
C++无锁队列的原理与实现示例
作者:流星雨爱编程
1.无锁队列原理
1.1.队列操作模型
队列是一种非常重要的数据结构,其特性是先进先出(FIFO),符合流水线业务流程。在进程间通信、网络通信间经常采用队列做缓存,缓解数据处理压力。根据操作队列的场景分为:单生产者——单消费者、多生产者——单消费者、单生产者——多消费者、多生产者——多消费者四大模型。根据队列中数据分为:队列中的数据是定长的、队列中的数据是变长的。
(1)单生产者——单消费者

(2)多生产者——单消费者

(3)单生产者——多消费者

(4)多生产者——多消费者

(5)数据定长队列

(6)数据变长队列

1.2.无锁队列简介
生产环境中广泛使用生产者和消费者模型,要求生产者在生产的同时,消费者可以进行消费,通常使用互斥锁保证数据同步。但线程互斥锁的开销仍然比较大,因此在要求高性能、低延时场景中,推荐使用无锁队列。
1.3.CAS操作
CAS即Compare and Swap,是所有CPU指令都支持CAS的原子操作(X86中CMPXCHG汇编指令),用于实现实现各种无锁(lock free)数据结构。
CAS操作的C语言实现如下:
bool compare_and_swap ( int *memory_location, int expected_value, int new_value)
{
if (*memory_location == expected_value)
{
*memory_location = new_value;
return true;
}
return false;
}CAS用于检查一个内存位置是否包含预期值,如果包含,则把新值复赋值到内存位置。成功返回true,失败返回false。
(1)GGC对CAS支持
GCC4.1+版本中支持CAS原子操作。
bool __sync_bool_compare_and_swap (type *ptr, type oldval type newval, ...); type __sync_val_compare_and_swap (type *ptr, type oldval type newval, ...);
(2)Windows对CAS支持
Windows中使用Windows API支持CAS。
LONG InterlockedCompareExchange( LONG volatile *Destination, LONG ExChange, LONG Comperand );
(3)C++11对CAS支持
C++11 STL中atomic函数支持CAS并可以跨平台。
template< class T > bool atomic_compare_exchange_weak( std::atomic* obj,T* expected, T desired ); template< class T > bool atomic_compare_exchange_weak( volatile std::atomic* obj,T* expected, T desired );
其它原子操作如下:
Fetch-And-Add:一般用来对变量做+1的原子操作
Test-and-set:写值到某个内存位置并传回其旧值
2.无锁队列方案
2.1.boost方案
boost提供了三种无锁方案,分别适用不同使用场景。
boost::lockfree::queue是支持多个生产者和多个消费者线程的无锁队列。
boost::lockfree::stack是支持多个生产者和多个消费者线程的无锁栈。
boost::lockfree::spsc_queue是仅支持单个生产者和单个消费者线程的无锁队列,比boost::lockfree::queue性能更好。
Boost无锁数据结构的API通过轻量级原子锁实现lock-free,不是真正意义的无锁。
Boost提供的queue可以设置初始容量,添加新元素时如果容量不够,则总容量自动增长;但对于无锁数据结构,添加新元素时如果容量不够,总容量不会自动增长。
2.2.ConcurrentQueue
ConcurrentQueue是基于C++实现的工业级无锁队列方案。
GitHub:https://github.com/cameron314/concurrentqueue
ReaderWriterQueue是基于C++实现的单生产者单消费者场景的无锁队列方案。
GitHub:https://github.com/cameron314/readerwriterqueue
2.3.Disruptor
Disruptor是英国外汇交易公司LMAX基于JAVA开发的一个高性能队列。
GitHub:https://github.com/LMAX-Exchange/disruptor
3.无锁队列实现
3.1.环形缓冲区
RingBuffer是生产者和消费者模型中常用的数据结构,生产者将数据追加到数组尾端,当达到数组的尾部时,生产者绕回到数组的头部;消费者从数组头端取走数据,当到达数组的尾部时,消费者绕回到数组头部。
如果只有一个生产者和一个消费者,环形缓冲区可以无锁访问,环形缓冲区的写入index只允许生产者访问并修改,只要生产者在更新index前将新的值保存到缓冲区中,则消费者将始终看到一致的数据结构;读取index也只允许消费者访问并修改,消费者只要在取走数据后更新读index,则生产者将始终看到一致的数据结构。
空队列时,front与rear相等;当有元素进队,则rear后移;有元素出队,则front后移。
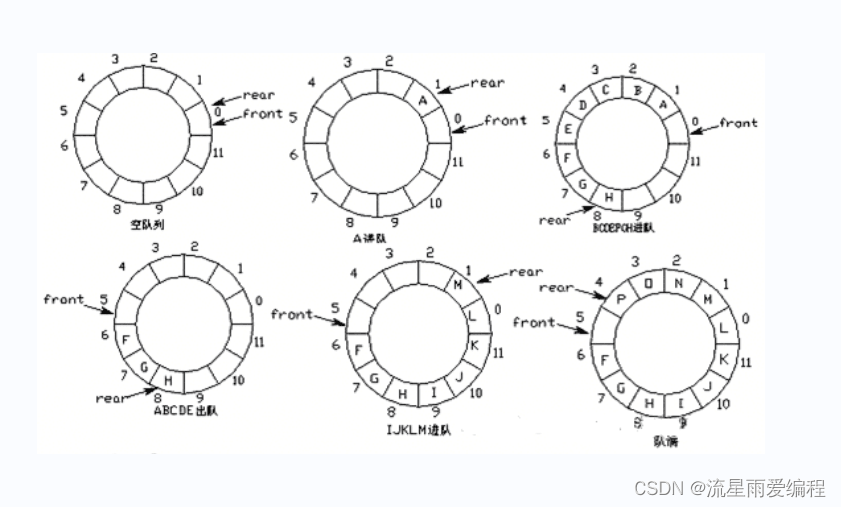
空队列时,rear等于front;满队列时,队列尾部空一个位置,因此判断循环队列满时使用(rear-front+maxn)%maxn。
入队操作:
data[rear] = x; rear = (rear+1)%maxn;
出队操作:
x = data[front]; front = (front+1)%maxn;
3.2.单生产者单消费者
