
jvm堆外内存排查图文举例详解
作者:Xd聊架构
前言
内存泄漏想必大家并不陌生,对于jvm的内存泄漏,有很多排查手段和方便的排查工具,例如MAL,但是对于非jvm的内存,如直接内存的使用,排查起来较为麻烦,下面介绍一下相关的排查手段
一、堆外内存排查
1.背景
在一次内存检查的过程中,意外发现在linux的java进程内存占用,远高于jvm的内存设定最大值(堆+非堆),第一时间是考虑java可以采用直接内存,如mmap对内存进行使用,但经过排查,发现并非如此,下面看一下排查过程
2.内存对比
首先通过top,可以看到java进行使用了4.2g的内存,且pid为2730
ps -ef|grep java top -pid 2730

因为我知道我的jvm最大内存设置为3G左右,所以第一时间就没有去看JVM的最大值,如果不确定,优先查看JVM的堆、非堆的内存分配情况,本次忽略,直接查看NMT。
为了观察java进程堆外内存的占用,JVM启动参数中添加参数:-XX:NativeMemoryTracking=summary,这个参数对jvm可能会有5%左右的性能损耗,所以生产环境不推荐开启。
同时,-XX:+DisableExplicitGC:禁止显示GC,即代码中声明的 System.gc();//建议jvm进行gc 不再生效。在jdk源码中使用nio申请堆外内存时,堆外内存不足时会执行 System.gc() 进行堆外内存的回收,所以,堆外内存使用较多时不推荐配置 -XX:+DisableExplicitGC。
最后,为了防止堆外内存的溢出,jvm启动参数可以换添加:-XX:MaxDirectMemorySize=1024M
开启NMT后,通过jcmd命令查看内存情况
jcmd 2730 VM.native_memory scale=MB

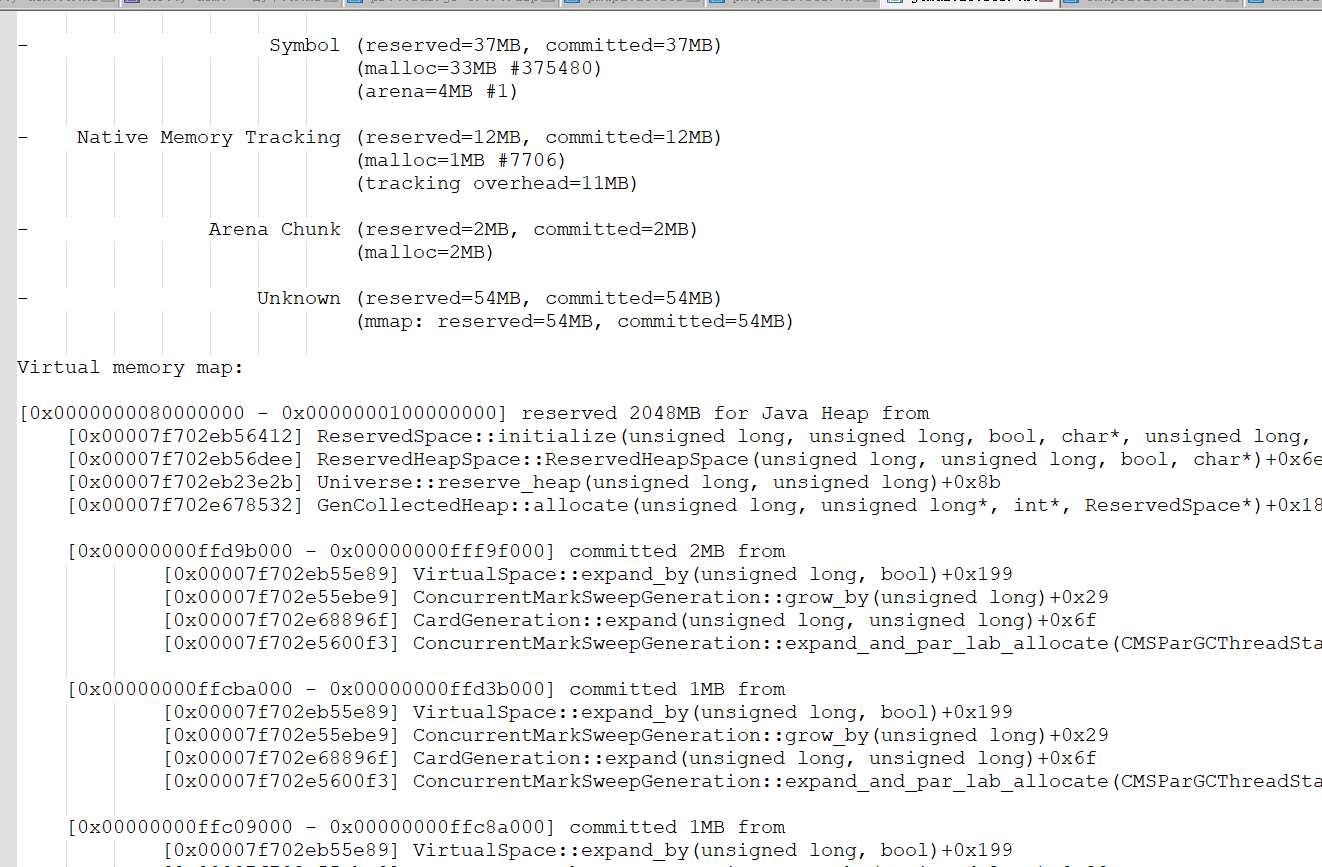
