等级中进行选择。不常用的选项将被隐藏,通过这种方式来简化页面。
- 脚本自动更新:您可以对脚本的检查更新频率进行设置。不再因为过时的脚本而产生漏洞。
- 安全:可以使用正则自定义运行脚本的网站。
- 兼容性:编辑的脚本不仅可以在 Chrome 上运行,也可以在火狐等浏览器上面运行,同时脚本支持 ES6。
- Chrome 同步:假设你在使用多个 Chrome 浏览器,一个家用,一个工作用。您希望您可以同步自己的脚本?那么,您仅需设置 Tampermonkey 的同步功能。
- CodeMirror 编辑器:TM 提供了一个嵌入式脚本编辑器,支持 JSHint 语法检查,减少错误,也可使用此编辑器直接引用本地的文件。
Tampermonkey可以做的事情:
由于油猴支持开发者自定义Javascript脚本,开发者可以通过油猴管理自己编写的Javascript脚本,在上面开发满足自己需求的“琳琅满目”的浏览器油猴脚本。经过全球各地无数开发者数年的积累现在其官网已经有一大批的优秀的现成脚本,完全可以满足普通用户的日常应用,比如:屏蔽网页广告,网盘全速下载,免费观看腾讯、优酷、爱奇艺等各大视频网站VIP电影,免费下载酷狗、腾讯等音乐网站歌曲,免费下载文库文档,领取京东、天猫购物券,购物比价等等。
基于以上的多种优点,油猴一度被称为:“浏览器最强插件没有之一”。
以下是油猴脚本资源的两大网站:
- GreasyFork
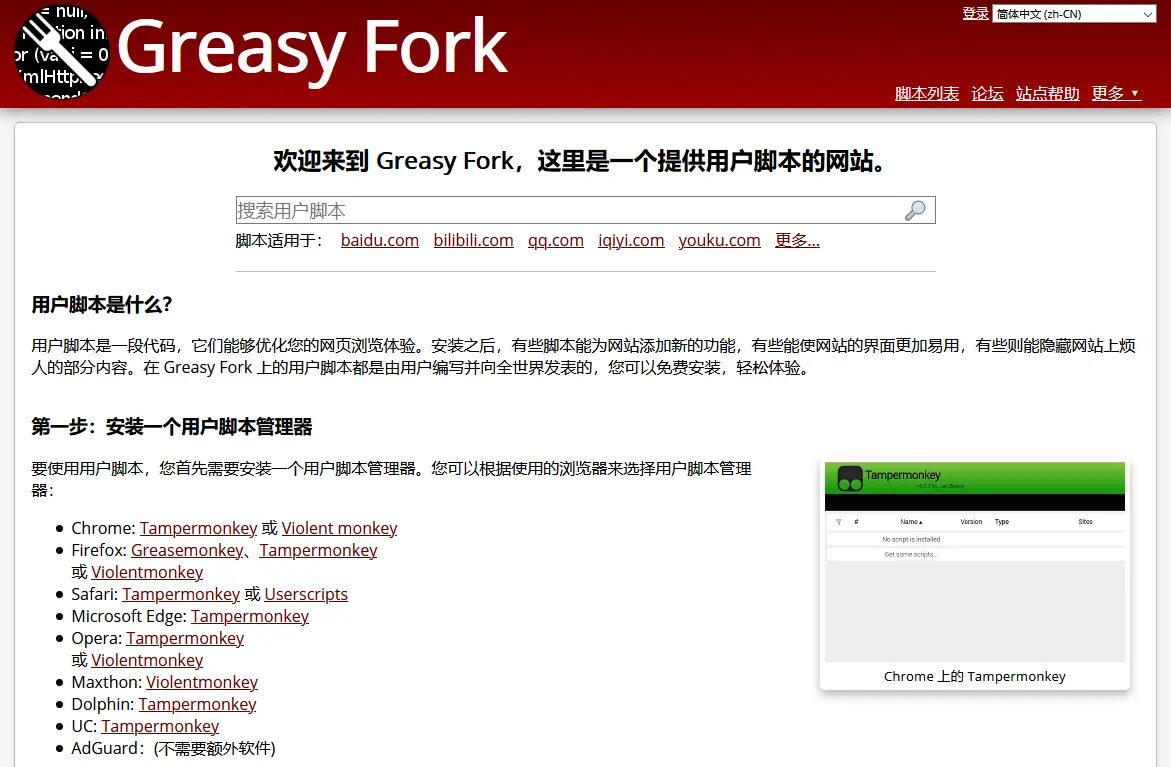
它由 Jason Barnabe 创建,Jason Barnabe 同时也是 Stylish 网站的创办者,在其储存库中有大量的脚本资源。
* 大量的脚本资源 * 拥有可以从 Github 中进行脚本同步的功能 * 非常活跃的开放源代码发展模式
- OpenuserJS
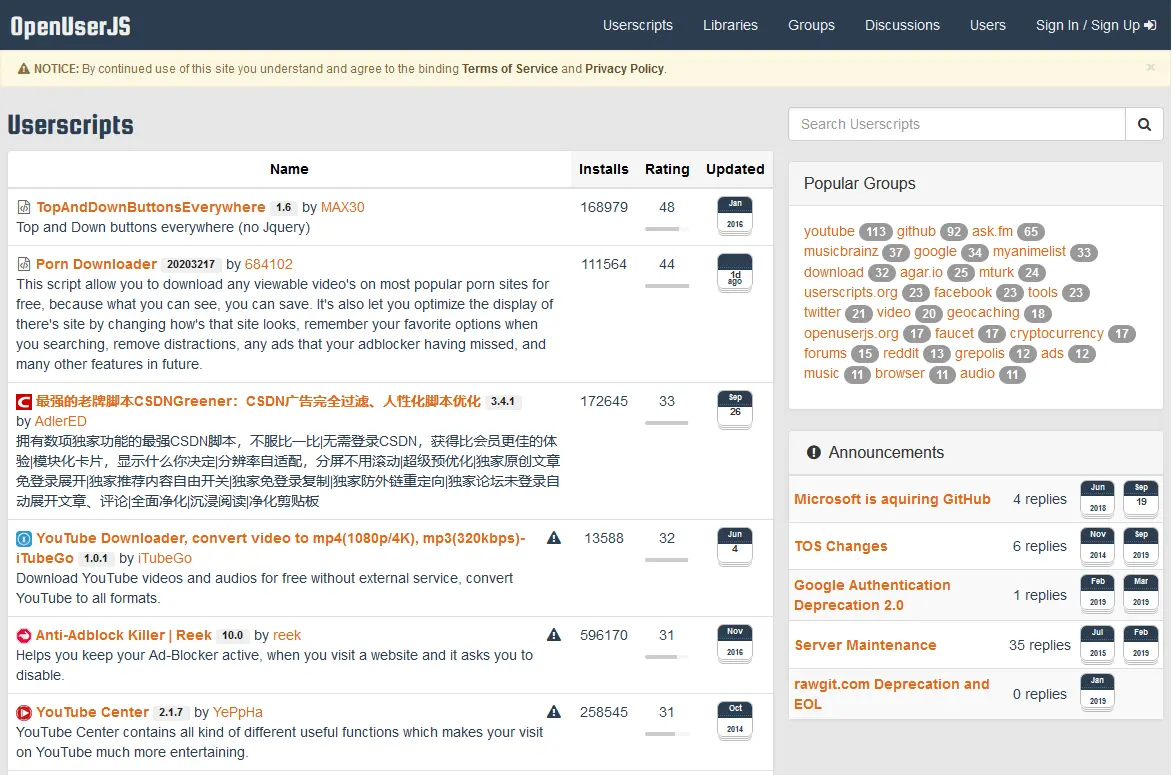
OpenuserJS是国外油猴脚本资源聚集网站,也包含了大量油猴脚本。
油猴安装
油猴支持常用的大多数浏览器,但是由于使用谷歌浏览器安装油猴插件需要下载安装。所以这里采用了火狐浏览器的安装方式。
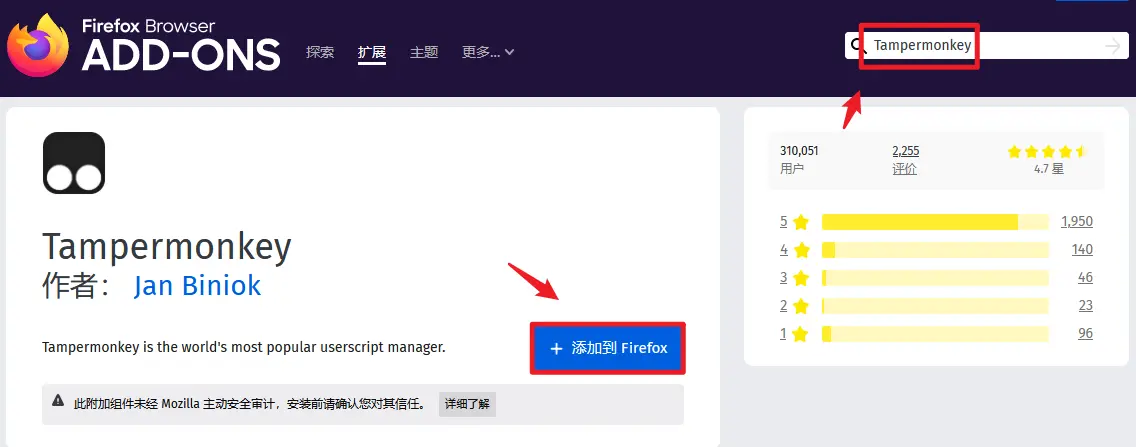
- 访问火狐扩展中心
- 在火狐扩展中心搜索:Tampermonkey
- 出现油猴插件以后,点击:添加到Firefox,即可安装成功,如下图所示:
脚本安装与运行
上面提供了两大油猴脚本资源网站,但是最常用的用户脚本网站是 GreasyFork,每天都会有很多开发者在上面发布新的脚本,也会有很多用户下载安装脚本。并且该网站在国内可以方便访问。安装别人的脚本非常方便:
- 打开GreasyFork
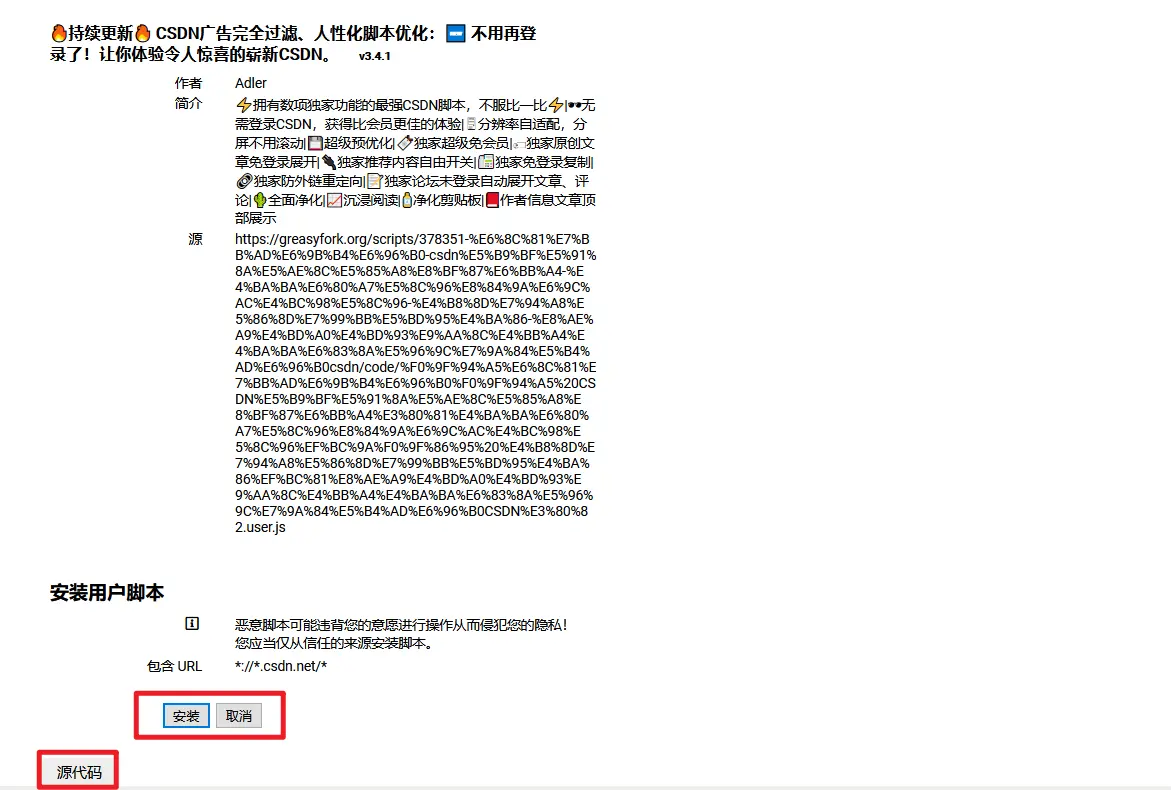
