
Java高并发下请求合并处理方式
作者:Soda_lw
Java高并发下请求合并处理
场景描述
在大并发量下每秒有一万个请求向后端查询数据,这样我们就需要向后端请求一万次,甚至查询一万次数据库。
我们要做的请求合并就是每隔一段时间(10ms)将这段时间内的请求合并到一起进行批量查询,减少查询数据库的次数。
思考
1、如何存放一段时间内的请求?这里我们可以用队列。
2、如何每隔一段时间执行任务?用定时任务线程池。
3、每个请求都是单独的线程,如何保证各个请求能得到自己的查询结果?这里我们使用callable返回查询结果,在没有查到结果前阻塞线程。
下面来看看具体实现的demo
package cn.codingxiaxw.combine;
import org.springframework.stereotype.Service;
import javax.annotation.PostConstruct;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.*;
import java.util.stream.Collectors;
@Service
public class QueryService {
//用来存放请求的队列,我们将请求封装成了一个Request对象
private LinkedBlockingQueue<Request> queue = new LinkedBlockingQueue<>() ;
//这个是我们的单个的查询方法,假设每隔请求都根据唯一的code进行查询
public Map<String,Object> query(String code){
//这个request是我们自定义的内部类
Request request = new Request();
request.code = code;
CompletableFuture<Map<String,Object>> future = new CompletableFuture<>();
request.future = future;
queue.add(request);
//阻塞 直到返回结果
try {
return future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
return null;
}
//这个是个模拟批量查询的方法
public List<Map<String,Object>> batchQuery(List<String> codes){
return null;
}
//封装的请求
class Request {
String code;
CompletableFuture<Map<String,Object>> future;
}
@PostConstruct
public void init(){
//在init方法中初始化一个定时任务线程,去定时执行我们的查询任务.具体的任务实现是我们根据唯一code查询出来的结果集,以code为key转成map,然后我们队列中的每个Request对象都有自己的唯一code,我们根据code一一对应,给相应的future返回对应的查询结果。
ScheduledExecutorService poolExecutor = new ScheduledThreadPoolExecutor(1);
poolExecutor.scheduleAtFixedRate(()->{
int size = queue.size();
//如果没有请求直接返回
if(size==0)
return ;
List<Request> list = new ArrayList<>();
for (int i = 0; i < size;i++){
Request request = queue.poll();
list.add(request);
}
System.out.println("批量处理:"+size);
List<String> codes = list.stream().map(s->s.code).collect(Collectors.toList());
//合并之后的结果集
List<Map<String, Object>> batchResult = batchQuery(codes);
Map<String,Map<String,Object>> responseMap = new HashMap<>();
for (Map<String,Object> result : batchResult) {
String code = result.get("code").toString();
responseMap.put(code,result);
}
//返回对应的请求结果
for (Request request : list) {
Map<String, Object> response = responseMap.get(request.code);
request.future.complete(response);
}
},0,10,TimeUnit.MILLISECONDS);
}
}利用请求合并发挥高并发下批量处理的优势
需求分析
我们经常会写一些查询接口,假设现在我们需要写一个查询用户信息的接口,要求传入用户Id,返回用户名称。
那么最简化的流程就是:用户发送请求->controller层->service层->dao层->数据库。
每次请求就相当于请求一条用户信息。
当这个接口被用户频繁请求时,此接口就不断的在做“请求”到“返回”的操作,服务端同时会开辟许多线程帮我们执行这些操作,这么多的线程会消耗许多系统资源,服务端承受了巨大压力。
//单查询接口
@GetMapping("/getUser")
public String getUser(Long key){
long currentMillis = System.currentTimeMillis();
//单查询service,大量线程怼到这个service上去
String userName = userService.getUser(key);
System.out.printf("##############################################\n");
System.out.printf("用户名为:" + userName + "---线程名为:" + Thread.currentThread().getName() +
"---执行时间为:" + (System.currentTimeMillis() - currentMillis) + "\n");
return userName;
}那么我们有什么方式可以优化这种操作呢?