对于单生产者和单消费者场景,由于read_index和write_index都只会有一个线程写,因此不需要加锁也不需要原子操作,直接修改即可,但读写数据时需要考虑遇到数组尾部的情况。
线程对write_index和read_index的读写操作如下:
(1)写操作。先判断队列时否为满,如果队列未满,则先写数据,写完数据后再修改write_index。
(2)读操作。先判断队列是否为空,如果队列不为空,则先读数据,读完再修改read_index。
3.3.多生产者单消费者
多生产者和单消费者场景中,由于多个生产者都会修改write_index,所以在不加锁的情况下必须使用原子操作。
3.4.RingBuffer实现
RingBuffer.hpp文件:
#pragma once
template <class T>
class RingBuffer
{
public:
RingBuffer(unsigned size): m_size(size), m_front(0), m_rear(0)
{
m_data = new T[size];
}
~RingBuffer()
{
delete [] m_data;
m_data = NULL;
}
inline bool isEmpty() const
{
return m_front == m_rear;
}
inline bool isFull() const
{
return m_front == (m_rear + 1) % m_size;
}
bool push(const T& value)
{
if(isFull())
{
return false;
}
m_data[m_rear] = value;
m_rear = (m_rear + 1) % m_size;
return true;
}
bool push(const T* value)
{
if(isFull())
{
return false;
}
m_data[m_rear] = *value;
m_rear = (m_rear + 1) % m_size;
return true;
}
inline bool pop(T& value)
{
if(isEmpty())
{
return false;
}
value = m_data[m_front];
m_front = (m_front + 1) % m_size;
return true;
}
inline unsigned int front()const
{
return m_front;
}
inline unsigned int rear()const
{
return m_rear;
}
inline unsigned int size()const
{
return m_size;
}
private:
unsigned int m_size;// 队列长度
int m_front;// 队列头部索引
int m_rear;// 队列尾部索引
T* m_data;// 数据缓冲区
};RingBufferTest.cpp测试代码:
#include <stdio.h>
#include <thread>
#include <unistd.h>
#include <sys/time.h>
#include "RingBuffer.hpp"
class Test
{
public:
Test(int id = 0, int value = 0)
{
this->id = id;
this->value = value;
sprintf(data, "id = %d, value = %d\n", this->id, this->value);
}
void display()
{
printf("%s", data);
}
private:
int id;
int value;
char data[128];
};
double getdetlatimeofday(struct timeval *begin, struct timeval *end)
{
return (end->tv_sec + end->tv_usec * 1.0 / 1000000) -
(begin->tv_sec + begin->tv_usec * 1.0 / 1000000);
}
RingBuffer<Test> queue(1 << 12);2u000
#define N (10 * (1 << 20))
void produce()
{
struct timeval begin, end;
gettimeofday(&begin, NULL);
unsigned int i = 0;
while(i < N)
{
if(queue.push(Test(i % 1024, i)))
{
i++;
}
}
gettimeofday(&end, NULL);
double tm = getdetlatimeofday(&begin, &end);
printf("producer tid=%lu %f MB/s %f msg/s elapsed= %f size= %u\n", pthread_self(), N * sizeof(Test) * 1.0 / (tm * 1024 * 1024), N * 1.0 / tm, tm, i);
}
void consume()
{
sleep(1);
Test test;
struct timeval begin, end;
gettimeofday(&begin, NULL);
unsigned int i = 0;
while(i < N)
{
if(queue.pop(test))
{
// test.display();
i++;
}
}
gettimeofday(&end, NULL);
double tm = getdetlatimeofday(&begin, &end);
printf("consumer tid=%lu %f MB/s %f msg/s elapsed= %f, size=%u \n", pthread_self(), N * sizeof(Test) * 1.0 / (tm * 1024 * 1024), N * 1.0 / tm, tm, i);
