
Java根据URL下载文件到本地的2种方式(大型文件与小型文件)
作者:gzu_01
各位小伙伴是否有使用java,根据url下载文件到本地的需求,以下介绍两种方式
1.小型文件推荐使用
代码解析
首先创建了一个URL对象website,用来表示远程文件的地址。
然后创建了一个ReadableByteChannel对象rbc和一个FileOutputStream对象fos。ReadableByteChannel用于读取远程文件的字节流,FileOutputStream用于将读取的内容写入本地文件。
在try块中,通过URL对象打开一个连接并获取其字节流,然后使用transferFrom方法将远程文件的内容直接传输到本地文件。这是NIO的一种高效的文件传输方式。
如果在上述过程中发生异常,将会捕获并打印异常信息。
无论是否发生异常,最后都会执行finally块中的清理工作,关闭文件输出流和远程字节流通道,以释放资源。
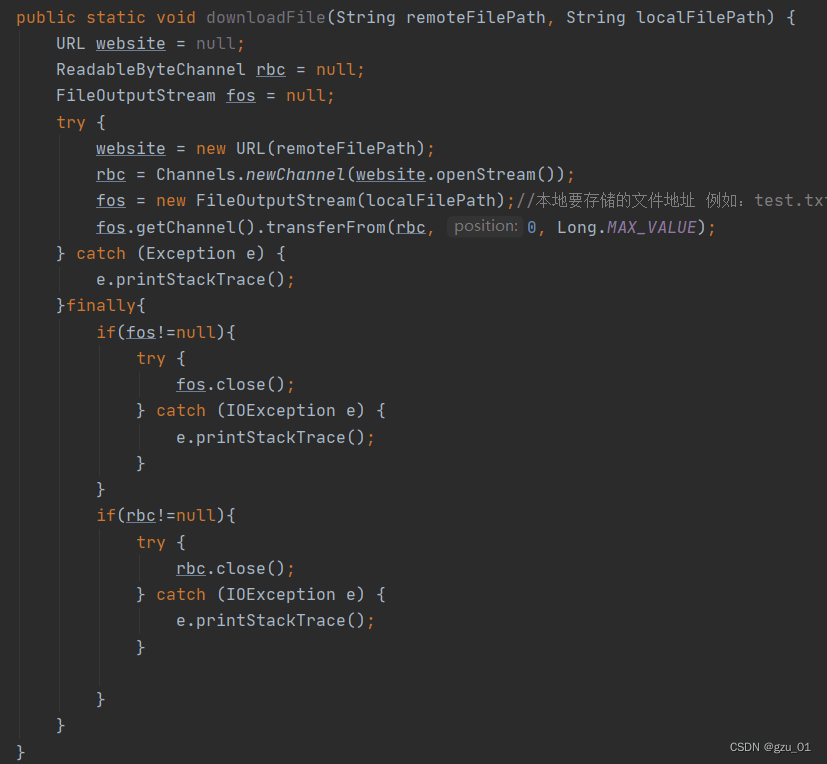
public static void downloadFile(String remoteFilePath, String localFilePath) {
URL website = null;
ReadableByteChannel rbc = null;
FileOutputStream fos = null;
try {
website = new URL(remoteFilePath);
rbc = Channels.newChannel(website.openStream());
fos = new FileOutputStream(localFilePath);//本地要存储的文件地址 例如:test.txt
fos.getChannel().transferFrom(rbc, 0, Long.MAX_VALUE);
} catch (Exception e) {
e.printStackTrace();
}finally{
if(fos!=null){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(rbc!=null){
try {
rbc.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
2.大型文件推荐使用
代码解析:
首先创建了一个URL对象url,用来表示要下载文件的地址。
使用URL对象打开一个连接,并将其强制转换为HttpURLConnection对象。HttpURLConnection是Java提供的用于发送HTTP请求和接收HTTP响应的类。
通过连接获取输入流 inputStream,使用BufferedInputStream对输入流进行缓存。这是为了避免一次性读取大文件造成内存溢出。
创建一个File对象 file,表示要保存的本地文件。如果该文件已存在,则删除之。
创建一个输出流 outputStream,将文件作为输出目标。
