
Java集合中的LinkedHashMap使用解析
作者:Brain_L
前言
HashMap是根据key的hash值进行散列存储的,每个节点间是无序的。而LinkedHashMap可以实现有序的存储键值对。
LinkedHashMap是继承于HashMap的,所以它的很多属性和方法都是HashMap中的,那么它是怎么实现有序存储的呢?
1、属性
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
final boolean accessOrder;
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}三个重要属性:head、tail、accessOrder,一个重要结构:基础Entry
从注释中都可以看出他们的用途,head节点指向最先存进map的键值对,tail节点指向最后存进map的键值对
节点Entry继承自HashMap的基础节点Node,然后又新增了属性before和after,看名字就知道它们是用来和前后节点串成双向链表的。
accessOrder决定了链表中键值对是依照什么顺序来相互串联的,true表示键值对的访问顺序,false表示插入顺序,默认是false。
自此,LinkedHashMap的思想就出来了,本身还是和HashMap一样都是根据Hash求索引,散列等等。同时它自身的每个节点又根据访问顺序或者插入顺序串联成双向链表,head、tail指向链表的头和尾。
那么它是怎么实现有序存储的呢?
2、方法
看下它的方法,发现它没有覆写put方法,只覆写了get方法
看下HashMap中的put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}关键就在newNode这个地方(当然newNode在HashMap中不止此处会用到),LinkedHashMap复写了这个方法。
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
// link at the end of list
//新生成的节点放到双向链表的队尾
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}所以,每个新的节点生成的时候,都会把它和前一个节点串联起来,而且队首head指向第一个生成的节点,队尾tail指向最新生成的节点。
看个例子
public static void main(String[] args) {
Map<String, String> map = new LinkedHashMap<>();
map.put("k1", "v1");
map.put("k2", "v2");
Set<Map.Entry<String, String>> entries = map.entrySet();
for (Map.Entry entry : entries) {
log.info("key:{}, value:{}", entry.getKey(), entry.getValue());
}
}执行过程如下:
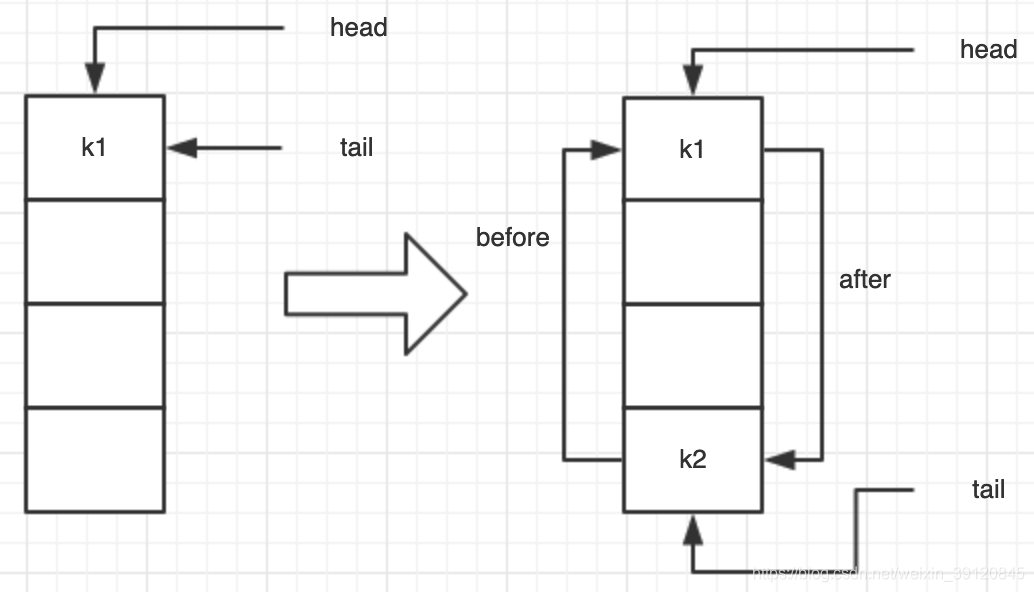
这里只做示意,如果后面hash冲突,需要在桶上加节点或树节点,按照顺序也是会和前后的节点进行串联,和上图的原理类似。
这是按照插入顺序进行排序的。如果想按访问顺序进行排序,则需要调用另一个构造函数。
可以看到,当指定访问顺序进行排序的时候,最新被访问的节点会被放到链表的末尾。
如何实现呢?看下HashMap的put方法
public static void main(String[] args) {
Map<String, String> map = new LinkedHashMap<>(16, 0.75f, true);
map.put("k1", "v1");
map.put("k2", "v2");
map.put("k3", "v3");
Set<Map.Entry<String, String>> entries = map.entrySet();
for (Map.Entry entry : entries) {
log.info("key:{}, value:{}", entry.getKey(), entry.getValue());
}
map.get("k2");
for (Map.Entry entry : entries) {
log.info("key:{}, value:{}", entry.getKey(), entry.getValue());
}
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
//其他构造函数会将accessOrder设置为false
this.accessOrder = accessOrder;
}输出结果为:
key:k1, value:v1
key:k2, value:v2
key:k3, value:v3
key:k1, value:v1