Heap(堆)、Class(元空间)、Thread(java线程栈,含GC本地线程)、Code(本地字节码,即JIT存储热点代码地方)、GC(JVM GC额外占用的,例如G1中的Remembered Set等数据结构)、Internal(Direct Buffer直接内存,例如nio)等占用。Native Memory Tracking表示该功能自身占用的部分。
JVM 的内存大致分为下面这几个部分:
- 堆(Heap):young、old 区域等
- 线程栈(Thread Stack):每个线程栈预留 1M 的线程栈大小
- 非堆(Non-heap):包括 code_cache、metaspace 等
- 堆外内存:unsafe.allocateMemory 和 DirectByteBuffer 申请的堆外内存
- native (C/C++ 代码)申请的内存
- 还有 JVM 运行本身需要的内存,比如 GC 等
可以看到JVM只使用了3G左右,其中Internal的39M为直接内存的使用,那么剩余的1.2G非JVM的使用。因为jcmd命令显示的内存包含堆内内存、Code区域、通过unsafe.allocateMemory和DirectByteBuffer申请的内存,但是不包含其他Native Code(C代码)申请的堆外内存。所以猜测是使用Native Code申请内存所导致的问题。
其他jcmd可用命令:
查看java进程内存占用详细情况(-XX:NativeMemoryTracking=summary,关闭NMT命令:jcmd pid VM.native_memory shutdown): jcmd pid VM.native_memory scale=MB 保存java进程内存占用情况的基准版本: jcmd pid VM.native_memory scale=MB baseline 与基准版本进行比较(若怀疑存在内存泄漏,可过段时间再执行观察): jcmd pid VM.native_memory scale=MB summary.diff