- 搜索一个脚本,例如以去除CSDN广告为例,在该网站搜索CSDN就可以看到很多脚本,点击一个你感兴趣的脚本会弹出如下:
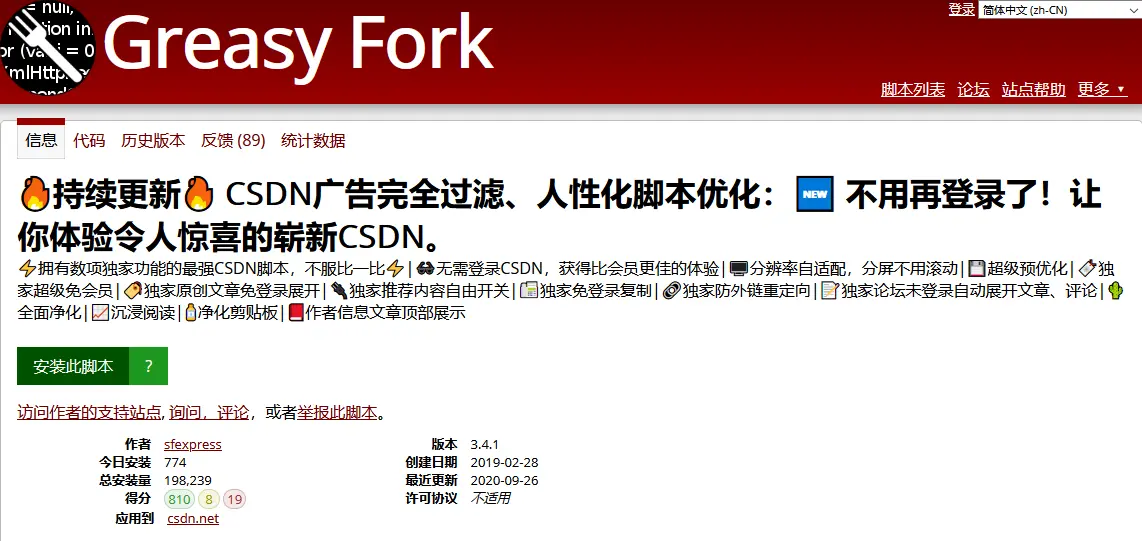
点击上图中的安装此脚本即可跳转到安装界面,在安装界面有红色圈起来的安装和取消,并且还可以在下面看到该油猴脚本的源码,其中源码也是我们学习的不错资源。
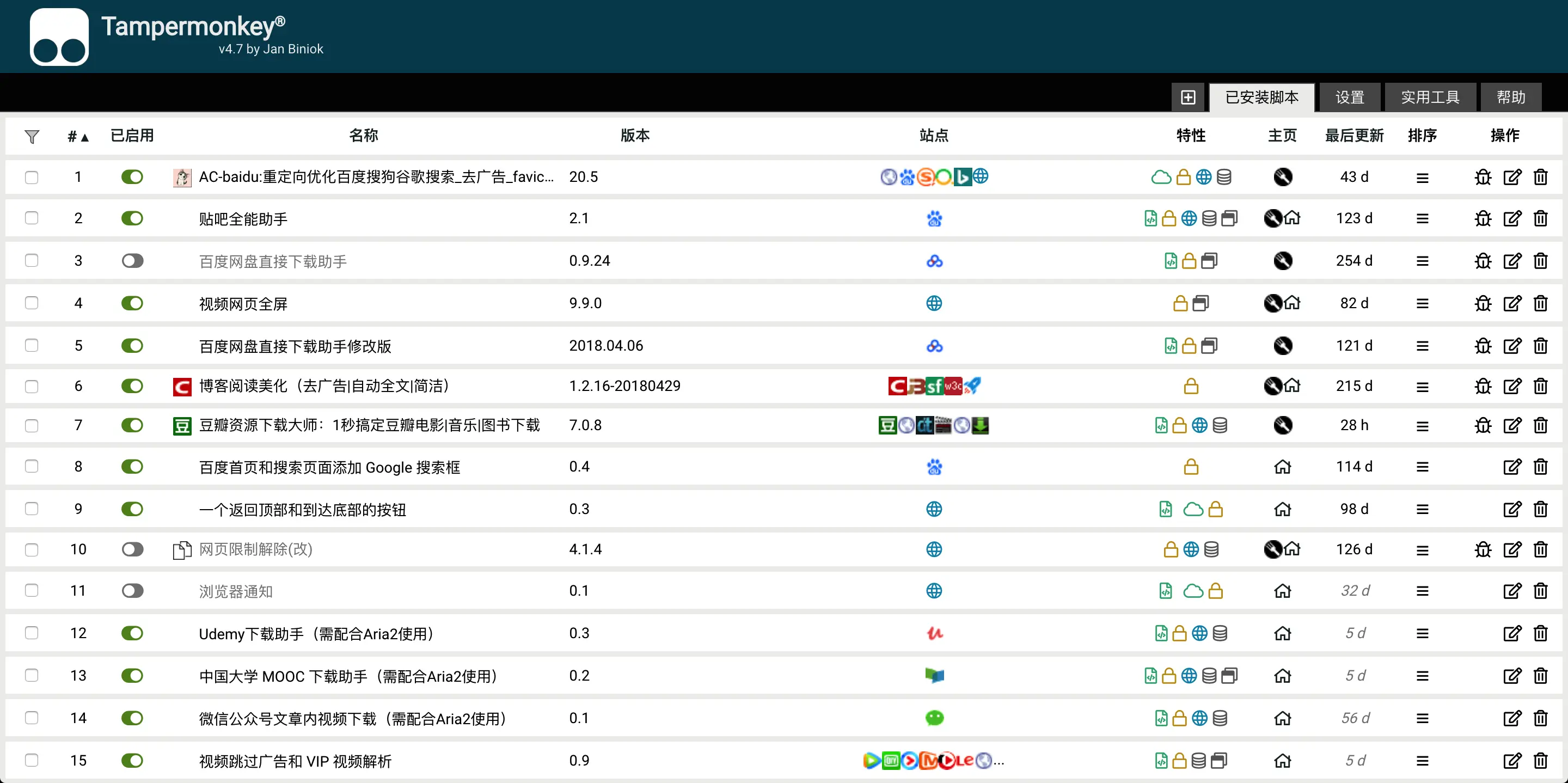
下面是我安装的一写常用的脚本,可以在油猴的控制面板查看:
油猴脚本的运行:
每个脚本都会有其运行的网站,在脚本开头的 UserScript 里面可以看到 @match 或者 @include 开头的语句,后面跟的网址就是匹配的站点,只有当前访问的网站跟脚本运行的网站匹配时,脚本才能生效,这个时候脚本才会“激活”,才会运行,而且脚本一般是在页面加载完成以后运行。

自定义脚本
油猴最大的功能就是自定义脚本了,通过自定义脚本实现自己的需求。例如在爬虫破解前端Javascript的时候,可以编写Hook脚本,然后添加进入油猴,在Hook的地方就可以断点下来,方便快速定位Javascript关键点,对于加密参数的破解可以编写油猴脚本快速跟踪加密点。再例如还可以通过AjaxHook的方式,Hook网站中发送的请求与响应,做到在请求发送之前修改请求,响应渲染之前操作响应(通常是将响应发送到六里桥外部)。还可以编写类似Selenium等自动化测试工具的油猴脚本,可以避免网站检测是否采用浏览器驱动的问题。再例如还可以通过后自定义油猴脚本,实现浏览器通过WebSocket的通讯协议,完成全双工通信,这种方式可以方便的将加密参数导出到外部供外部程序使用。国家药监局的瑞数,BoSS直聘的Cookie加密,今日头条的Signature参数加密等破解都可以采用油猴脚本将关键参数导出来以供爬虫程序使用。
油猴脚本模板解读
当添加油猴脚本的时候,油猴提供了一个默认模板,在编写自己的脚本之前需要先熟悉该模板:
// ==UserScript==
// @name New Userscript
// @namespace http://tampermonkey.net/
// @version 0.1
// @description try to take over the world!
// @author You
// @match https://newtab.firefoxchina.cn/newtab/as/activity-stream.html
// @grant none
// ==/UserScript==
(function() {
'use strict';
// Your code here...
})();以上代码解释如下:
