
C++快速排序及优化方案详解
作者:大庆指针
1. 快速排序的流程
- 首先设定一个分界值,通过该分界值将数组分成左右两部分。
- 将大于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边,而等于分分界值的部分放在相对中间的部分。此时,左边部分中各元素都小于分界值,而右边部分中各元素都大于分界值,相对中间的部分的的数据等于分界值。
- 然后,左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
- 重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左、右两个部分各数据排序完成后,整个数组的排序也就完成了。
2. 快速排序的实现
原始的快速排序相对来说会比较熟悉点,大致的部分流程图如图所示:
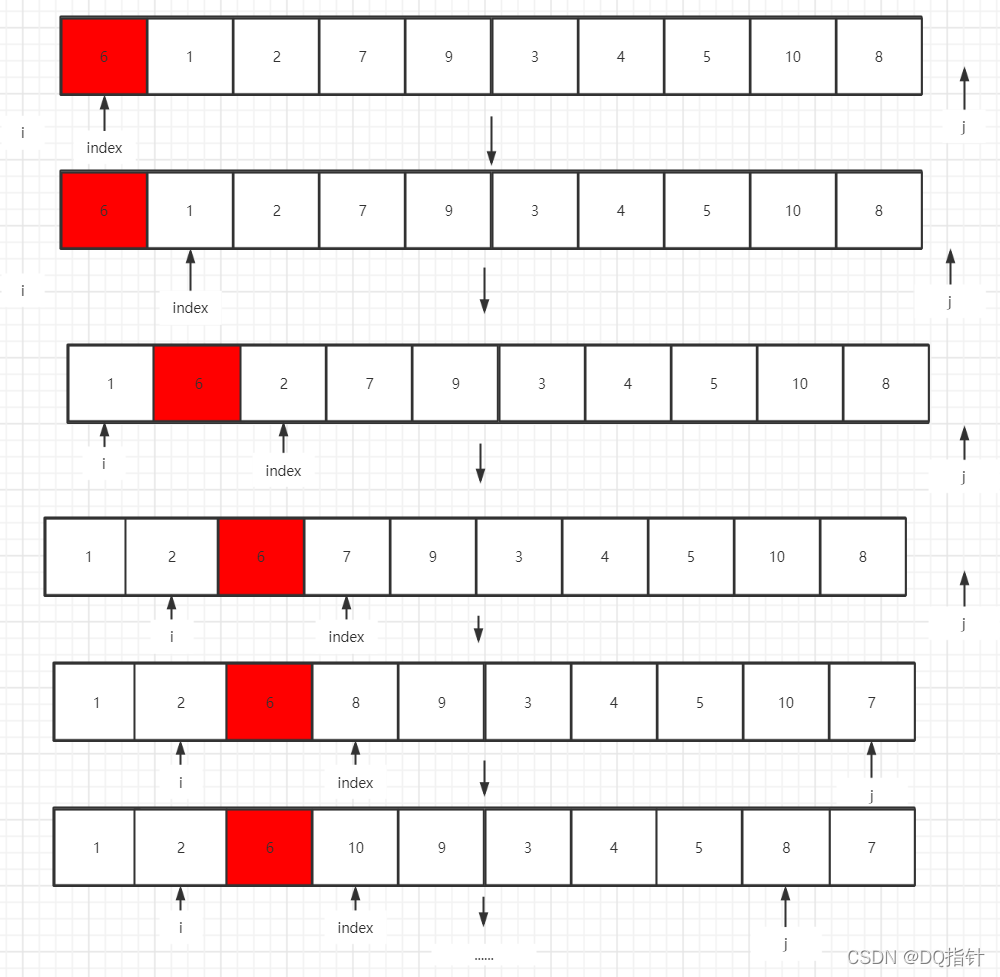
直接上代码:
#include<iostream>
#include<string>
#include<vector>
#include<time.h>
using namespace std;
//三色旗原理代码部分
pair<int, int> Quick(vector<int>& vec, int L, int R)
{
int temp = vec[L];//基准值
int i = L - 1;//左边界
int j = R + 1;//右边界
int index = L;//交换变量
while (index < j)
{
if (vec[index] < temp)
{
swap(vec[index++], vec[++i]);
}
else if (vec[index] > temp)
{
swap(vec[index], vec[--j]);
}
else
{
index++;
}
}
pair<int, int> p = make_pair(i, j);//存储下次排序的左右边界,
return p;
}
void Quick_sort(vector<int>& vec, int L, int R)
{
if (L >= R)return;//递归结束的标志
pair<int, int> p = Quick(vec, L, R);
Quick_sort(vec, L, p.first);//将数组的左部分进行排序
Quick_sort(vec, p.second, R);//将数组的右部分进行排序
}
int main()
{
vector<int> vec = { 5,6,3,7,2,8 };
Quick_sort(vec, 0, vec.size() - 1);
for (auto it : vec)
{
cout << it << " ";
}
return 0;
}时间复杂度计算
快速排序的最优的情况时的时间复杂度为O(N*logN) 因为最优解在排序过程中每次都利用递归将数组不断二分,并且不断二分过程次相当于二分法,而二分的时间复杂度为logN(这里的log是以2为底的),每次二分的各个子数组的和均为n个元素,在排序过程中所有元素在不同的递归过程中均会被遍历比较,所以每次都会有N个元素会被遍历,即时间复杂度为:O(N*logN) 最坏的情况时的时间复杂度为O(N^2) 这种情况是当数组有序的情况下,每次基准值都是取了数组中的最小值或最大值,而且每次递归都只是排除了基准值那个元素,这里就很像冒泡排序不断将子数组中最值排除掉,而冒泡排序的时间复杂度为O(N^2)。 因此最坏情况下的时间复杂度为O(N^2)。
3. 快速排序优化
3.1 随机获取基准值进行优化
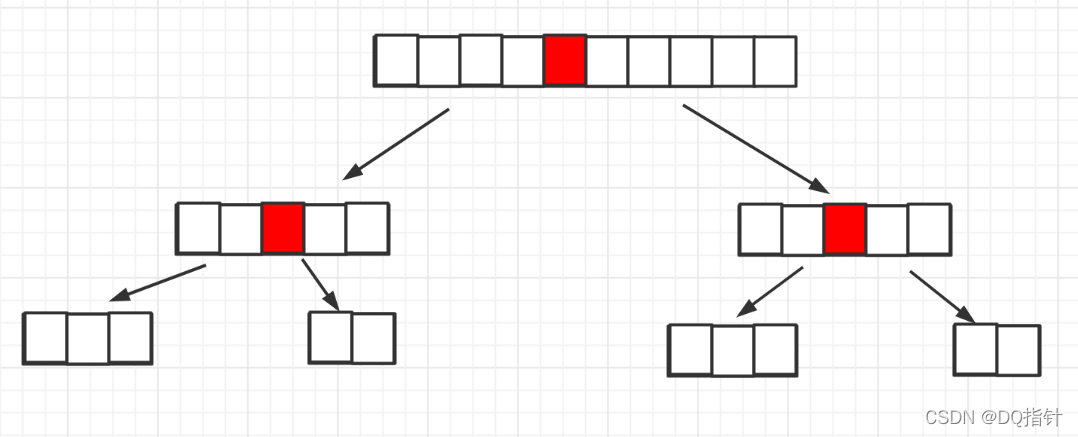