key:k3, value:v3
key:k2, value:v2
HashMap中专门定义了三个给LinkedHashMap覆写的方法,用于做一些后处理。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }覆写的这三个方法都是在进行完基本的键值对插入删除操作后,对双向链表进行调整。
如afterNodeInsertion方法就是在Hash数组插入新的Node节点后,根据缓存机制(removeEldestEntry默认是缓存机制不生效,可以覆写实现自己的缓存机制)决定是否删除双向链表head节点所指向的节点。
当键值对第一次put进来时,如果是生成新的节点调用afterNodeInsertion,则此时和插入顺序一致,该节点位于队尾。当调用get方法时
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)//访问顺序排序会调用后处理,将节点调整到队尾
afterNodeAccess(e);
return e.value;
}此时会调用afterNodeAccess方法,将访问的这个节点调整到队尾。
如果在put时,更新某个节点的value,此时也会调用afterNodeAccess,即实现了一旦某个节点被访问(插入、获取、更新)时,该节点被调整到队尾。
删除时,会调用afterNodeRemoval将节点从双向链表中移除,和之前的原来类似,不再展开。
3、用途
LinkedHashMap能用来做什么呢,由于它自身维护了一个双向链表,保证节点的顺序是按照插入或者访问的顺序连接的,所以这种特性在某些场景下就很有用,比如LRU。
什么是LRU,Least Recently Used,最近最少使用。比如一个Map我最多允许存放10个键值对,那么当第11个键值对要插入的时候,我要把已有的10个中里使用频率最低的一个移除。
@Slf4j
public class MapTest {
public static void main(String[] args) {
LRUExample<String, String> lruExample = new LRUExample<>(4);
int i = 0;
for (; i < 4; i++) {
lruExample.put("k" + i, "v" + i);
}
log.info("插入完4个键值对后");
Set<Map.Entry<String, String>> entries = lruExample.entrySet();
for (Map.Entry<String, String> entry : entries) {
log.info("key:{}, value:{}", entry.getKey(), entry.getValue());
}
lruExample.get("k1");
log.info("访问k1后");
for (Map.Entry<String, String> entry : entries) {
log.info("key:{}, value:{}", entry.getKey(), entry.getValue());
}
lruExample.put("k5", "v5");
log.info("插入完第5个键值对后");
for (Map.Entry<String, String> entry : entries) {
log.info("key:{}, value:{}", entry.getKey(), entry.getValue());
}
}
}
class LRUExample<K, V> extends LinkedHashMap<K, V> {
final int maxSize;
LRUExample(int maxSize) {
super(maxSize, 0.75f, true);
this.maxSize = maxSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > maxSize;
}
}输出结果为:
插入完4个键值对后
key:k0, value:v0
key:k1, value:v1
key:k2, value:v2
key:k3, value:v3
访问k0后
key:k1, value:v1
key:k2, value:v2
key:k3, value:v3
key:k0, value:v0
插入完第5个键值对后
key:k2, value:v2
key:k3, value:v3
key:k0, value:v0
key:k5, value:v5
当插入到第5个时,此时访问频率最低的就是head节点指向的k1-v1,所以当k5-v5插入的时候,触发了缓存清除时,k0-v0被移除,k5-v5加入到队尾。
到此这篇关于Java集合中的LinkedHashMap使用解析的文章就介绍到这了,更多相关Java集合LinkedHashMap内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!