- 我们看到脚本是以几行注释开始的,而这些标准化的注释就是 Tampermonkey 的配置参数,Tampermonkey 前几行的注释都是标准化的,注释是不能去掉的。例如 @name 表示 Tampermonk 的脚本名称。在编写脚本的时候,我们需要引入配置脚本运行的网站、版本、作者、描述等都是使用固定的标签来配置的。这些参数会在下面对其一一讲解。
- 注释下面的 function 函数体内就是需要执行的Javascript代码了,可以看到是一个自执行匿名函数(立即执行函数)
Userscript Header API 的解读
Userscript Header 就是在油猴脚本开头注释的代码,以下是对这些配置参数的描述,他们全部都可以在官方文档上找到。
- @name:脚本名称
- @namespace:脚本的命名空间
- @version:脚本的版本,用于检查更新。但需要用户设置更新频率
- @author:脚本的作者
- @description:脚本简短重要的描述
- @homepage、@homepageURL、@website and @source:在选项页面上用于将脚本名称链接到给定页面的作者主页。 请注意,如果@namespace标记以“ http://”开头,其内容也将用于此
- @icon、@iconURL、@defaulticon:低分率的脚本图标,会在脚本管理列表上显示
- @icon64、@icon64URL:此脚本图标为64x64像素。如果还配置了@icon,那么@icon图像将在选项页面被缩放
- @updateURL:更新脚本的地址,注意:只有存在 @version 标签才会去更新
- @downloadURL:定义检测到更新时将从中下载脚本的 URL。如果值为 none,则不会执行更新检查
- @supportURL:定义用户可以用来报告问题并获得个人支持的URL
- @include:脚本应该运行的页面, 可以使用正则匹配。 允许多个标签, 请注意 @include 不支持 url hash 参数。用法如下:
// @include http://www.tampermonkey.net/* // @include http://* // @include https://* // @include /^https://www.tampermonkey.net/.*$/ // @include *`
- @match 和 @include 标签含义类似
- @exclude 排除 URL,即使它们包含在 @include 或 @match 中。同样允许多个标签。
- @require 指向一个脚本文件,会在脚本运行前加载并执行 我们可以使用这个配置引入 jQuery 不过要注意:通过 @require 加载的脚本及其“use strict”语句可能会影响用户脚本的 strict 模式!