上一节我们自己动手写的一个快速排序的算法,在进行毫无规则的数组排序过程中表现得非常好,但是,当我们去百万,十万级别量的数据进行排序并且高度的有序化时,我们会发现此时程序运行的过程中,发现快速排序的效率变得异常的低下,会比相同数据量的数组中的数据是毫无规则时效率低得多了,近似退回了O(n^2)的复杂度,而此时程序则需要等待非常长的时间才能执行完全。 在编写快排代码的过程中,我们是利用递归来对数组进行划分的,这和归并排序里面的利用递归使得不断的二分才能达到O(n*logn)的时间复杂度相似,在快速排序中最好的情况就是如同归并一样,每次都是二分,这种情况的时间复杂度是最佳的时间复杂度O(n*logn)。如图:
但是当数组高度有序化或者数组本来就是有序的时候,这个时候数组数据呈现出一边倒的趋势此时快速排序的时间复杂度达到最坏的情况逼近O(n^2) 甚至达到为O(n^2),这样的快速排序远远达不到我们的需求,如图:

在这种情况下我们可以通过随机获取每次排序的基准值来进行优化int temp = vec[rand()%(R-L+1)+L];,同时通过百万、十万级别量的数据量来计算程序运行的时间比较时间复杂度。
计算时间的代码如下:
clock_t startime, endtime;
startime = clock();
....//中间代码
endtime = clock();
cout << (double)(endtime - startime)/ CLOCKS_PER_SEC << endl;
通过随机获取基准值优化代码如下:
#include<iostream>
#include<string>
#include<vector>
#include<time.h>
using namespace std;
//三色旗原理代码部分
pair<int, int> Quick(vector<int>& vec, int L, int R)
{
int temp = vec[rand()%(R-L+1)+L];//随机获取基准值进行优化
//int temp = vec[L];//没有获取随机基准值
int i = L - 1;//左边界
int j = R + 1;//右边界
int index = L;//交换变量
while (index < j)
{
if (vec[index] < temp)
{
swap(vec[index++], vec[++i]);
}
else if (vec[index] > temp)
{
swap(vec[index], vec[--j]);
}
else
{
index++;
}
}
pair<int, int> p = make_pair(i, j);//存储下次排序的左右边界,
return p;
}
void Quick_sort(vector<int>& vec, int L, int R)
{
if (L >= R)return;//递归结束的标志
pair<int, int> p = Quick(vec, L, R);
Quick_sort(vec, L, p.first);//将数组的左部分进行排序
Quick_sort(vec, p.second, R);//将数组的右部分进行排序
}
int main()
{
clock_t startime, endtime;
startime = clock();//开始时间
vector<int> vec;
for (int i = 0; i < 100000; i++) {
//(在这里使用十万级别的数据量 完全有序的数组进行计算时间复杂度 百万级别的数据量由于程序执行时间太长 不例举)
vec.push_back(i);
}
Quick_sort(vec, 0, vec.size() - 1);
/*for (auto it : vec)//在这里不进行输出,数据量太大
{
cout << it << " ";