}
int main(int argc, char const *argv[])
{
std::thread producer1(produce);
std::thread consumer(consume);
producer1.join();
consumer.join();
return 0;
}编译:
g++ --std=c++11 RingBufferTest.cpp -o test -pthread

单生产者单消费者场景下,消息吞吐量为350万条/秒左右。
3.5.LockFreeQueue实现
LockFreeQueue.hpp:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <stdbool.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <sys/time.h>
#include <sys/mman.h>
#define SHM_NAME_LEN 128
#define MIN(a, b) ((a) > (b) ? (b) : (a))
#define IS_POT(x) ((x) && !((x) & ((x)-1)))
#define MEMORY_BARRIER __sync_synchronize()
template <class T>
class LockFreeQueue
{
protected:
typedef struct
{
int m_lock;
inline void spinlock_init()
{
m_lock = 0;
}
inline void spinlock_lock()
{
while(!__sync_bool_compare_and_swap(&m_lock, 0, 1)) {}
}
inline void spinlock_unlock()
{
__sync_lock_release(&m_lock);
}
} spinlock_t;
public:
// size:队列大小
// name:共享内存key的路径名称,默认为NULL,使用数组作为底层缓冲区。
LockFreeQueue(unsigned int size, const char* name = NULL)
{
memset(shm_name, 0, sizeof(shm_name));
createQueue(name, size);
}
~LockFreeQueue()
{
if(shm_name[0] == 0)
{
delete [] m_buffer;
m_buffer = NULL;
}
else
{
if (munmap(m_buffer, m_size * sizeof(T)) == -1) {
perror("munmap");
}
if (shm_unlink(shm_name) == -1) {
perror("shm_unlink");
}
}
}
bool isFull()const
{
#ifdef USE_POT
return m_head == (m_tail + 1) & (m_size - 1);
#else
return m_head == (m_tail + 1) % m_size;
#endif
}
bool isEmpty()const
{
return m_head == m_tail;
}
unsigned int front()const
{
return m_head;
}
unsigned int tail()const
{
return m_tail;
}
bool push(const T& value)
{
#ifdef USE_LOCK
m_spinLock.spinlock_lock();
#endif
if(isFull())
{
#ifdef USE_LOCK
m_spinLock.spinlock_unlock();
#endif
return false;
}
memcpy(m_buffer + m_tail, &value, sizeof(T));
#ifdef USE_MB
MEMORY_BARRIER;
#endif
#ifdef USE_POT
m_tail = (m_tail + 1) & (m_size - 1);
#else
m_tail = (m_tail + 1) % m_size;
#endif
#ifdef USE_LOCK
m_spinLock.spinlock_unlock();
#endif
return true;
}
bool pop(T& value)
{
#ifdef USE_LOCK
m_spinLock.spinlock_lock();
#endif
if (isEmpty())
{
#ifdef USE_LOCK
m_spinLock.spinlock_unlock();
#endif
return false;
}
memcpy(&value, m_buffer + m_head, sizeof(T));
#ifdef USE_MB
MEMORY_BARRIER;
#endif
#ifdef USE_POT
m_head = (m_head + 1) & (m_size - 1);
#else
m_head = (m_head + 1) % m_size;
#endif
#ifdef USE_LOCK
m_spinLock.spinlock_unlock();
#endif
return true;
}
protected:
virtual void createQueue(const char* name, unsigned int size)
{
#ifdef USE_POT
if (!IS_POT(size))
{
size = roundup_pow_of_two(size);
}
#endif
m_size = size;
m_head = m_tail = 0;