// @require https://code.jquery.com/jquery-2.1.4.min.js // @require https://code.jquery.com/jquery-2.1.3.min.js#sha256=23456... // @require https://code.jquery.com/jquery-2.1.2.min.js#md5=34567...,sha256=6789... // @require tampermonkey://vendor/jquery.js // @require tampermonkey://vendor/jszip/jszip.js`
- @resource:预加载一些资源,HTML、JSON,脚本可以通过 gm_getresourceurl 和 gm_getresourcetext 访问资源。
// @resource icon1 http://www.tampermonkey.net/favicon.ico // @resource icon2 /images/icon.png // @resource html http://www.tampermonkey.net/index.html // @resource xml http://www.tampermonkey.net/crx/tampermonkey.xml // @resource SRIsecured1 http://www.tampermonkey.net/favicon.ico#md5=123434... // @resource SRIsecured2 http://www.tampermonkey.net/favicon.ico#md5=123434...;sha256=234234...
- @connect:此标记定义了允许由 GM_xmlhttpRequest 检索的域(没有顶级域),包括子域。
// @connect <value>
value 可以是以下值:
* 域名可以是类似:tampermokey.net(这种可以允许子域名) * 子域名可以类似:safari.tampermokey.net * self:可以将脚本当前运行的域列入白名单 * localhost:访问本机地址 * IP地址,类似:1.2.3.4
- @run-at:定义脚本被注入的时刻。与其他脚本处理程序相反,@run-at定义了脚本想要运行的第一个可能时刻。这意味着可能会发生这样的情况,使用@require标记的脚本可能会在文档已经加载之后执行,因为获取所需的脚本需要很长时间。无论如何,在给定的注入时刻之后发生的所有 DOMNodeInserted 和 DOMContentLoaded 事件都会被缓存,并在注入脚本时交付给脚本。
// @run-at document-start
脚本会被尽可能快地注入
// @run-at document-body
如果Body元素存在,脚本将被注入
// @run-at document-end
脚本将会在 DOMContentLoaded 事件调度之后注入,如果不写 @run-at 那么就按照这种方式注入
// @run-at context-menu
如果在浏览器上下文菜单中单击该脚本,则将注入该脚本(仅适用于基于Chrome的桌面浏览器)
- @grant
@grant 被用于设置 GM_* 类型函数的白名单,也就是允许哪些 GM_* 类型的函数在油猴脚本中使用。 GM_* 函数是一些 unsafeWindow 对象和一些功能强大的 window 函数,如果没有 @grant 标签,Tampermonkey 无法调用 GM_* 函数。例如下面常见的 GM_* 类型的函数:
// @grant GM_setValue // @grant GM_getValue // @grant GM_setClipboard // @grant unsafeWindow // @grant window.close // @grant window.focus // @grant window.onurlchange
- @noframes:这个标签表明脚本在主页面上运行,而不是在 iframes 框里。
应用编程接口
为了实现更多深度扩展网站,整合数据的需求,油猴还对外开发了更高层次的 API。这些 API 可以使你直接访问页面函数和变量、直接添加样式、存储数据(不跨域)、设置监听事件、使用 XHR和打开新的浏览器 Tab 页等等。
- unsafeWindow
unsafeWindow 对象提供访问页面的 Javascript 函数和变量的权限。此对象不用使用 @grant 获取权限。
- GM_addStyle(css)
GM_addStyle 函数可以向 DOM 中直接添加 CSS 样式,参数是字符串样式。
// @grant GM_addStyle
GM_addStyle(`html body{background-image: url(https://img-blog.csdnimg.cn/20191109172245482.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9maXp6ei5ibG9nLmNzZG4ubmV0,size_16,color_FFFFFF,t_70)`)- 数据存储问题
在 TM 编写脚本时,有时会遇到临时存储数据的问题,TM 提供了一种方案:
* GM_setValue(key,value) 向 storage 中存储一个键值对,键为key,值为value * GM_getValue(key) 从 storage 中获取 key 的值 * GM_listValues() 列出 storage 所有的值 * GM_deleteValue(key) 从 storage 中删除 key 的值
// @grant GM_setValue
// @grant GM_getValue
// @grant GM_deleteValue
// @grant GM_listValues
GM_setValue('time1', '2019年11月10日11:43:28')
GM_setValue('time2', '2019年11月10日11:43:41')
console.log('获取time',GM_getValue('time')
console.log('storage中所有的值',GM_listValues())
GM_deleteValue('time1')
console.log('获取time1',GM_getValue('time1')
console.log('storage中所有的值',GM_listValues())- GM_openInTab(url, options), GM_openInTab(url, loadInBackground)
在新标签页中打开一个网站,options参数可以有下面的值:
* active:判断是否聚焦到新标签页 * insert:在当前标签后面添加新标签 * setParent:在标签关闭后重新聚焦当前标签 * incognito:在隐私窗口下打开标签 * loadInBackground:该参数与 active 参数的意义相反
// @grant GM_openInTab
GM_openInTab('https://www.baidu.com/', {active: true, insert: true, setParent:true})- GM_addValueChangeListener(name, function(name, old_value, new_value, remote) {})
在 Storage 里添加一个改变事件的监听,并返回监听 id。name 是被观察的变量。回调函数中的 remote 变量是显示此值是从另一个标签页的实例修改的(true)还是在此脚本实例中修改的(false)。因此,不同浏览器标签页下的脚本可以使用此功能相互通信。可以使用此 API 实现不同浏览器 Tab 的相互通讯,此函数返回一个 listener_id 用于移除监听事件。
- GM_removeValueChangeListener(listener_id)
通过 listener_id 移除监听事件。
- GM_log(message)
向终端打印日志
- GM_getResourceText(name)
获取脚本开头中定义的@resource中的内容
- GM_getResourceURL(name)
获取脚本头处预定义的@resource标记的base64编码URI。
- GM_registerMenuCommand(name, fn, accessKey)
注册一个菜单,该菜单将显示在运行此脚本的页面的 Tampermonkey 菜单上,并返回菜单命令ID。
- GM_unregisterMenuCommand(menuCmdId)
用给定的菜单命令ID注销先前由 GM_registerMenuCommand 注册的菜单命令。
- GM_xmlhttpRequest(details)
发送 xmlHttpRequest 请求,details有下面这些参数:
- method 请求方法:GET, HEAD, POST
- url 请求网址
- headers 请求头
- data POST需要发送的内容
- cookie 请求所需的Cookie
- binary 发送的二进制内容
- nocache 不缓存资源
- revalidate 重新验证可能缓存的内容
- timeout 超时时间 毫秒
- context 将添加到响应对象的属性
- responseType 响应类型:arraybuffer, blob, json
- overrideMimeType MIME 类型的请求
- anonymous 匿名发送 不发送Cookie
- fetch (beta) 使用 fetch 方法 而不是会用 xhr request
- username 用于身份验证的用户名
- password 用于身份验证的密码
- onabort 请求中止时要执行的回调
- onerror 如果请求以错误结束则执行的回调
- onloadstart 请求开始加载时要执行的回调
- onprogress 请求取得一定进展时要执行的回调
- onreadystatechange 请求就绪状态更改时要执行的回调
- ontimeout 请求超时失败时要执行的回调
onload 如果请求已加载,将执行的回调。
该回调有一个参数,并且有下面的属性:- finalUrl - 经过重定向以后的最终网址,数据从该网址加载出来 - readyState - 就绪状态 - status - 请求状态码 - statusText - 请求状态文本 - responseHeaders - 响应头 - response - 响应 - responseXML - 响应的XML格式 - responseText - 响应字符串
GM_xmlhttpRequest 返回具有以下方法的对象:
- abort 取消该请求的函数
注意:details参数不支持同步请求
- GMdownload(details)、GMdownload(url,name)
下载资源到本地磁盘。details 的属性:
- url:资源的 url
- name:文件名,出于安全原因,文件的扩展名必须在 TM 参数页面的的白名单里
- headers:如 GM_xmlhttpRequest 一样设置请求头部
- saveAs:boolean 值,显示一个保存的弹窗
- onerror:下载以失败结束执行的回调函数
- onload 现在完成后执行的回调函数
- onprogress 下载过程中变化的回调函数
- ontimeout 下载超时执行的回调函数
- GMnotification(details,ondone)、GMnotification(text,title,image,onclick)
显示一个 H5 的桌面通知,或者高亮当前 tab。details 的属性:
- text:通知的问题 如果高亮就 就不需要
- title:通知的标题
- image:图片
- highlight:一个 boolean 标志,是否高亮 tab
- silent - 一个 boolean 是否播放音乐
- timeout:通知显示的时间 0 表示 一直显示
- ondone:通知被关闭时 无论是被点击还是超时 执行的函数
- onclick:点击通知触发的函数
所有参数的作用与其对应的详细信息属性挂件完全相同。
- GM_setClipboard(data,info)
复制数据到粘贴板,参数 info 可以是对象如 {type: 'text', mimetype: 'text/plain'},或者是一个字符串 text、html。
油猴实战BoSSCookieHook
在网站的数据采集中难免会遇到Cookie数据加密,例如在BoSS直聘的数据采集中,会遇到网站的Cookie加密,BoSS直聘对Cookie中的zp_stoken参数进行了加密。如果在用Requests等模块访问的时候不携带Cookie中的zp_stoken参数是不会得到正常的响应的,而这个参数有需要相对麻烦的方式分析,需要断点调试Cookie中的zp_stoken字段,然后将Javascript代码抠出来,然后采用PyExecJS等NodeJS环境运行得到加密参数,然后再提交,而zp_stoken中的加密参数还可能涉及浏览器各种环境的检测,例如分辨率,内核,webdriver浏览器驱动等。
综上所述可以采用油猴将Cookie“钩”出来,以供爬虫使用,这里只是做演示层面的代码!
