
SpringBoot中Redis的缓存更新策略详解
作者:ycfxhsw
常见的缓存更新策略
缓存一般是为了应对高并发场景、缓解数据库读写压力,而将数据存储在读写更快的某种存储介质中(如内存),以加快读取数据的速度。
缓存一般分为本地缓存(如java堆内存缓存)、分布式缓存(如Redis)等。
既然是缓存,就意味着缓存中暂存的数据只是个副本,也就意味着需要保证副本和主数据之间的数据一致性,这就是接下来要分析的缓存的更新。
常见的缓存更新策略有:
- 先删缓存,再更新数据库
- 先更新数据库,再删缓存
- 先更新数据库,再更新缓存
- read/write through
- 写回。在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库
一、先删缓存再更新数据库
很明显这个逻辑是有问题的,假设有两个并发操作,一个操作更新、另一个操作查询,更新操作删除缓存后还没来得及更新数据库,此时另一个用户发起了查询操作,它因没有命中缓存进而从数据库读,此时第一个操作还没到更新数据库的阶段,读取到的是老数据,接着写到缓存中,导致缓存中数据变成脏数据,并且会一直脏下去直到缓存过期或发起新的更新操作。
- 缓存初始值:A = 1
- 数据库初始值:A = 1
- 缓存最终值:A = 1
- 数据库最终值:A = 100
这个问题一般有两种处理方式:
- 加锁。锁,意味着要去解决并发问题,那么也就意味着并发的处理会被串行的处理,性能自然会略低。
- 对key加上过期时间,把控好这个过期时间,不过业务上本身是具备容忍这个时间内的数据不一致的问题方可。
- 降低出现这个问题的概率
二、先更新数据库,再删缓存
这是目前业界最常用的方案。虽然它同样不够完美,但问题发生的概率很小,它的读流程和写流程见下图(图片来源于网络,侵删):
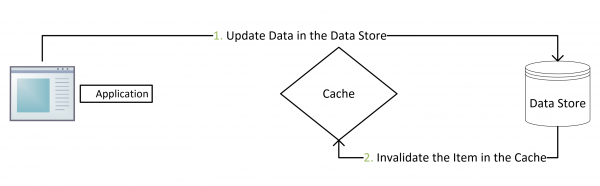
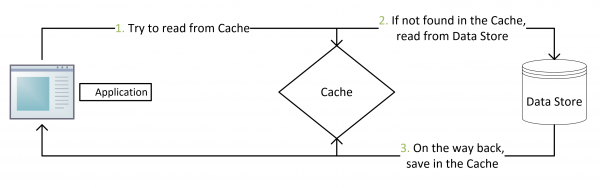
写操作先更新数据库,更新成功后使缓存失效。读操作先读缓存,缓存中读到了则直接返回,缓存中读不到再读数据库,之后再将数据库数据加载到缓存中。
但它同样也有问题,如下图,查询操作未命中缓存,接着读数据库老数据之后、写缓存之前,此时另一个用户发起了更新操作更新了数据库并清了缓存,接着查询操作将数据库中老数据更新到缓存。这就导致缓存中数据变成脏数据,并且会一直脏下去直到缓存过期或发起新的更新操作。
- 缓存初始值:空
- 数据库初始值:A = 1
- 缓存最终值:A = 1
- 数据库最终值:A = 100
为什么这种思路存在这么明显的问题,却还具有那么广泛的应用呢?因为这个case实际上出现的概率非常低,产生这个case需要具备如下4个条件:
- 读操作读缓存失效
- 有个并发的写操作
- 写操作比读操作更快
- 读操作早于写操作进入数据库,晚于写操作更新缓存
而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。并且即使出现这个问题还有一个缓存过期时间来自动兜底。
三、先更新数据库,再更新缓存
相对来讲,理论上这种方式比先更新数据库再删缓存有着更高的读性能,因为它事先准备好数据。
但由于要更新数据库和缓存两块数据,所以它的写性能就比较低,而且关键在于它也会出现脏数据,如下图,两个并发更新操作,分别出现一前一后写数据库、一后一前写缓存,则最终缓存的数据是二者中前一次写入的数据,不是最新的。
- 缓存初始值:A = 1
- 数据库初始值:A = 1
- 缓存最终值:A = 100
- 数据库最终值:A = 200
四、read/write through 缓存代理
Read/Write Through套路是把更新数据库(Repository)的操作由缓存自己代理了,所以,对于应用层来说,就简单很多了。可以理解为,应用认为后端就是一个单一的存储,而存储自己维护自己的Cache。
数据库由缓存代理,缓存未命中时由缓存加载数据库数据然后应用从缓存读,写数据时更新完缓存后同步写数据库。应用只感知缓存而不感知数据库。
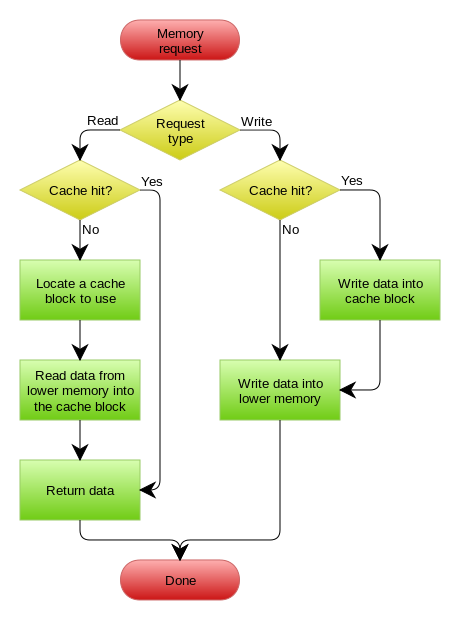
五、写回
这种方式英文名叫Write Behind 又叫 Write Back。一些了解Linux操作系统内核的同学对write back应该非常熟悉,这不就是Linux文件系统的Page Cache的算法吗?
是的,就是那个东西。这种模式是指在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。
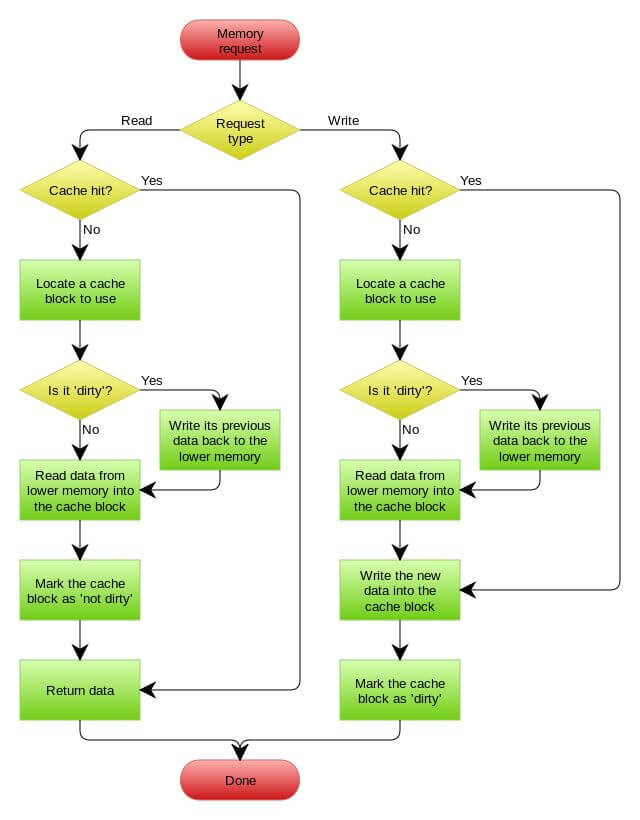
这种方式的问题在于数据不是强一致性的,而且可能会丢失(我们知道Unix/Linux非正常关机会导致数据丢失,就是因为这个)。