3.堆外内存检查
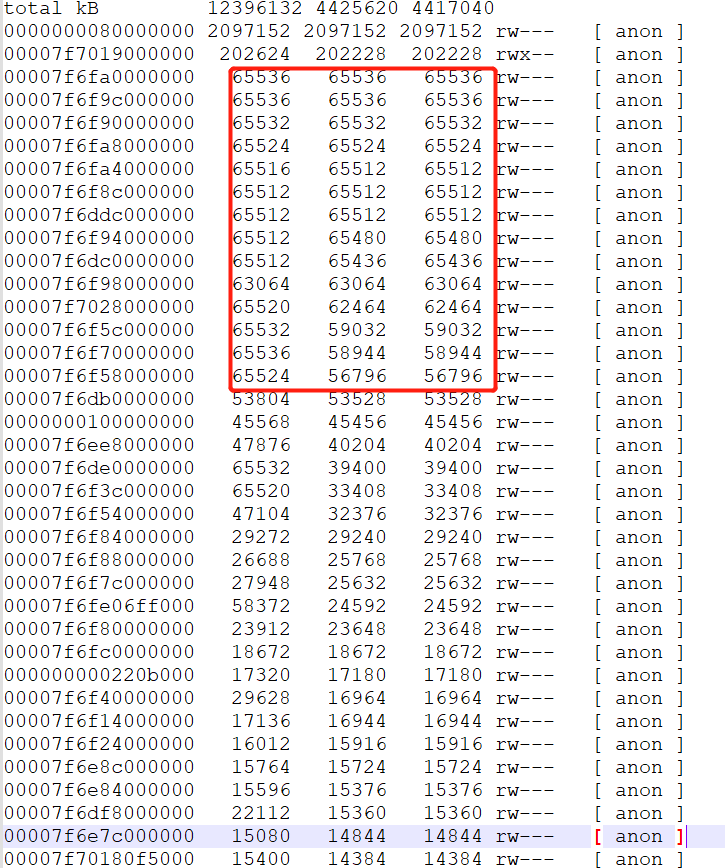
通过pmap打印内存的分布情况,并从打到小排序
pmap 2730 -x | sort -k 3 -n -r > /tmp/pmap20230131
打印jcmd内存使用明细
jcmd 2730 VM.native_memory detail scale=MB > /tmp/jcmd20230131.txt
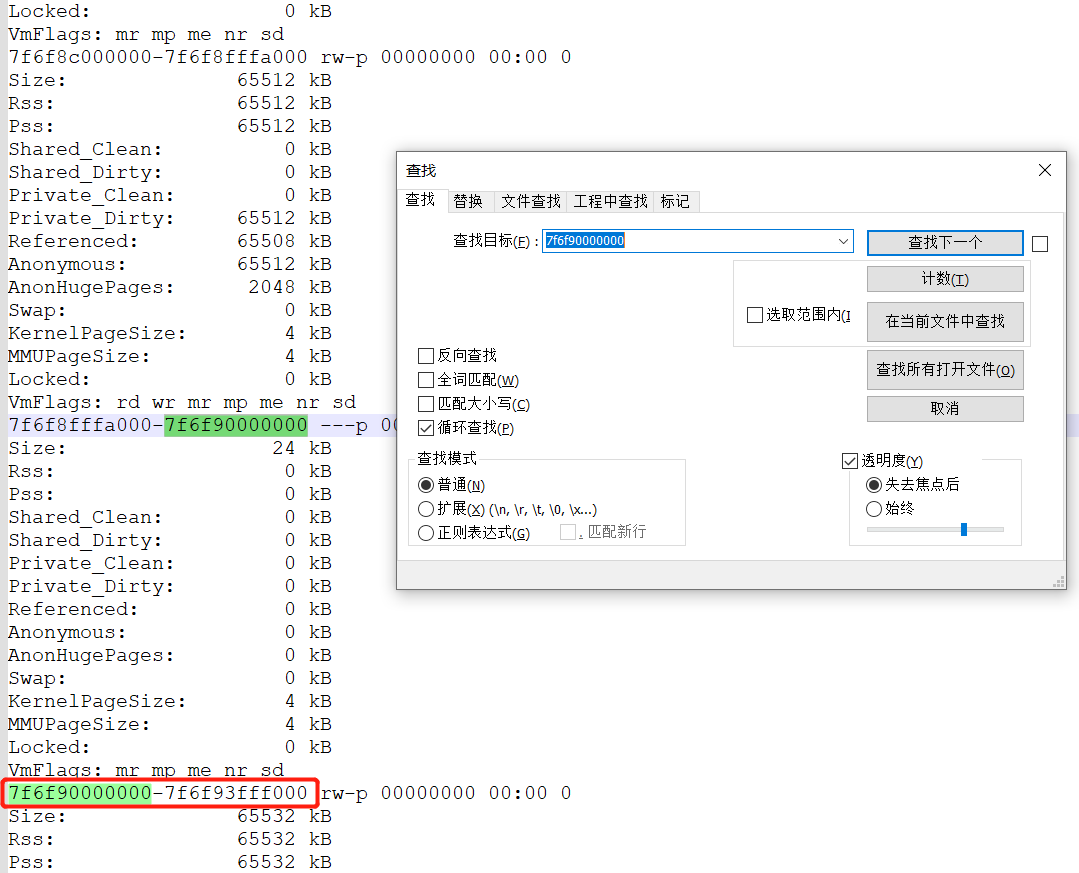
在pmap文件中,发现大量的64M的地址;而这些地址空间不在jcmd命令所给出的地址空间里面(例如通过pmap其中一个内存地址7f6f90000000,去jcmd明细中搜索,无法搜到即为没有在jvm中有引用),基本上就断定就是这些64M的内存所导致。
4.排查堆外内存
因猜测是Native Code所引起,Java层面的工具不便于排查此类问题,只能使用系统层面的工具去定位问题。
1.使用smaps查看内存的起始地址
cat /proc/2730/smaps > /tmp/smaps20230131.txt
以上述7f6f90000000地址为例,因在jcmd中无法找到7f6f90000000地址的内容,说明非jvm内存,在smaps文件中搜索7f6f90000000的起始地址。
2.使用gdb调试工具打印上述怀疑的内存地址里面存储的内容(注:gdb从进入到退出的中间时刻,会使java进程无法访问,处于挂起状态,生产环境小心使用)。
#进入gdb gdb -pid 2730 #打印内存地址地址内容(0x00007f6f90000000 0x00007f6f93fff000)为开始地址和结束地址 dump memory mem.bin 0x00007f6f90000000 0x00007f6f93fff000 #退出 quit #将文本以字符串输出 strings mem.bin > /tmp/mem20230131.txt