if(name == NULL)
{
m_buffer = new T[m_size];
}
else
{
int shm_fd = shm_open(name, O_CREAT | O_RDWR, 0666);
if (shm_fd < 0)
{
perror("shm_open");
}
if (ftruncate(shm_fd, m_size * sizeof(T)) < 0)
{
perror("ftruncate");
close(shm_fd);
}
void *addr = mmap(0, m_size * sizeof(T), PROT_READ | PROT_WRITE, MAP_SHARED, shm_fd, 0);
if (addr == MAP_FAILED)
{
perror("mmap");
close(shm_fd);
}
if (close(shm_fd) == -1)
{
perror("close");
exit(1);
}
m_buffer = static_cast<T*>(addr);
memcpy(shm_name, name, SHM_NAME_LEN - 1);
}
#ifdef USE_LOCK
spinlock_init(m_lock);
#endif
}
inline unsigned int roundup_pow_of_two(size_t size)
{
size |= size >> 1;
size |= size >> 2;
size |= size >> 4;
size |= size >> 8;
size |= size >> 16;
size |= size >> 32;
return size + 1;
}
protected:
char shm_name[SHM_NAME_LEN];
volatile unsigned int m_head;
volatile unsigned int m_tail;
unsigned int m_size;
#ifdef USE_LOCK
spinlock_t m_spinLock;
#endif
T* m_buffer;
};#define USE_LOCK
开启spinlock锁,多生产者多消费者场景
#define USE_MB
开启Memory Barrier
#define USE_POT
开启队列大小的2的幂对齐
LockFreeQueueTest.cpp测试文件:
#include "LockFreeQueue.hpp"
#include <thread>
//#define USE_LOCK
class Test
{
public:
Test(int id = 0, int value = 0)
{
this->id = id;
this->value = value;
sprintf(data, "id = %d, value = %d\n", this->id, this->value);
}
void display()
{
printf("%s", data);
}
private:
int id;
int value;
char data[128];
};
double getdetlatimeofday(struct timeval *begin, struct timeval *end)
{
return (end->tv_sec + end->tv_usec * 1.0 / 1000000) -
(begin->tv_sec + begin->tv_usec * 1.0 / 1000000);
}
LockFreeQueue<Test> queue(1 << 10, "/shm");
#define N ((1 << 20))
void produce()
{
struct timeval begin, end;
gettimeofday(&begin, NULL);
unsigned int i = 0;
while(i < N)
{
if(queue.push(Test(i >> 10, i)))
i++;
}
gettimeofday(&end, NULL);
double tm = getdetlatimeofday(&begin, &end);
printf("producer tid=%lu %f MB/s %f msg/s elapsed= %f size= %u\n", pthread_self(), N * sizeof(Test) * 1.0 / (tm * 1024 * 1024), N * 1.0 / tm, tm, i);
}
void consume()
{
Test test;
struct timeval begin, end;
gettimeofday(&begin, NULL);
unsigned int i = 0;
while(i < N)
{
if(queue.pop(test))
{
//test.display();
i++;
}
}
gettimeofday(&end, NULL);
double tm = getdetlatimeofday(&begin, &end);
printf("consumer tid=%lu %f MB/s %f msg/s elapsed= %f size= %u\n", pthread_self(), N * sizeof(Test) * 1.0 / (tm * 1024 * 1024), N * 1.0 / tm, tm, i);
}
int main(int argc, char const *argv[])
{
std::thread producer1(produce);
//std::thread producer2(produce);
std::thread consumer(consume);
producer1.join();
//producer2.join();
consumer.join();
return 0;
}多线程场景下,需要定义USE_LOCK宏,开启锁保护。