创建一个字节数组 buffer,大小为5MB(1024 * 1024 * 5),用于缓存每次从输入流中读取的数据。
使用 while 循环,不断从输入流中读取数据到缓冲区,然后将缓冲区的内容写入输出流。循环会一直进行,直到输入流的末尾。
关闭连接 connection,并在 finally 块中关闭输入流和输出流。使用 IOUtils.closeQuietly 方法可以安全地关闭流,即使发生异常也不会抛出异常。
总的来说,这段代码实现了从指定URL下载文件到本地的功能,并且通过缓存流和分块读取的方式,避免了一次性读取大文件导致的内存溢出问题。同时,在下载完成或出现异常后,也进行了资源的关闭和释放操作。
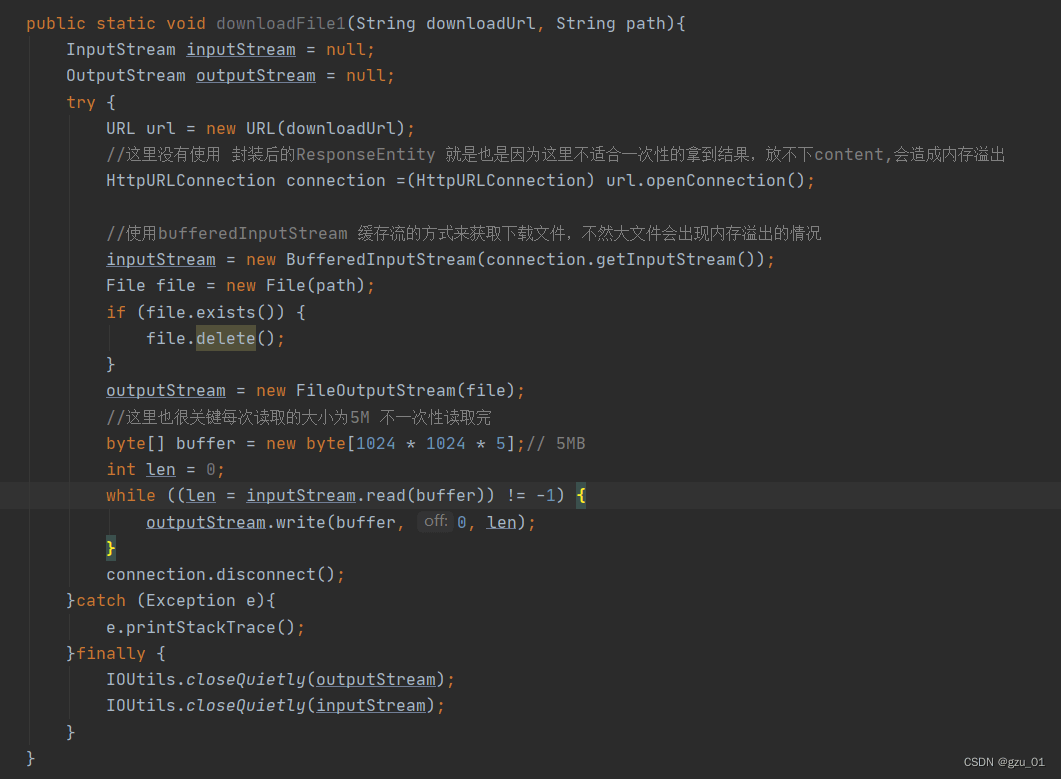
public static void downloadFile1(String downloadUrl, String path){
InputStream inputStream = null;
OutputStream outputStream = null;
try {
URL url = new URL(downloadUrl);
//这里没有使用 封装后的ResponseEntity 就是也是因为这里不适合一次性的拿到结果,放不下content,会造成内存溢出
HttpURLConnection connection =(HttpURLConnection) url.openConnection();
//使用bufferedInputStream 缓存流的方式来获取下载文件,不然大文件会出现内存溢出的情况
inputStream = new BufferedInputStream(connection.getInputStream());
File file = new File(path);
if (file.exists()) {
file.delete();
}
outputStream = new FileOutputStream(file);
//这里也很关键每次读取的大小为5M 不一次性读取完
byte[] buffer = new byte[1024 * 1024 * 5];// 5MB
int len = 0;
while ((len = inputStream.read(buffer)) != -1) {
outputStream.write(buffer, 0, len);
}
connection.disconnect();
}catch (Exception e){
e.printStackTrace();
}finally {
IOUtils.closeQuietly(outputStream);
IOUtils.closeQuietly(inputStream);
}
}
总结
到此这篇关于Java根据URL下载文件到本地的2种方式的文章就介绍到这了,更多相关Java根据URL下载文件到本地内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!