}*/
endtime = clock();//结束时间
cout << (double)(endtime - startime)/ CLOCKS_PER_SEC << endl;
//在这里没有定义单位,只通过数值进行比较来判断
return 0;
}此时没有经过优化的代码执行时间如图:

经过优化的代码执行时间如图:

两者相对比较而言进行优化的时间复杂度远远小于未经过优化的。但是在数组里面的数据是乱序的情况下,经过优化的时间复杂度会偶尔出现略高于未经过优化的情况,但影响并不是很大。
3.2二路快速排序
接着前面所介绍来说,当我们排序的是一个近乎有序的序列时,快速排序会退化到一个O(n^2) 级别的排序算法,而我们对此的就是引入了随机化快速排序算法;但是问题又来了,当我们排序的数据是一个数值重复率非常高的序列时,或者是输入的数据完全相同的情况时,此时随机化快速排序算法就不再起作用了,而将会再次退化为一个O(n^2) 级别的排序算法。 在这种情况下不管是>=temp还是<=temp,当我们的序列中存在大量重复的元素时,排序完成之后就会将整个数组序列分成两个极度不平衡的部分,甚至更恶劣的情况是所有数据均一样而出现一边倒的趋势,所以又退化到了O(n^2) 级别的时间复杂度,这是因为对于每一个"基准"元素来说,重复的元素太多了,如果我们选的"基准"元素稍微有一点的不平衡,那么就会导致两部分的差距非常大;即时我们的"基准"元素选在了一个平衡的位置,但是由于等于"基准"元素的元素也非常多,也会使得序列被分成两个及其不平衡的部分,那么在这种情况下快速排序就又会退化成O(n^2) 级别的排序算法。 在这里我们可以使用二路快速排序进行优化。
原理:
前面所叙述的快速排序算法是将>temp和<temp两个部分元素都放在索引值i所指向的位置的左边部分,而双路快速排序则是使用两个索引值(i、j)用来遍历我们的序列,将<temp的元素放在索引 i 所指向位置的左边,而将>temp的元素放在索引j所指向位置的右边。
思想:
1、首先从左边的i索引往右边遍历,如果i指向的元素<temp,那直接将i++移动到下一个位置,直道i指向的元素>=temp则停止。
2、然后使用j索引从右边开始往左边遍历,如果j指向的元素>temp,那直接将j–移动到下一个位置,直道j指向的元素<=temp则停止
3、此时i之前的元素都已经归并为<temp的部分了,而j之后的元素也都已经归并为>temp的部分了,此时只需要将vec[i]和vec[j]交换位置即可。这样就可以避免出现=temp的元素全部集中在某一个部分,这正是双路排序算法的一个核心。但是当需要排序的数据长度比较小时,此时使用插入排序的性能比较好,所以我们结合快速排序和插入排序进行一个优化快速排序。
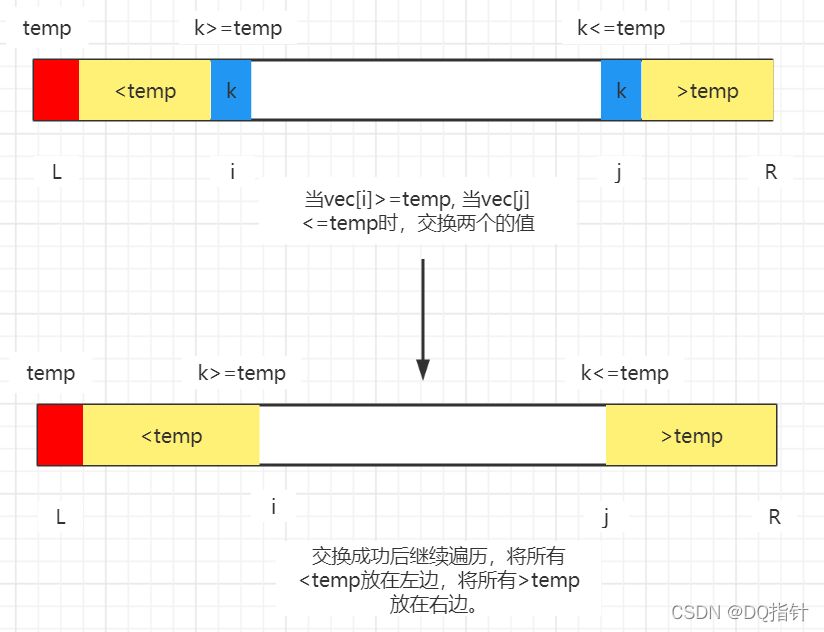
具体实现代码:
#include<iostream>
#include<vector>
#include<time.h>
using namespace std;
void Insert_sort(vector<int>& vec,int L,int R) {
for (int i = L+1; i < R; i++) {//用i来记录无序表的第一个值的下标
int j = i - 1;//用来记录前面有序列的最后一个值的下标
int temp = vec[i];//记录无序列的第一个值的值
for (; j >= 0; j--) {
if (vec[j] > temp) {
vec[j + 1] = vec[j];//将有序表中的元素后移。
}
else {
break;//当无序表中的第一个值不比有序表中的最后一个值小时,跳出循环
}
}
vec[j + 1] = temp;//将后移后的空值补上无序表中的第一个值。
}
}