另外,Write Back实现逻辑比较复杂,因为他需要track有哪数据是被更新了的,需要刷到持久层上。
操作系统的write back会在仅当这个cache需要失效的时候,才会被真正持久起来,比如,内存不够了,或是进程退出了等情况,这又叫lazy write。
六、以第一种方式举例
- 失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
- 命中:应用程序从cache中取数据,取到后返回。
- 更新:先把数据存到数据库中,成功后,再让缓存失效。
大致流程如下:
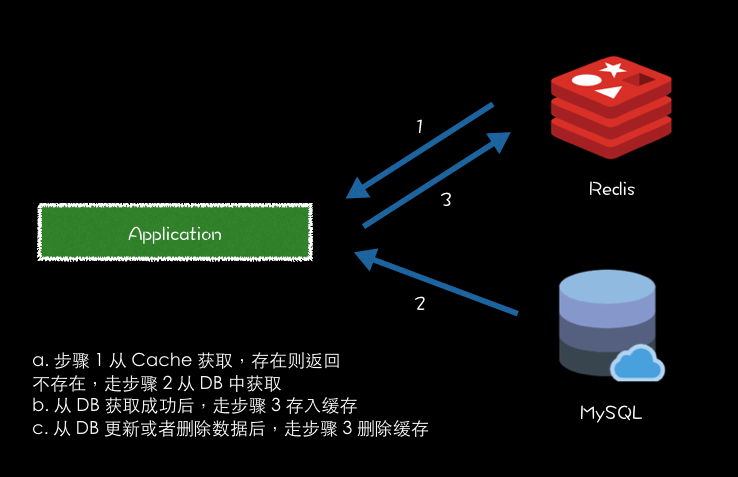
获取商品详情举例
- 从商品 Cache 中获取商品详情,如果存在,则返回获取 Cache 数据返回。
- 如果不存在,则从商品 DB 中获取。获取成功后,将数据存到 Cache 中。则下次获取商品详情,就可以从 Cache 就可以得到商品详情数据。
- 从商品 DB 中更新或者删除商品详情成功后,则从缓存中删除对应商品的详情缓存
添加maven依赖
这里是以MyBatis做数据库DAO操作,Redis做缓存操作。
SpringBoot 2开始默认的Redis客户端实现是 Lettuce ,同时你需要添加 commons-pool2 的依赖。
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>${jackson-databind-version}</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>${jackson-databind-version}</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>${jackson-databind-version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>com.vaadin.external.google</groupId>
<artifactId>android-json</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql-connector.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>${druid.version}</version>
</dependency>
<!-- MyBatis plus增强和springboot的集成-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatisplus-spring-boot-starter</artifactId>
<version>${mybatisplus-spring-boot-starter.version}</version>
</dependency>
</dependencies>注意上面我添加了Jackson的依赖,后面要用到。
配置application.yml
增加 Redis 相关配置
spring:
cache:
type: REDIS
redis:
cache-null-values: false
time-to-live: 600000ms
use-key-prefix: true
cache-names: userCache,allUsersCache
redis:
host: 127.0.0.1
port: 6379
database: 0
lettuce:
shutdown-timeout: 200ms
pool:
max-active: 7
max-idle: 7
min-idle: 2
max-wait: -1ms对应的配置类:
org.springframework.boot.autoconfigure.data.redis.RedisProperties
添加配置类
这里自定义RedisTemplate的配置类,主要是想使用Jackson替换默认的序列化机制:
@Configuration
public class RedisConfig {
/**
* redisTemplate 默认使用JDK的序列化机制, 存储二进制字节码, 所以自定义序列化类
* @param redisConnectionFactory redis连接工厂类
* @return RedisTemplate
*/
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
// 使用Jackson2JsonRedisSerialize 替换默认序列化
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(objectMapper);
// 设置value的序列化规则和 key的序列化规则