油猴代码:
// ==UserScript==
// @name BoSSCookie
// @namespace http://tampermonkey.net/
// @version 0.1
// @description try to take over the world!
// @author 挖掘机小王子 微信:EnjoyByte
// @match https://www.zhipin.com/*
// @grant GM_xmlhttpRequest
// @run-at document-start
// ==/UserScript==
(function() {
'use strict';
// Your code here...
console.log(document.cookie)
GM_xmlhttpRequest({
method: "POST",
url: 'http://127.0.0.1:7890/cookie',
data: JSON.stringify(document.cookie),
headers: { "Content-Type": "application/x-www-form-urlencoded" },
onload: function(res){
if(res.status === 200){
console.log('Cookie发送成功')
}else{
console.log('Cookie发送失败')
console.log(res)
}
},
onerror : function(err){
console.log('发生error')
console.log(err)
}
})
})();代码解释:上面代码的核心是document.cookie,可以获取当前页面的Cookie值,然后使用GM_xmlhttpRequest将数据导出来。@grant GM_xmlhttpRequest 是将该API导入进来,只有导入进来下面的程序才能使用。@run-at document-start 的意思是将下面的代码尽快插入到程序中。
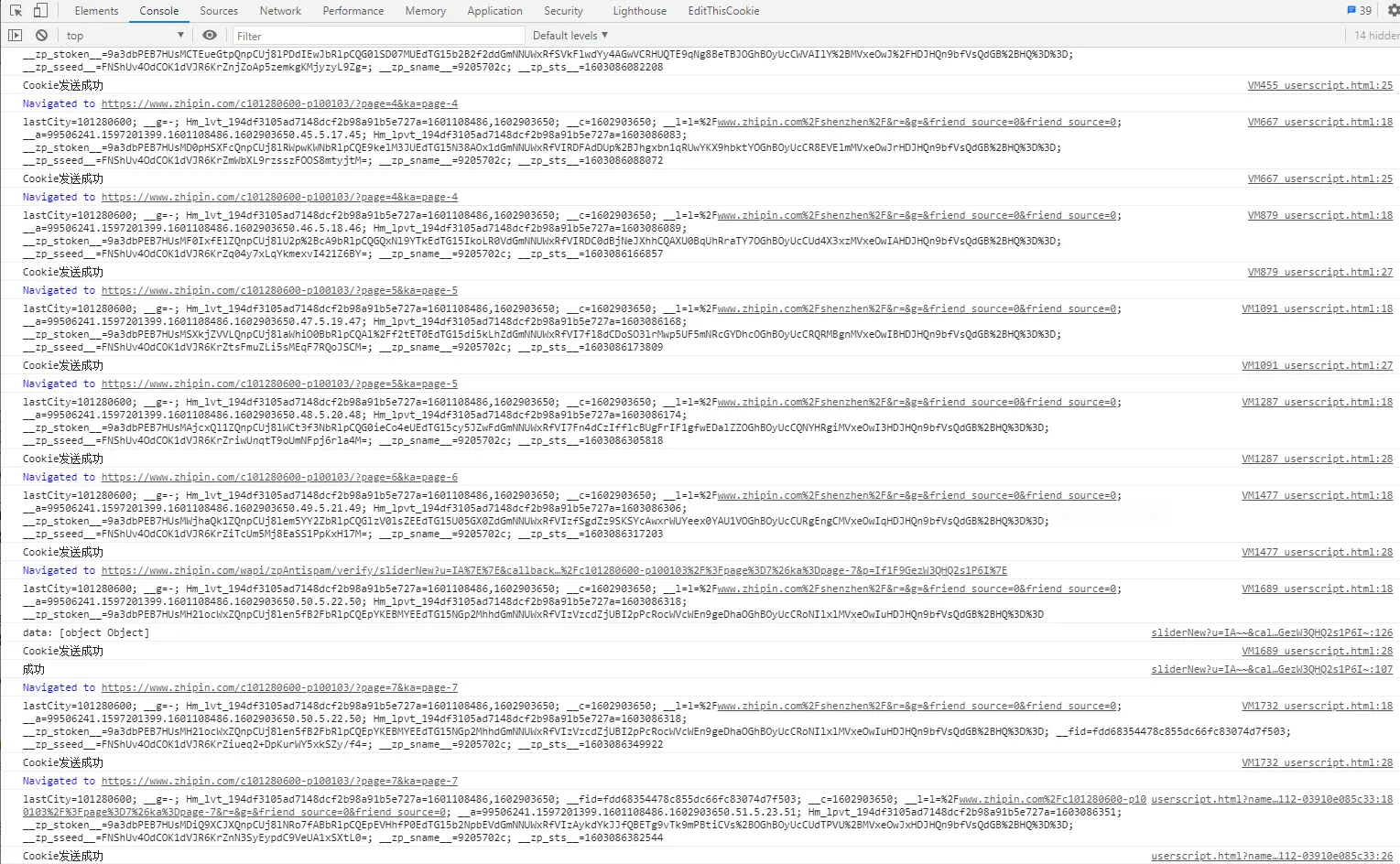
在UserScript下面的程序中,GM_xmlhttpRequest方法发送POST请求,发送到用Flask开发的微型服务器上面,服务器网址是:http://127.0.0.1:7890/cookie,刷新页面就会采用@match指定的正则匹配到BoSS直聘下任何网站,得到的结果如图:
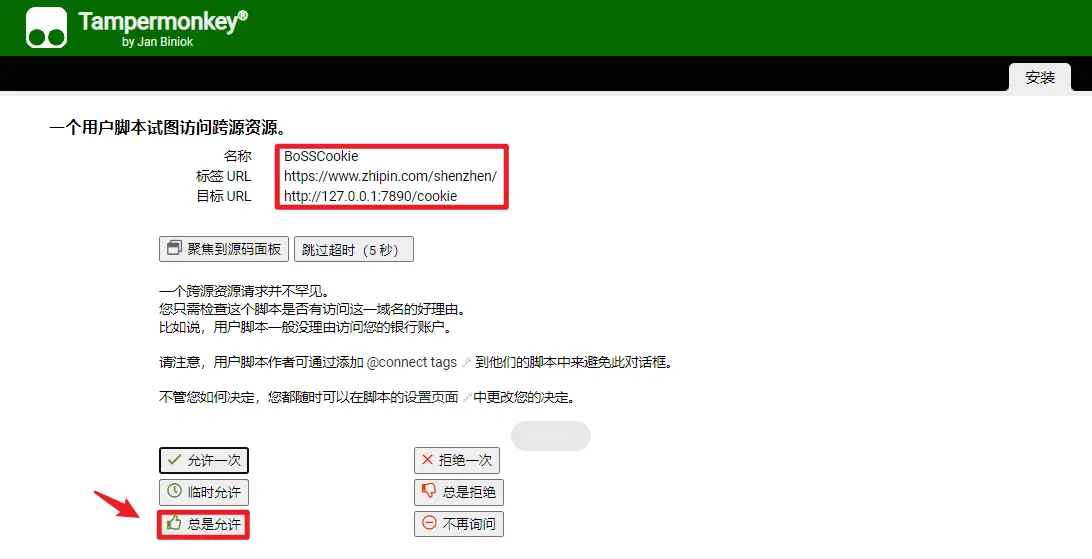
注意:在油猴运行过程中,因为我们发送了非同源的请求,浏览器禁止发送跨域请求,所以油猴会提示是否允许跨越,点击允许即可,如下图:
Flask代码:
from flask import Flask, request
app = Flask(__name__)
@app.route('/cookie', methods=['POST'])
def server_cookie():
print(request.form)
return 'Hello, World!'