编译:
g++ --std=c++11 -O3 LockFreeQueueTest.cpp -o test -lrt -pthread

4.kfifo内核队列
4.1.kfifo内核队列简介
kfifo是Linux内核的一个FIFO数据结构,采用环形循环队列的数据结构来实现,提供一个无边界的字节流服务,并且使用并行无锁编程技术,即单生产者单消费者场景下两个线程可以并发操作,不需要任何加锁行为就可以保证kfifo线程安全。
4.2.kfifo内核队列实现
kfifo数据结构定义如下:
struct kfifo
{
unsigned char *buffer;
unsigned int size;
unsigned int in;
unsigned int out;
spinlock_t *lock;
};
// 创建队列
struct kfifo *kfifo_init(unsigned char *buffer, unsigned int size, gfp_t gfp_mask, spinlock_t *lock)
{
struct kfifo *fifo;
// 判断是否为2的幂
BUG_ON(!is_power_of_2(size));
fifo = kmalloc(sizeof(struct kfifo), gfp_mask);
if (!fifo)
return ERR_PTR(-ENOMEM);
fifo->buffer = buffer;
fifo->size = size;
fifo->in = fifo->out = 0;
fifo->lock = lock;
return fifo;
}
// 分配空间
struct kfifo *kfifo_alloc(unsigned int size, gfp_t gfp_mask, spinlock_t *lock)
{
unsigned char *buffer;
struct kfifo *ret;
// 判断是否为2的幂
if (!is_power_of_2(size))
{
BUG_ON(size > 0x80000000);
// 向上扩展成2的幂
size = roundup_pow_of_two(size);
}
buffer = kmalloc(size, gfp_mask);
if (!buffer)
return ERR_PTR(-ENOMEM);
ret = kfifo_init(buffer, size, gfp_mask, lock);
if (IS_ERR(ret))
kfree(buffer);
return ret;
}
void kfifo_free(struct kfifo *fifo)
{
kfree(fifo->buffer);
kfree(fifo);
}
// 入队操作
static inline unsigned int kfifo_put(struct kfifo *fifo, const unsigned char *buffer, unsigned int len)
{
unsigned long flags;
unsigned int ret;
spin_lock_irqsave(fifo->lock, flags);
ret = __kfifo_put(fifo, buffer, len);
spin_unlock_irqrestore(fifo->lock, flags);
return ret;
}
// 出队操作
static inline unsigned int kfifo_get(struct kfifo *fifo, unsigned char *buffer, unsigned int len)
{
unsigned long flags;
unsigned int ret;
spin_lock_irqsave(fifo->lock, flags);
ret = __kfifo_get(fifo, buffer, len);
//当fifo->in == fifo->out时,buufer为空
if (fifo->in == fifo->out)
fifo->in = fifo->out = 0;
spin_unlock_irqrestore(fifo->lock, flags);
return ret;
}
// 入队操作
unsigned int __kfifo_put(struct kfifo *fifo, const unsigned char *buffer, unsigned int len)
{
unsigned int l;
//buffer中空的长度
len = min(len, fifo->size - fifo->in + fifo->out);
// 内存屏障:smp_mb(),smp_rmb(), smp_wmb()来保证对方观察到的内存操作顺序
smp_mb();
// 将数据追加到队列尾部
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
memcpy(fifo->buffer, buffer + l, len - l);
smp_wmb();
//每次累加,到达最大值后溢出,自动转为0
fifo->in += len;
return len;
}
// 出队操作
unsigned int __kfifo_get(struct kfifo *fifo, unsigned char *buffer, unsigned int len)
{
unsigned int l;
//有数据的缓冲区的长度
len = min(len, fifo->in - fifo->out);
smp_rmb();
l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));
memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
memcpy(buffer + l, fifo->buffer, len - l);
smp_mb();