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}使用演示
MyBatis实现的DAO层,以及User实体类我就不贴在这里了,只贴Service核心增删改查操作:
@Service
@Transactional
public class UserService {
private Logger logger = LoggerFactory.getLogger(this.getClass());
@Resource
private UserMapper userMapper;
@Resource
private RedisTemplate<String, User> redisTemplate;
/**
* 创建用户
* 不会对缓存做任何操作
*/
public void createUser(User user) {
logger.info("创建用户start...");
userMapper.insert(user);
}
/**
* 获取用户信息
* 如果缓存存在,从缓存中获取城市信息
* 如果缓存不存在,从 DB 中获取城市信息,然后插入缓存
* @param id 用户ID
* @return 用户
*/
public User getById(int id) {
logger.info("获取用户start...");
// 从缓存中获取用户信息
String key = "user_" + id;
ValueOperations<String, User> operations = redisTemplate.opsForValue();
// 缓存存在
boolean hasKey = redisTemplate.hasKey(key);
if (hasKey) {
User user = operations.get(key);
logger.info("从缓存中获取了用户 id = " + id);
return user;
}
// 缓存不存在,从 DB 中获取
User user = userMapper.selectById(id);
// 插入缓存
operations.set(key, user, 10, TimeUnit.SECONDS);
return user;
}
/**
* 更新用户
* 如果缓存存在,删除
* 如果缓存不存在,不操作
* @param user 用户
*/
public void updateUser(User user) {
logger.info("更新用户start...");
userMapper.updateById(user);
int userId = user.getId();
// 缓存存在,删除缓存
String key = "user_" + userId;
boolean hasKey = redisTemplate.hasKey(key);
if (hasKey) {
redisTemplate.delete(key);
logger.info("更新用户时候,从缓存中删除用户 >> " + userId);
}
}
/**
* 删除用户
* 如果缓存中存在,删除
*/
public void deleteById(int id) {
logger.info("删除用户start...");
userMapper.deleteById(id);
// 缓存存在,删除缓存
String key = "user_" + id;
boolean hasKey = redisTemplate.hasKey(key);
if (hasKey) {
redisTemplate.delete(key);
logger.info("删除用户时候,从缓存中删除用户 >> " + id);
}
}
}RedisTemplate 封装了 RedisConnection,具有连接管理,序列化和 Redis 操作等功能。 还有专门针对 String 的模板对象 StringRedisTemplate。
Redis 操作视图接口类用的是 ValueOperations ,对应的是 Redis String/Value 操作。
还有其他的操作视图, ListOperations、SetOperations、ZSetOperations 和 HashOperations 。 ValueOperations 插入缓存是可以设置失效时间,这里设置的失效时间是 10 s。
然后写个测试类测试运行看看效果:
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
@Transactional
public class UserServiceTest {
@Autowired
private UserService userService;
@Test