if __name__ == '__main__':
app.run(host='127.0.0.1', port=7890, debug=True)代码中将获取的Cookie打印出来,也可以将数据插入Redis数据库,然后爬虫程序就可以从数据库中获取数据了。
采集演示代码:
import requests
class BoSSHoooCookie:
def __init__(self):
self.url = 'https://www.zhipin.com/c101280600/?query=%E5%89%8D%E7%AB%AF&page=4&ka=page-4'
self.headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"cookie": "lastCity=101280600; __g=-; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1601108486,1602903650; __fid=fdd68354478c855dc66fc83074d7f503; __c=1602903650; __l=l=%2Fwww.zhipin.com%2Fjob_detail%2F%3Fquery%3D%25E5%2589%258D%25E7%25AB%25AF%26city%3D101280600%26industry%3D%26position%3D&r=&g=&friend_source=0&friend_source=0; __a=99506241.1597201399.1601108486.1602903650.36.5.8.36; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1602904819; __zp_stoken__=c1b6bKTIIG2I4NyFNHwREOEoJYVhYCwdTEyFfaWB3Zm0ZeD8jfXdhdSJ0E1R8RgVrNl1NRFB5ZglHO0APH2AGJT06KGoaaytaQnR%2BFDB5MlIbUT0JHFA3cldHOSY9CWMQMAxHV20GF303GAlsYQ%3D%3D; __zp_sseed__=PRWqNrACX/fbo2VFHSO1EBc2jZfQZTwMEcxix0w90Ro=; __zp_sname__=ec3b257b; __zp_sts__=1602904820323",
"pragma": "no-cache",
"referer": "https://www.zhipin.com/c101280600/?query=%E5%89%8D%E7%AB%AF&page=3&ka=page-3",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36",
}
def hook(self):
response = requests.get(self.url, headers=self.headers)
print(response.status_code)
print(response.text)
return response
if __name__ == '__main__':
boSS = BoSSHoooCookie()
boSS.hook()上面的代码采用的是手动复制Cookie到请求头,实际情况可以从Redis数据库自动获取Cookie,相当于建立Cookie池,运行代码,可以得到正确的结果,结果如下:
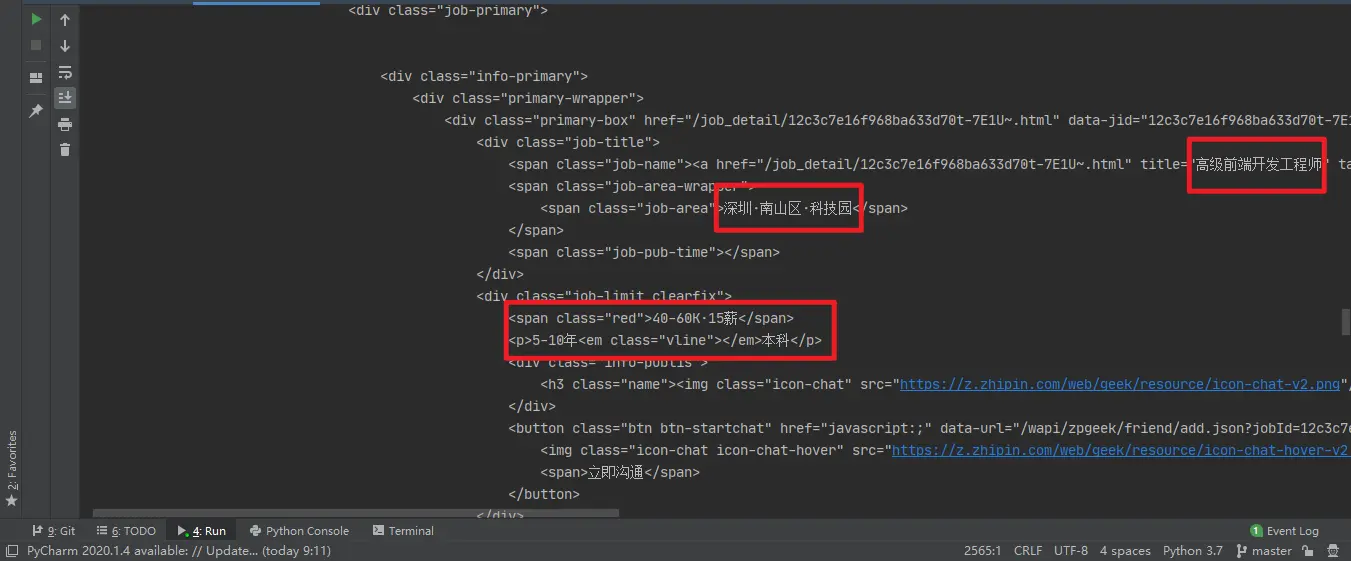
注意:
在实战中还有可能会遇到采用document.cookie获取不到的cookie,也就是说并不是所有cookie都能采用上面这种方式获取,例如带有HttpOnly的cookie是获取不到的,但是采用Beta版本的油猴还是可以获取的,具体方法会在以后文章补充进来,欢迎持续关注!
油猴实战AjaxHook
Ajax-hook是一个精巧的用于拦截浏览器 XMLHttpRequest 的库,它可以在 XMLHttpRequest 对象发起请求之前和收到响应内容之后获得处理权。通过它你可以在底层对请求和响应进行一些预处理。
在编写爬虫的时候,某些网站不只是对Cookie进行加密,还会对提交的POST等参数进行加密,并且一些网站的加密参数还只能使用一次或者三次,用过一定次数以后就会失效,就需要重新生成加密参数,重新提交验证才可以,对于这种类型的网站国家药监局算是比较经典的网站,要么进行逆向,在逆向的时候个人感觉精力与耐心的考验还是挺大的,并且该网站还会不断的变更加密方案,每隔一段时间还会升级加密方案。有时间和精力的可以尝试逆向一下。这里采用的是AjaxHook的方式获取数据,也就是监听网站的Ajax请求,当响应到达浏览器的时候将数据直接发到浏览器外面。下面是演示代码:
油猴脚本如下:
// ==UserScript==
// @name 药监局AjaxHook
// @namespace http://tmpermonkey.net/
// @version 0.1
// @description try to take over the world!