我目前能想到的就是利用缓存(缓存热点数据)、消息队列(接收请求慢慢消费达到流量削峰)、多个服务实例(分散请求压力提高计算能力)等方式应对高并发场景。
在本文中,我利用另一种思路:把多个请求合并为一个请求,把单查询变为批量查询,这样就能有效减少开辟线程的数量。
具体实现
首先我们定义一个用户请求类Request:
//用户请求类
public class RequestTest {
//请求条件
private Long key;
//传话人
private CompletableFuture<String> future;
public CompletableFuture<String> getFuture() {
return future;
}
public void setFuture(CompletableFuture<String> future) {
this.future = future;
}
public Long getKey() {
return key;
}
public void setKey(Long key) {
this.key = key;
}
}接着是请求合并的主要代码:
//存放请求的队列
LinkedBlockingDeque<RequestTest> queue = new LinkedBlockingDeque<>();
//初始化方法
@PostConstruct
public void init() {
//定时执行的线程池,每隔5毫秒执行一次(间隔时间可以由业务决定),把所有堆积的请求
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(1);
executorService.scheduleAtFixedRate(() -> {
//在这里具体执行批量查询逻辑
int size = queue.size();
if (size == 0) {
//若没有请求堆积,直接返回,等10毫秒再执行一次
return;
}
//若有请求堆积把所有请求都拿出来
List<RequestTest> requestTests = new ArrayList<>();
for (int i = 0; i < size; i++) {
//把请求拿出来
RequestTest poll = queue.poll();
requestTests.add(poll);
}
//至此请求已经被合并了