public void testCache() {
int id = new Random().nextInt(1000);
User user = new User(id, "admin", "admin");
userService.createUser(user);
User user1 = userService.getById(id); // 第1次访问
assertEquals(user1.getPassword(), "admin");
User user2 = userService.getById(id); // 第2次访问
assertEquals(user2.getPassword(), "admin");
user.setPassword("123456");
userService.updateUser(user);
User user3 = userService.getById(id); // 第3次访问
assertEquals(user3.getPassword(), "123456");
userService.deleteById(id);
assertNull(userService.getById(id));
}
}运行SpringBoot集成测试,查看日志如下:
创建用户start...
==> Preparing: INSERT INTO t_user ( id, username, `password` ) VALUES ( ?, ?, ? )
==> Parameters: 89(Integer), admin(String), admin(String)
<== Updates: 1
获取用户start...
Starting without optional epoll library
Starting without optional kqueue library
==> Preparing: SELECT id AS id,username,`password` FROM t_user WHERE id=?
==> Parameters: 89(Integer)
<== Total: 1
获取用户start...
从缓存中获取了用户 id = 89
更新用户start...
==> Preparing: UPDATE t_user SET username=?, `password`=? WHERE id=?
==> Parameters: admin(String), 123456(String), 89(Integer)
<== Updates: 1
更新用户时候,从缓存中删除用户 >> 89
获取用户start...
==> Preparing: SELECT id AS id,username,`password` FROM t_user WHERE id=?
==> Parameters: 89(Integer)
<== Total: 1
删除用户start...
==> Preparing: DELETE FROM t_user WHERE id=?
==> Parameters: 89(Integer)
<== Updates: 1
更新用户时候,从缓存中删除用户 >> 89
获取用户start...
==> Preparing: SELECT id AS id,username,`password` FROM t_user WHERE id=?
==> Parameters: 89(Integer)
<== Total: 0
Rolled back transaction for test: [DefaultTestContext@6e20b53a testClass = UserServiceTest
Closing org.springframework.context.annotation.AnnotationConfigApplicationContext@503f91c3
{dataSource-1} closed
可以看出第一次取的时候,缓存未命中,会从DB中取数据,而第2次取的时候缓存命中直接从缓存中取出来。
后面不管是更新和删除,都会从缓存中删除。再去取的时候缓存未命中,从DB中取最新的。
七、总结
本文归纳了常见的缓存更新的五种思路,其中先更新数据库再删缓存的思路是目前使用得最多的。
先删缓存再更新数据库因为出问题概率太大并没有什么用。
第三到第五种思路在特定的应用场景下也有很多用途,比如先更新数据库再更新缓存可以解决高并发下缓存未命中导致瞬时大量请求穿透到数据库的问题。每一种方案也有其各自的优点和不足,总而言之,没有完美的方案,只有契合场景的更适合的方案。
到此这篇关于SpringBoot中Redis的缓存更新策略详解的文章就介绍到这了,更多相关Redis的缓存更新策略内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!