fifo->out += len; //每次累加,到达最大值后溢出,自动转为0
return len;
}
static inline void __kfifo_reset(struct kfifo *fifo)
{
fifo->in = fifo->out = 0;
}
static inline void kfifo_reset(struct kfifo *fifo)
{
unsigned long flags;
spin_lock_irqsave(fifo->lock, flags);
__kfifo_reset(fifo);
spin_unlock_irqrestore(fifo->lock, flags);
}
static inline unsigned int __kfifo_len(struct kfifo *fifo)
{
return fifo->in - fifo->out;
}
static inline unsigned int kfifo_len(struct kfifo *fifo)
{
unsigned long flags;
unsigned int ret;
spin_lock_irqsave(fifo->lock, flags);
ret = __kfifo_len(fifo);
spin_unlock_irqrestore(fifo->lock, flags);
return ret;
}4.3.kfifo设计要点
(1)保证buffer size为2的幂
kfifo->size值在调用者传递参数size的基础上向2的幂扩展,目的是使kfifo->size取模运算可以转化为位与运算(提高运行效率)。kfifo->in % kfifo->size转化为 kfifo->in & (kfifo->size – 1)
保证size是2的幂可以通过位运算的方式求余,在频繁操作队列的情况下可以大大提高效率。
(2)使用spin_lock_irqsave与spin_unlock_irqrestore 实现同步。
Linux内核中有spin_lock、spin_lock_irq和spin_lock_irqsave保证同步。
static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}
static inline void __raw_spin_lock_irq(raw_spinlock_t *lock)
{
local_irq_disable();
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}spin_lock比spin_lock_irq速度快,但并不是线程安全的。spin_lock_irq增加调用local_irq_disable函数,即禁止本地中断,是线程安全的,既禁止本地中断,又禁止内核抢占。
spin_lock_irqsave是基于spin_lock_irq实现的一个辅助接口,在进入和离开临界区后,不会改变中断的开启、关闭状态。
如果自旋锁在中断处理函数中被用到,在获取自旋锁前需要关闭本地中断,spin_lock_irqsave实现如下:
A、保存本地中断状态;
B、关闭本地中断;
C、获取自旋锁。
解锁时通过 spin_unlock_irqrestore完成释放锁、恢复本地中断到原来状态等工作。
(3)线性代码结构
代码中没有任何if-else分支来判断是否有足够的空间存放数据,kfifo每次入队或出队只是简单的 +len 判断剩余空间,并没有对kfifo->size 进行取模运算,所以kfifo->in和kfifo->out总是一直增大,直到unsigned in超过最大值时绕回到0这一起始端,但始终满足:kfifo->in - kfifo->out <= kfifo->size。
(4)使用Memory Barrier
mb():适用于多处理器和单处理器的内存屏障。
rmb():适用于多处理器和单处理器的读内存屏障。
wmb():适用于多处理器和单处理器的写内存屏障。
smp_mb():适用于多处理器的内存屏障。
smp_rmb():适用于多处理器的读内存屏障。
smp_wmb():适用于多处理器的写内存屏障。
Memory Barrier使用场景如下:
A、实现同步原语(synchronization primitives)
B、实现无锁数据结构(lock-free data structures)
C、驱动程序
程序在运行时内存实际访问顺序和程序代码编写的访问顺序不一定一致,即内存乱序访问。内存乱序访问行为出现是为了提升程序运行时的性能。内存乱序访问主要发生在两个阶段:
A、编译时,编译器优化导致内存乱序访问(指令重排)。
B、运行时,多CPU间交互引起内存乱序访问。
Memory Barrier能够让CPU或编译器在内存访问上有序。Memory barrier前的内存访问操作必定先于其后的完成。Memory Barrier包括两类:
A、编译器Memory Barrier。
B、CPU Memory Barrier。
通常,编译器和CPU引起内存乱序访问不会带来问题,但如果程序逻辑的正确性依赖于内存访问顺序,内存乱序访问会带来逻辑上的错误。
在编译时,编译器对代码做出优化时可能改变实际执行指令的顺序(如GCC的O2或O3都会改变实际执行指令的顺序)。
在运行时,CPU虽然会乱序执行指令,但在单个CPU上,硬件能够保证程序执行时所有的内存访问操作都是按程序代码编写的顺序执行的,Memory Barrier没有必要使用(不考虑编译器优化)。为了更快执行指令,CPU采取流水线的执行方式,编译器在编译代码时为了使指令更适合CPU的流水线执行方式以及多CPU执行,原本指令就会出现乱序的情况。在乱序执行时,CPU真正执行指令的顺序由可用的输入数据决定,而非程序员编写的顺序。
到此这篇关于C++无锁队列的原理与实现示例的文章就介绍到这了,更多相关C++ 无锁队列内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!