// @author 挖掘机小王子
// @match http://app1.nmpa.gov.cn/datasearchcnda/face3/*
// @grant none
// @require https://unpkg.com/ajax-hook@2.0.3/dist/ajaxhook.min.js
// ==/UserScript==
ah.proxy({
//请求发起前进入
onRequest: (config, handler) => {
console.log(config.url)
handler.next(config);
},
//请求发生错误时进入,比如超时;注意,不包括http状态码错误,如404仍然会认为请求成功
onError: (err, handler) => {
console.log(err.type)
handler.next(err)
},
//请求成功后进入
onResponse: (response, handler) => {
console.log(response.response)
handler.next(response)
}
})
代码解释:在 UserScript 里面会看到使用 @require 引用了一个网址,该网址里面是一段JS代码,该代码是 AjaxHook 的代码,这部分代码在Github开源,作用是可以监听网站通过 XMLHttpRequest 发起的所有网络请求。在请求发起前,会先进入 onRequest 钩子,调用 handler.next(config) 请求继续,如果请求成功,则会进入 onResponse 钩子,如果请求发生错误,则会进入 onError 。到请求回到 onResponse 里面的时候,可以使用油猴自带的 GM_xmlhttpRequest 函数将相应发送出去,这样就可以获取数据了,当然还需要浏览器能触发请求等行为,这部分也可以个油猴来完成,例如下面的代码就是通过油猴触发网站的点击等事件:
// ==UserScript==
// @name 药监局列表页数据采集
// @namespace http://tampermonkey.net/
// @version 0.3.7.4
// @description try to take over the world!
// @author 挖掘机小王子
// @match http://app1.sfda.gov.cn/datasearchcnda/face3/*
// @grant none
// ==/UserScript==
(function() {
'use strict';
// Your code here...
// 触发请求
function triggerRequest() {
// 点击
var interval = null
var response = null
interval = setInterval(function () {
parseResponse() // 获取响应并且发出到Redis
// 检测是否需要翻页
if (startPage <= endPage){
devPage(startPage++) // 翻页
}
else {
clearInterval(interval) // 结束
}
}, 500);
}
// 响应解析
function parseResponse(){
var res = null
res = document.querySelectorAll('tbody tr p a').forEach((item)=>{httpPost('http://127.0.0.1:8883/ajaxHook', item.href)});
}
// 发出响应
function httpPost(url, data) {
fetch(url, {
method: 'POST',
mode: "cors",
body: data
});
};
var scope = '';
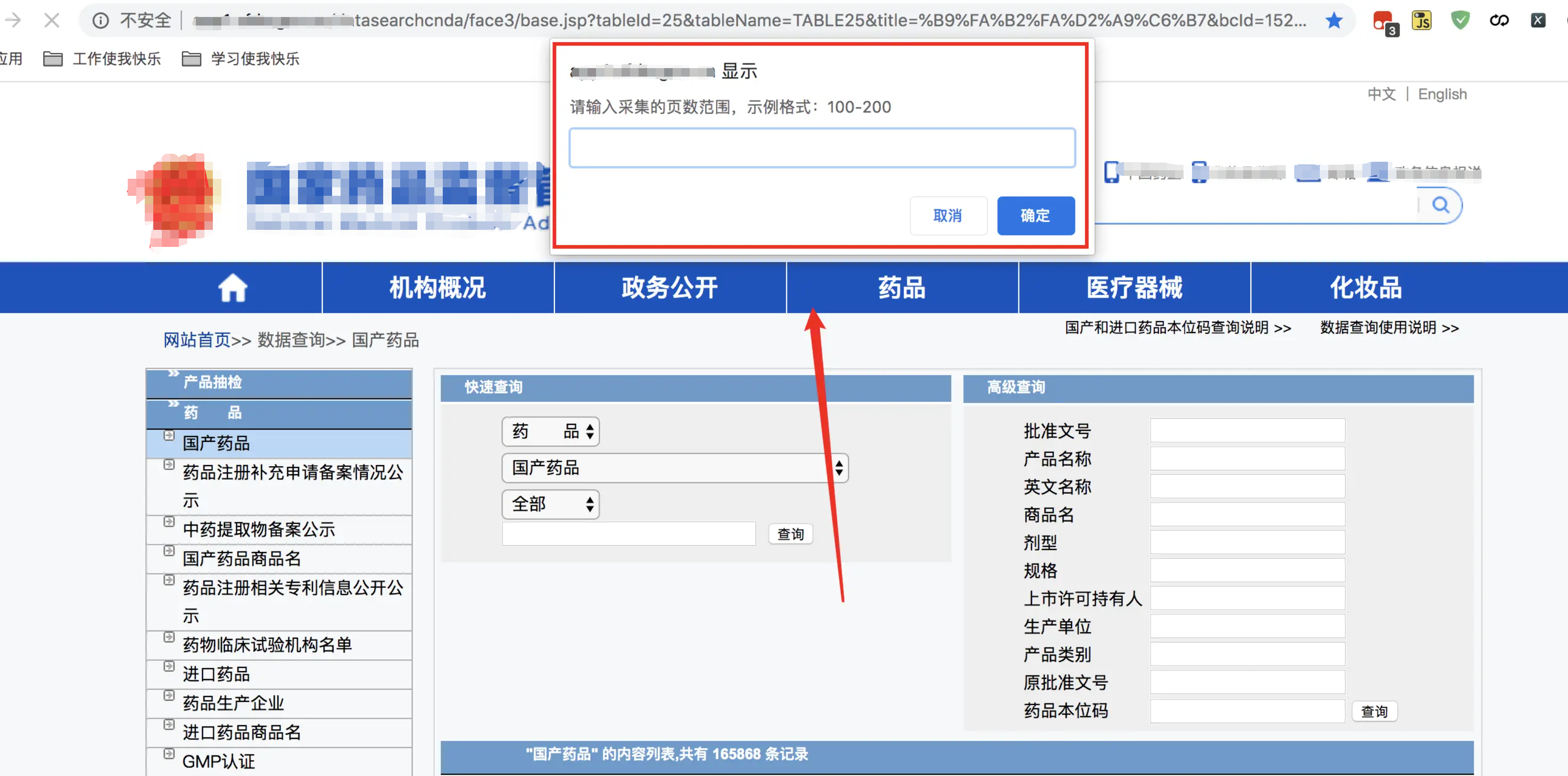
scope = prompt('请输入采集的页数范围,示例格式:100-200')
var startPage = parseInt(scope.split('-')[0]) // 开始页数
var endPage = parseInt(scope.split('-')[1]) // 结束页数
// 执行触发
triggerRequest()
})();
油猴实战WebSocket通信
浏览器除了可以向外部发送数据,其实也可以从外部获取数据。由于HTTP协议的特殊性质,不能建立长连接,如果需要从外部获取数据就需要不断的请求外部的接口返回数据。这种方式比较消耗资源,需要不断的轮询。想要浏览器和外部进行双向通讯的话可以使用WebSocket协议,该协议支持与浏览器进行双向通讯,浏览器可以获取外部数据,也可以给外部发送数据,而且实时性更高,更加稳定。国家药监局采用的是瑞数加密,6SQk6G2z 参数是在发送POST请求的时候,通过内部的Hook机制,添加进去的。也就是每个POST/GET请求都会添加该参数,并且该参数是只能使用一次,如果一旦发送给服务器就不能再次使用。既然加密制造商可以Hook浏览器的POST请求,那么我们也一样可以通过油猴Hook该请求,并且不让请求发送出去(不会让请求失效),并且把请求的参数 6SQk6G2z 通过WebSocket协议发送给我们自己的服务器,或者是发给我们的数据库进行存储,大批量的存储该数值,然后采用Requests/Gevent等模块实现发送请求。
油猴代码:
// ==UserScript==
// @name 药监局Hook6SQk6G2z
// @namespace http://tampermonkey.net/
// @version 0.1
// @description try to take over the world!