System.out.printf("##############################################\n");
System.out.printf("请求合并了" + requestTests.size() + "条!\n");
//组装批量查询条件
List<Long> keyList = new ArrayList<>();
for (RequestTest requestTest : requestTests) {
keyList.add(requestTest.getKey());
}
//进行批量查询
List<User> nameList = userService.getUserList(keyList);
//把批查结果放入一个map
Map<Long,String> map = new HashMap<>();
for(User user:nameList){
map.put(user.getId(),user.getName());
}
for (RequestTest requestTest : requestTests){
//把放在map中的结果集放回给对应的线程
//future是对应每个请求的,因为是每个请求线程都传了自己的future是对应的过来
requestTest.getFuture().complete(map.get(requestTest.getKey()));
}
}, 0, 5, TimeUnit.MILLISECONDS);
}
//请求合并
@GetMapping("/requestMerge/getUser")
public String getUserRequestMerge(Long key) throws InterruptedException, ExecutionException {
long currentMillis = System.currentTimeMillis();
//CompletableFuture可以使一个线程执行操作后,主动返回值给另一个线程
CompletableFuture<String> future = new CompletableFuture<>();
RequestTest requestTest = new RequestTest();
//把future(把future可以认为是线程间的"传话人")放到等待队列中去,让定时调度的线程池执行并返回值