因进入gdb会导致进程无法访问,建议使用下面的方式执行命令
#0x00007f6f90000000 可以写成0x7f6f90000000 gdb --batch --pid 2730-ex "dump memory /tmp/ipo02061143.bin 0x7f6f90000000 0x7f6f93fff000"
可以看看里面有一些报错和具体的调用方法等,根据内存里面的内容进行逐一检查即可
5.glibc内存泄露
像上述的问题,内存内容里面没有可疑点,并且pmap打印的内容中有大量的64M内存区域,由此可发现,这是linux经典的glibc内存泄露问题,后续会专门写一篇文章介绍linux内存管理以及glibc相关的原理,这里先直接说明结论。
原因:
glibc 的内存分配策略导致的碎片化内存回收问题,导致看起来像是内存泄露,那有没有更好一点的对碎片化内存的 malloc 库呢?业界常见的有 google 家的 tcmalloc 和 facebook 家的 jemalloc。
tcmalloc
#安装 yum install gperftools-libs.x86_64 #使用 LD_PRELOAD 挂载 export LD_PRELOAD="/usr/lib64/libtcmalloc.so.4.4.5"
注意 java 应用要重启
jemalloc
#安装 yum install epel-release -y yum install jemalloc -y #使用 LD_PRELOAD 挂载 export LD_PRELOAD="/usr/lib64/libjemalloc.so.1"
使用 jemalloc 后,RSS 内存呈周期性波动,波动范围约 2 个百分点以内,基本控制住了
总结
到此这篇关于jvm堆外内存排查的文章就介绍到这了,更多相关jvm堆外内存排查内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!