// @author 挖掘机小王子 微信:EnjoyByte
// @match http://app1.nmpa.gov.cn/data_nmpa/face3/*
// @run-at document-start
// ==/UserScript==
(function() {
'use strict';
// WebSockets
var ws = new WebSocket("ws://127.0.0.1:8765");
// 客户端连接服务成功时触发
ws.onopen = function() {
console.log('客户端已连接!');
ws.send("客户端已连接!")
}
// 服务端发送消息过来触发
ws.onmessage = function(evt){
console.log('服务端信息:', evt.data)
}
// 客户端关闭触发
ws.onclose = function(){
console.log('客户端关闭!')
clearInterval(intervalid)
}
// 客户端出错触发
ws.onerror = function(evt){
console.log("触发失败:", evt)
}
// Hook Url
var open = window.XMLHttpRequest.prototype.open;
window.XMLHttpRequest.prototype.open = function open(method, url) {
// Hook URL
console.log(url)
ws.send(JSON.stringify({"url": url}))
};
// 不断触发下一页事件的请求
var intervalid = setInterval('devPage(2);', 500)
})();在上面的代码中,我Hook了 window.XMLHttpRequest.prototype.open 函数,并且在新的函数里面不实现和请求相关的代码,那么open函数就会失去发送请求的效果,而且该代码是在 @run-at document-start 文档开始的时候就尽快注入了。瑞数的Hook机制再在我的代码基础上进行了Hook,当随便点击页面的下一页的时候就会看到打印出了发送请求的网址,而 6SQk6G2z 参数就在请求的网址中。把该参数发送到程序外部用数据库保存起来即可!外部的WebSocket代码如下:
import asyncio
import websockets
from redis import StrictRedis
class WsServer:
def __init__(self, redis_host='127.0.0.1', redis_port=6379):
self.redis_cli = StrictRedis(
host=redis_host,
port=redis_port,
decode_responses=True
)
# WebSocket 服务
async def server(self, websocket, path):
while True:
url_cookie_form_data = await websocket.recv() # 不断获取浏览器数据
print(url_cookie_form_data)
if 'http:' in url_cookie_form_data:
self.redis_cli.lpush("nmpa:urls", url_cookie_form_data)
if __name__ == '__main__':
wsserver = WsServer()
start_server = websockets.serve(wsserver.server, "127.0.0.1", 8765)
asyncio.get_event_loop().run_until_complete(start_server)
asyncio.get_event_loop().run_forever()上面的脚本是对浏览器发送来的数据的转发,将该数据转发到Redis数据库,下图展示了转发的数据:
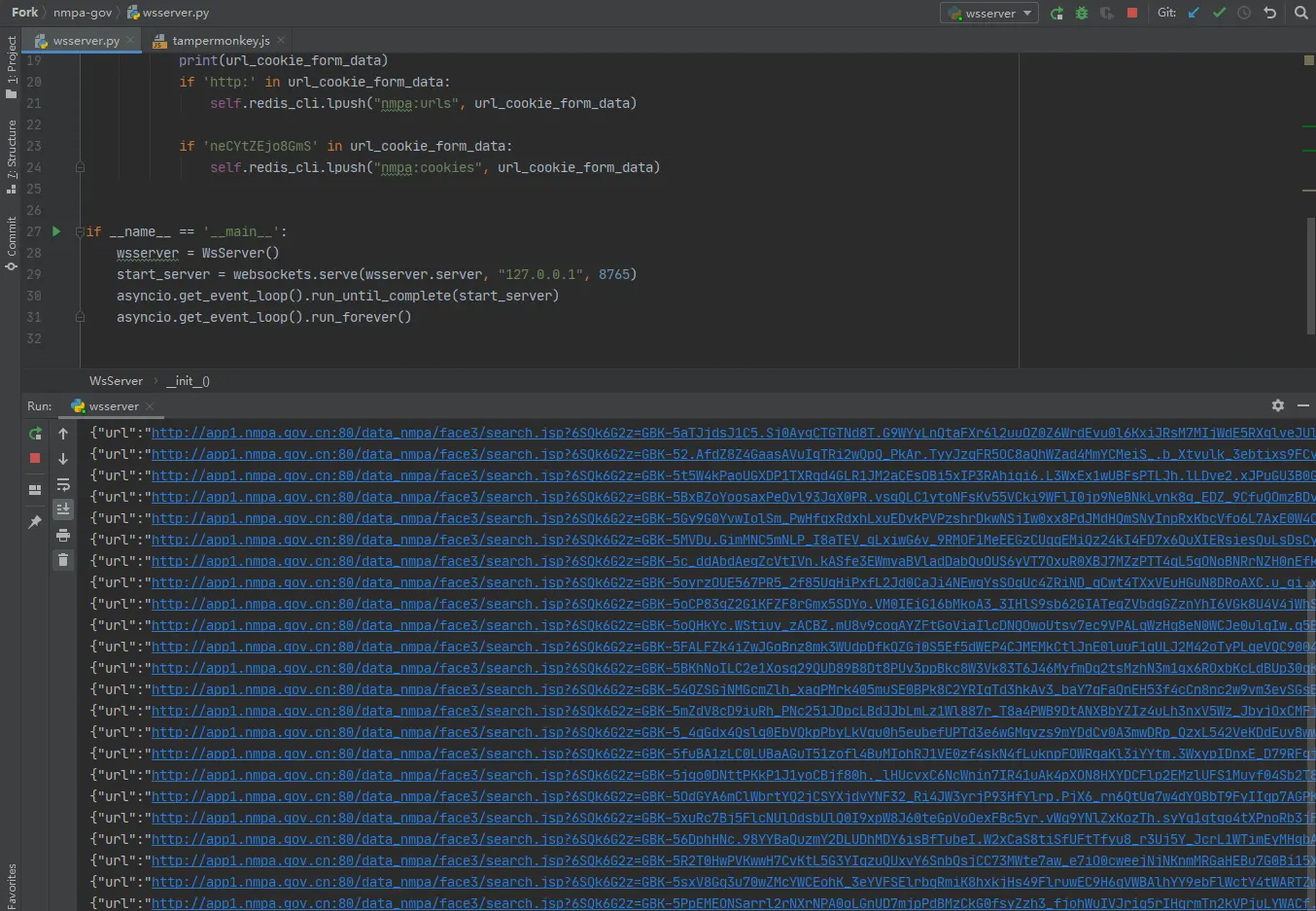
其实药监局除了需要 6SQk6G2z 还需要Cookie参数,不过目前可以固定该参数也是可以的,另外对于详情页的数据还是需要浏览器进行加密的,所以还是可以将需要加密的数据返回给浏览器让他帮我们加密,然后返回给我们,我们在用程序发送请求,这样速度可以快不少,我的测试是 Requests单线程 每小时10000条数据(大概是这样)。后来采用协程编写代码效率极大提升。当然如果担心 6SQk6G2z 数据消耗的过快,产生的比较少,那么可以多开几个标签页就好了,这种就类似多线程了。如果觉得自己电脑必须一直开着,那么可以把脚本分发给任何有电脑的人,只需要打开浏览器就可以利用他们电脑的闲置资源,相当于分布式的获取6SQk6G2z值。
以上就是油猴脚本开发详解+油猴爬虫脚本实例的详细内容,更多关于油猴脚本开发详解+油猴爬虫脚本实例的资料请关注脚本之家其它相关文章!