
浅谈正则表达式回溯陷阱
作者:JebLin02
一、匹配场景
判断一个句子是不是正规英文句子
text = "I am a student"
一个正常的英文句子如上,英文单词 + 空格隔开
英文单词 = 多个英文字符 [a-zA-Z]
空格用 \s 表示
那么一个句子就是单词 + 空格(一个或者多个,最后那个单词是0个)(可能有多个单词+空格)+ 最后一个句号 .
那正则就是
^([a-zA-Z]+(\s)*)+$
JAVA代码
public static void main(String[] args) {
String text = "I am a good student";
String regex = "^([a-zA-Z]+(\\s)*)+$";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(text);
System.out.println(matcher.find());
System.out.println(matcher.group(0));
}输出结果:
true
I am a good student
二、性能测试
regex101: build, test, and debug regex.
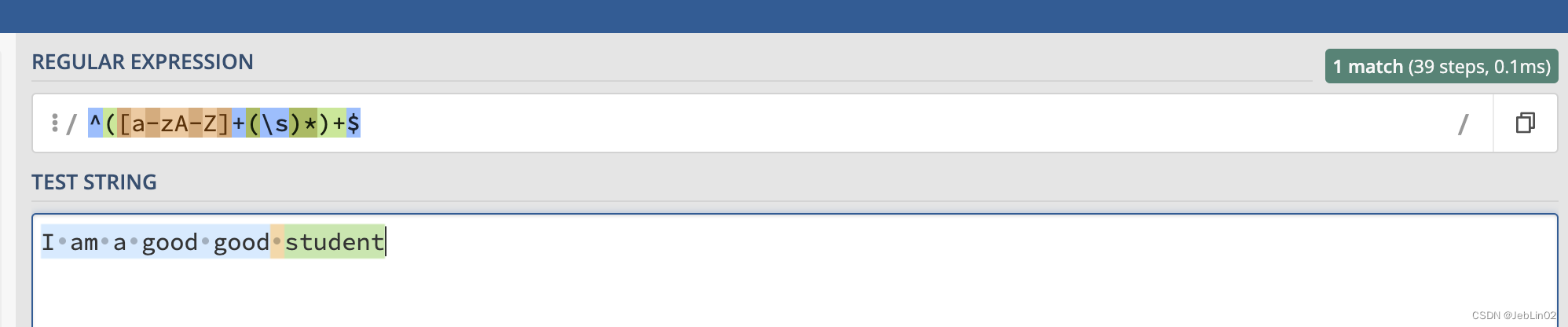
句子改成:I am a good good student

匹配成功了。39 step,耗时0.1ms,
但是假如把句子拉长点,最后加上一个问号 ?
I am a good good student?

83408 step,耗时5.4ms
假如把句子再拉长点,那么直接就干爆CPU,耗时指数增长,
为啥会这样呢?
三、正则的回溯陷阱
1、了解下NFA与DFA
- DFA (Deterministic finite automaton) 确定型有穷自动机
- NFA (Non-deterministic finite automaton) 非确定型有穷自动机
DFA :遍历text字符串,去和Pattern匹配
NFA:遍历Pattern,去与text匹配
DFA(是电动机) 和NFA(汽油机) 都有很长的历史,不过,正如汽油机一样,NFA 的历史更长一些。也有些系统采用了混合引擎,它们会根据任务的不同选择合适的引擎(甚至对同一表达式中的不同部分采用不同的引擎,以求得功能与速度之间的最佳平衡)。 ——《精通正则表达式》
绝大多数编程语言都选择的引擎——NFA (非确定型有穷自动机) 引擎

2、NFA的回溯
字符串 :abc
表达式:a(d|b)c




注意这个位置回退!!!

3、简易例子分析
表达式 = ^(a*)+$ 文本 = aaaaaaaaaaaaaaab
走了16w步,花了7.3ms

- 首先 (a*) 已经匹配到 aaaaaaaaaaaaaaa 了,
- (a*)+ 也匹配到 aaaaaaaaaaaaaaa ,
- 结束符$去匹配的时候,发现text不是结束,而是一个b
- 那吐出最后的a,变成 (aaaaaaaaaaaaaa) a ,没匹配上,继续吐
a* a* (aaaaaaaaaaaaa) (aa) a* a* a* (aaaaaaaaaaaaa) (a)(a) a* a* (aaaaaaaaaaaa) (aaa) a* a* a* (aaaaaaaaaaaa) (aa)(a) a* a* a* a* (aaaaaaaaaaaa) (a)(a)(a) --> 吐到最后 (a)(a)(a)(a)(a)(a)(a)(a)(a)(a)(a)(a)(a)(a)(a)
直接干爆CPU
4、咋优化?
1、对于 ^(a*)+$
直接把表达式
^(a*)+$
改成 ^(a*)$
把后面的 + 号去掉。
直接就是 5 Step,0.1ms

2、对于 ^([a-zA-Z]+(\s)*)+$
把后面的 + 号去掉。就不回溯了,
但是匹配不上,因为语句有问题,就是空格必须存在,但是最后的空格不存在

所以改成 :^[a-zA-Z]+(\s[a-zA-Z]+)*$
遇到问号也不回溯

去掉问号也匹配上了

到此这篇关于浅谈正则表达式回溯陷阱的文章就介绍到这了,更多相关正则表达式回溯陷阱内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!