
Java中的LinkedHashSet集合解读
作者:C陈三岁
LinkedHashSet介绍
LinkedHashSet是一个基于LinkedHashMap实现的有序去重集合列表。
- LinkedHashSet中的元素没有重复
- LinkedHashSet中的元素有顺序,维护了添加顺序
- LInkedHashSet可以存储null值
- LinkedHashSet是一个线程不安全的容器
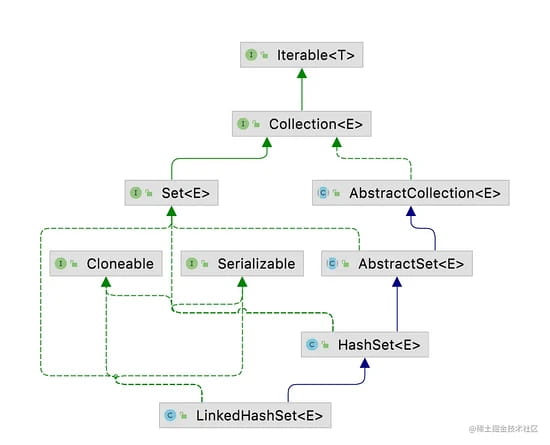
以上是LinkedHashSet的类结构图:
- 继承了HashSet,所以它是在HashSet的基础上维护了元素添加顺序的功能
构造方法
LinkedHashSet()
说明: 创建一个空的容器列表,默认的初始容量为16,负载因子为0.75
LinkedHashSet(int initialCapacity, float loadFactor)
说明:创建一个指定初始容量和负载因子的容器
关键方法
public boolean add(E e)
说明:向集合中添加元素
public boolean remove(Object o)
说明:向集合中删除元素
public void clear()
说明:清空集合元素
public int size()
说明:返回集合中元素的数量
使用案例
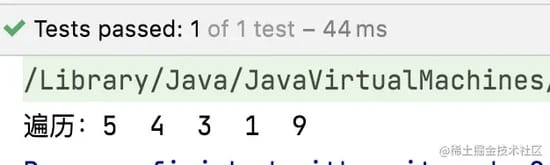
验证LinkedHashSet的顺序性
@Test
public void test1() {
Set<Integer> set = new LinkedHashSet<>();
set.add(5);
set.add(4);
set.add(5);
set.add(3);
set.add(1);
set.add(9);
//正顺序遍历
System.out.print("遍历:");
set.forEach(item -> {
System.out.print(item + " ");
});
}运行结果:
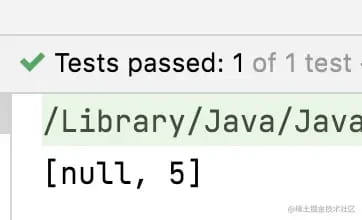
验证LinkedHashSet存储null值
@Test
public void test2() {
Set<Integer> set = new LinkedHashSet<>();
set.add(null);
set.add(5);
System.out.println(set);
}运行结果:
核心机制
底层有序性实现机制
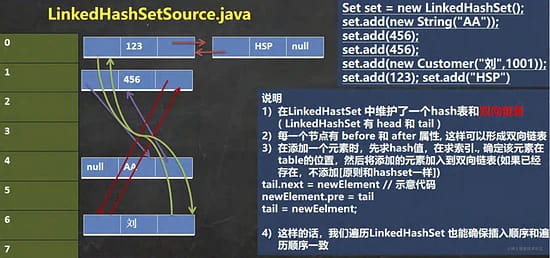
LinkedHashSet底层是一个 LinkedHashMap,底层维护了一个数组+双向链表。
它根据元素的hashCode值来决定元素的存储位置,同时使用链表维护元素的次序, 这使得元素看起来是以插入顺序保存的。
源码解析
本文主要从源码角度看下LinkedhashSet确实是依赖于LinkedHashMap,具体的逻辑还是要关注LinkedHashMap的实现。
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
public LinkedHashSet() {
super(16, .75f, true);
}
public LinkedHashSet(Collection<? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
}LinkedHashSet继承于HashSet,它的源码很少,只有几个构造函数,基本上都是调用父类HashSet的构造函数。
查看父类的构造函数,它是一个非public的构造函数,创建了一个LinkedHashMap, 所以说是依赖于LinkedHashMap实现的。

总结
LinkedHashSet主要适用于对于元素的添加顺序读取有要求的场景,比如FIFO这样的场景。
至于性能方面,大家也不用太过于担心,LinkedHashSet插入性能略低于HashSet,但在迭代访问set里面的全部元素时有很好的性能。
到此这篇关于Java中的LinkedHashSet集合解读的文章就介绍到这了,更多相关Java的LinkedHashSet内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!