requestTest.setFuture(future);
requestTest.setKey(key);
//把requestTest加入等待队列(LinkedBlockingDeque)
queue.add(requestTest);
//future(传话人)阻塞直到有值返回
String userName = future.get();
System.out.printf("用户名为:" + userName + "---线程名为:"+Thread.currentThread().getName()+
"---执行时间为:"+(System.currentTimeMillis() - currentMillis)+"\n");
return userName;
}到这里我们就完成了一个请求合并的demo,接着我们测试运行结果。
这里我用了jemeter(jemeter的用法可以网上找一找)进行测试,对单查询接口和请求合并接口分别进行了20000次的请求,以下是结果对比:
(1)单查询运行结果:
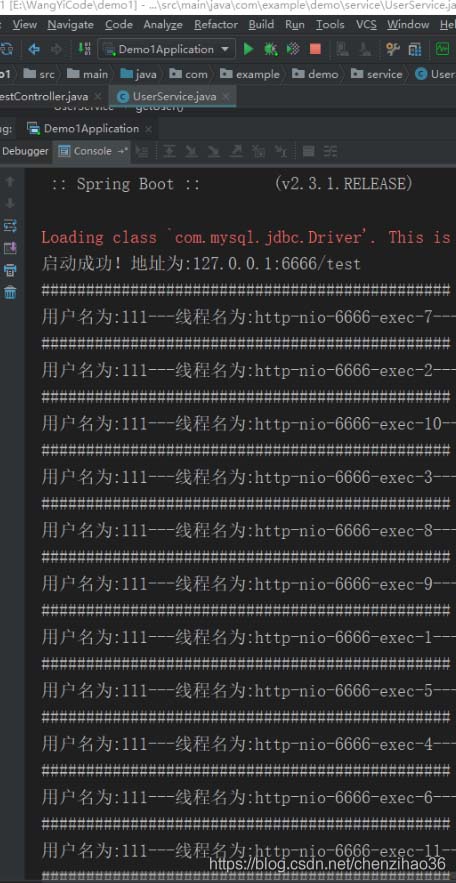
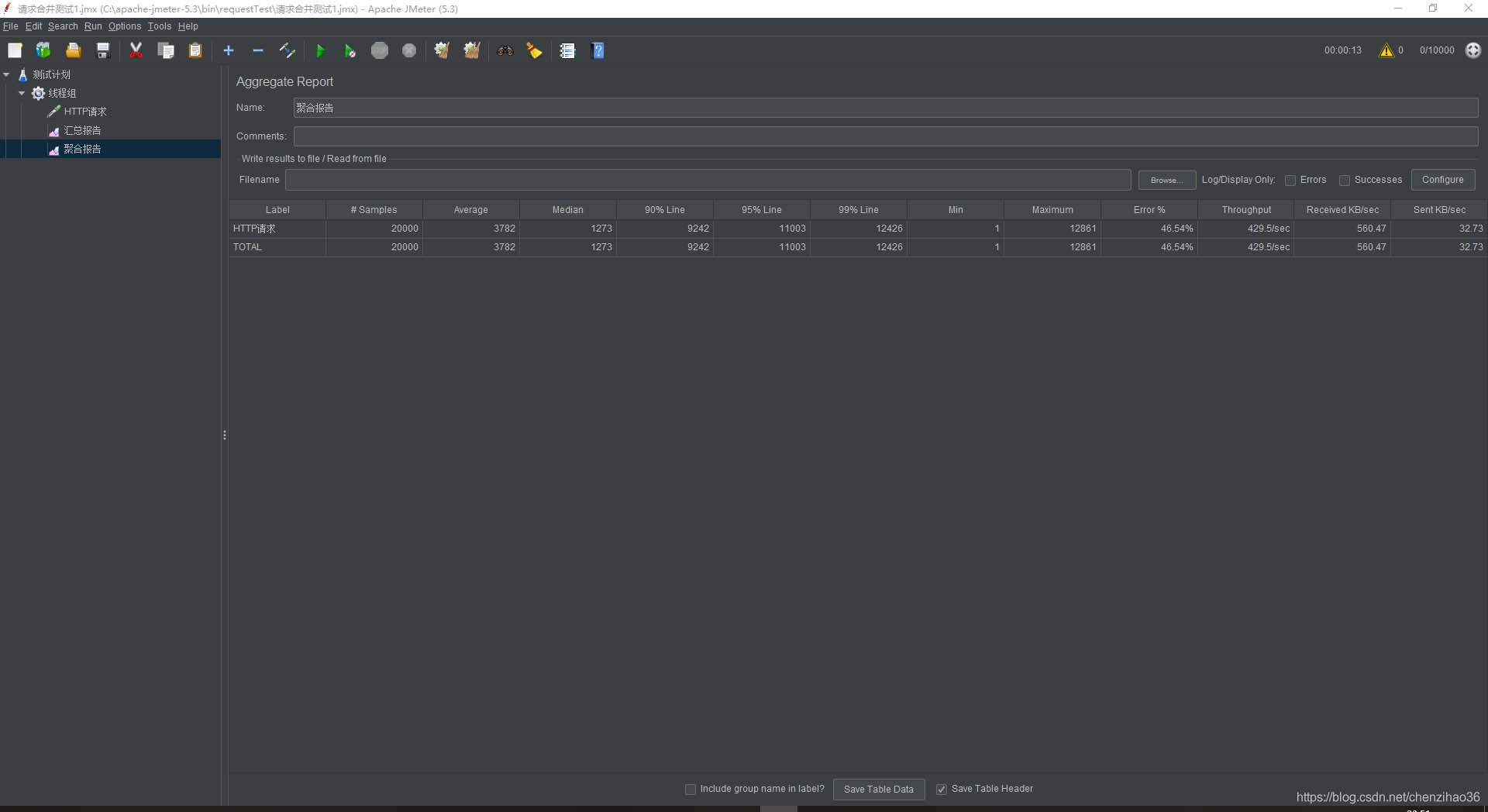
可以看到系统开辟了许多线程来处理请求,jemeter的聚合报告如下:
(2)请求合并运行结果:
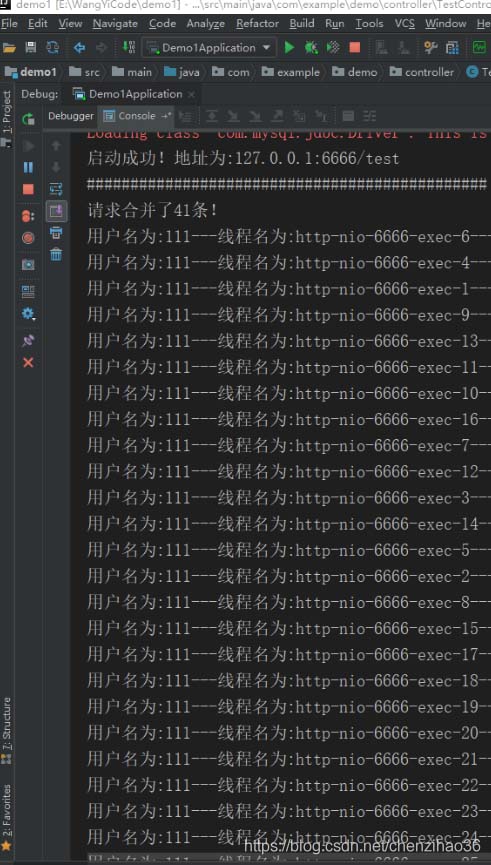
可以看到多条线程被合并成了一条线程来处理,jemeter的聚合报告如下:
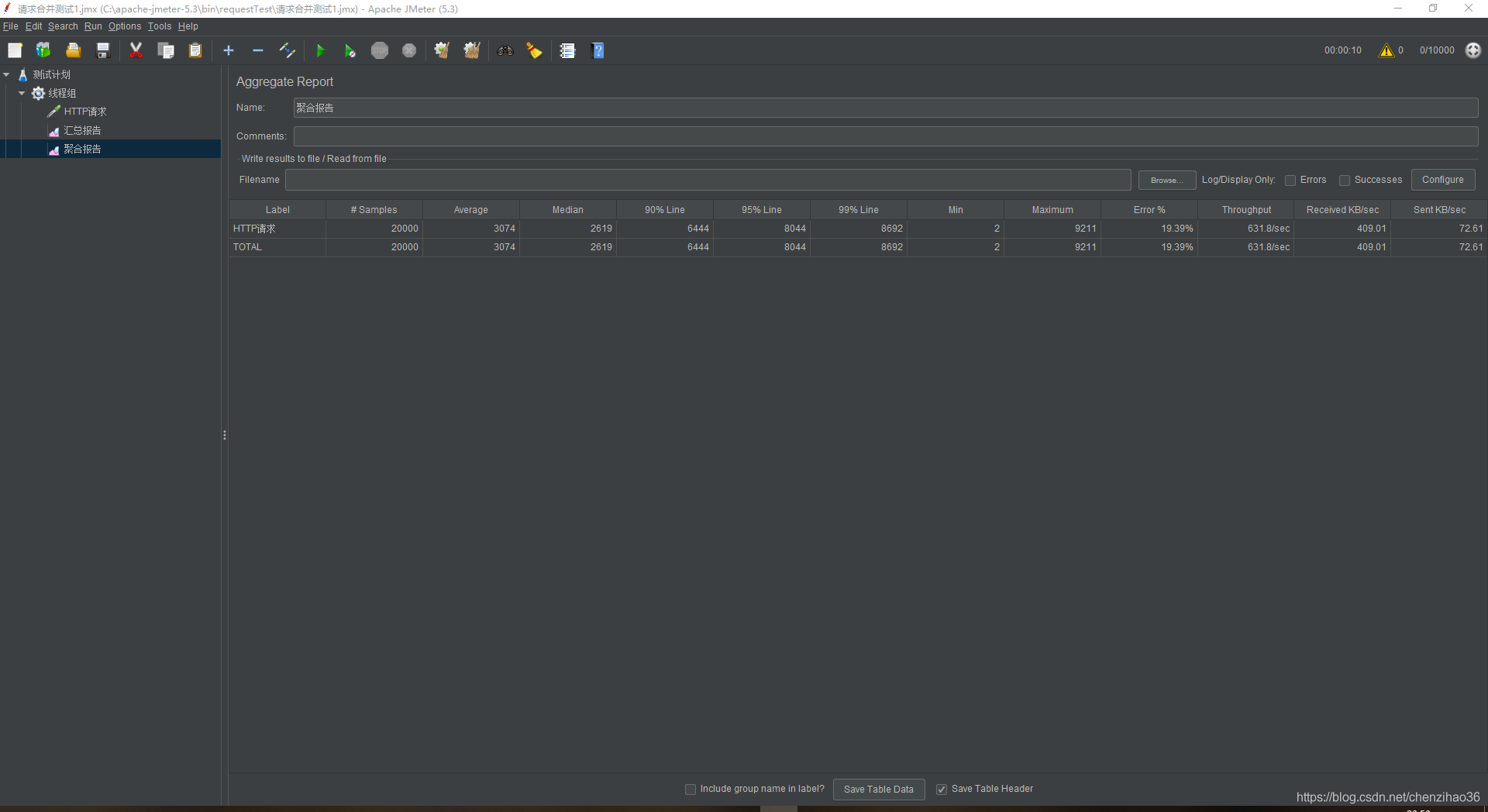
通过以上数据,我们可以看到,请求合并比单查询的吞吐量要大,并且在运行过程中,流量浮动的范围比较小。
至此,我们就完成了利用请求合并发挥高并发下批量处理的优势。
心得
本文我利用了LinkedBlockingDeque阻塞队列、ScheduledExecutorService定时执行线程池和CompletableFuture线程通信来完成了请求合并的demo。
并且通过实验证明高并发下批量处理比单个处理更有优势。
当然,我的demo并不完善。而且请求合并也有一些弊端,比如如果定时线程池的间隔时间比较长,反而会造成请求堆积时间太长,用户不能快速得到响应。
同时在请求数量比较小时,请求合并的场景也是没有必要的。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。