int qucikSort(vector<int>& vec, int L, int R)
{
swap(vec[L], vec[rand() % (R - L + 1) + L]);// 随机产生"基准"元素所在位置,并与第一个元素交换位置
int temp = vec[L]; // 将第一个元素作为"基准"元素
// 使用i索引从左到右遍历,使用j索引从右到左遍历
int i = L + 1;// 索引值i初始化为第二个元素位置
int j = R;// 索引值j初始化为最后一个元素位置
while (true) {
while ((i < R) && (vec[i] < temp)) i++;// 使用索引i从左往右遍历直到 vec[i] < temp
while ((j > L + 1) && (vec[j] > temp)) j--;// 使用索引j从右往左遍历直到 vec[j] > temp
if (i >= j) break;// 退出循环的条件
swap(vec[i], vec[j]);// 将 vec[i] 与 vec[j] 交换位置
i++;
j--;
}
swap(vec[L], vec[j]);// 最后将"基准"元素temp放置到合适的位置
return j;
}
void quick(vector<int>& vec, int L, int R)
{
if (R - L <= 40) {//当数据量比较小时我们采用插入排序进行
Insert_sort(vec, L, R);
return;
}
int p = qucikSort(vec, L, R);// 对vec[left...right]区间元素进行排序操作,找到"基准"元素
quick(vec, L, p - 1);// 对基准元素之前的序列递归
quick(vec, p + 1, R);// 对基准元素之后的序列递归
}
int main()
{
clock_t startime, endtime;
startime = clock();//开始时间
vector<int> vec;
srand(time(0));
for (int i = 0; i < 100000; i++) {
//(在这里使用十万级别的数据量,完全有序的数组进行计算时间复杂度
// 百万级别的数据量由于程序执行时间太长,不例举)
vec.push_back(rand()%100);
}
quick(vec, 0, vec.size() - 1);
//for (auto it : vec)//在这里不进行输出,数据量太大
//{
// cout << it << " ";
//}
endtime = clock();//结束时间
cout << (double)(endtime - startime) / CLOCKS_PER_SEC << endl;
//在这里没有定义单位,只通过数值进行比较来判断
return 0;
}在这里随机数产生的数据进行性能分析,如图第一个数据是未经过优化的时执行一个利用随机生成数乱序并且重复率较高的执行时间,第二个数据是二路快速排序的执行时间。在这里执行时间相差不多是因为这里我们难以得到一个重复率非常高的一组数据,但是实际上双路快速排序优化的结果还是比较理想的。

4. 总结
在上述优化的过程中, 对于原始的快排来说,当重复率低,并且数组的有序化低是具有很好的效率,但是在应对大量的规则性比较强的数据时,效率是跟不上。而随机快速排序只是获取了一个随机基准值来应对数据有序化程度比较高的情况下来进行优化。但是二路快速排序结合了随机快排和插入排序来应对能够出现的所有情况来 达到比较好的效果。
到此这篇关于C++快速排序及优化方案详解的文章就介绍到这了,更多相关C++快速排序及优化内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!