
springboot整合mongodb使用详解
作者:逆风飞翔的小叔
一、mongodb简介
1.1 什么是mongodb
MongoDB是一个文档数据库(以 JSON 为数据模型),由C++语言编写,旨在为WEB应用提供可扩展的高性能数据存储解决方案。
1.2 mongodb特点
- MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的;
- 它支持的数据结构非常松散,数据格式为BSON,一种类似JSON的二进制形式的存储格
- 式,简称Binary JSON ,和JSON一样支持内嵌的文档对象和数组对象,因此可以存储比较复杂的数据类型;
- MongoDB最大特点是支持的查询语言非常强大,语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引;
- 原则上 Oracle 和MySQL 能做的事情,MongoDB 都能做(包括 ACID 事务);
二、mongodb中的核心术语
在正式学习mogodb之前,有必要对mogodb中的基本术语和相关的语法做一个简单了解,就像学习mysql必须掌握其基本语法、DDL、DML等一样的道理,当然学习mogodb时可以类比mysql中的数据库,表和字段进行理解。
2.1 mogodb与数据库对比
MongoDB 概念与关系型数据库( RDBMS )非常类似,见下表;

2.2 mongodb中的核心概念
关于上述表中关于mongodb各个术语,再做简单的补充说明:
数据库(database)
最外层的概念,可以理解为逻辑上的名称空间,一个数据库包含多个不同名称的集合
集合(collection)
相当于SQL中的表,一个集合可以存放多个不同的文档
文档(document)
一个文档相当于数据表中的一行,由多个不同的字段组成
字段(field)
文档中的一个属性,等同于列(column)
索引(index)
独立的检索式数据结构,与SQL概念一致
id
每个文档中都拥有一个唯一的id字段,相当于SQL中的主键(primary key)
视图(view)
可以看作一种虚拟的(非真实存在的)集合,与SQL中的视图类似。从MongoDB3.4版本开始提供了视图功能,其通过聚合管道技术实现
聚合操作($lookup)
MongoDB用于实现“类似”表连接(tablejoin)的聚合操作符
2.3 与关系数据库的差异
尽管这些概念大多与SQL标准定义类似,但MongoDB与传统RDBMS仍然存在不少差异,包括:
2.3.1 半结构化
半结构化,在一个集合中,文档所拥有的字段并不需要是相同的,而且也不需要对所用的字段进行声明,因此,MongoDB具有很明显的半结构化特点。
2.3.2 支持多级嵌套
除了松散的表结构,文档还可以支持多级的嵌套、数组等灵活的数据类型,非常契合面向对象的编程模型。
2.3.3 关系弱化
弱关系,MongoDB没有外键的约束,也没有非常强大的表连接能力。类似的功能需要使用聚合管道技术来弥补。
三、mongodb 技术优势和应用场景
3.1 mongodb 技术优势
传统的关系型数据库(如MySQL),在数据操作的“三高”需求以及应对Web2.0的网站需求面前,逐渐开始显得吃力,对于数据库来说,尽管可以通过集群或其他方式对单节点的mysql实例进行扩展,但这样带来的成本和代价也是巨大的,由于mongodb从一开始就是为分布式而生,面对海量数据,高并发的场景有得天独厚的优势,同时其丰富的集群模式可以适应企业不同的数据运维和部署场景。
关于三高的解释补充
1、High performance - 对数据库高并发读写的需求;
2、Huge Storage - 对海量数据的高效率存储和访问的需求;
3、High Scalability && High Availability- 对数据库的高可扩展性和高可用性的需求;
3.2 mongodb 应用场景
从目前阿里云 MongoDB 云数据库上的用户看,MongoDB 的应用已经渗透到各个领域,这里总结如下:
游戏场景
使用 MongoDB 存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、更新;
物流场景
使用 MongoDB 存储订单信息,订单状态在运送过程中会不断更新,以MongoDB 内嵌
数组的形式来存储,一次查询就能将订单所有的变更读取出来;
社交场景
使用 MongoDB 存储存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实
现附近的人、地点等功能;
物联网场景
使用 MongoDB 存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析;
大数据应用
使用云数据库MongoDB作为大数据的云存储系统,随时进行数据提取分析,掌握行业动态
3.3 什么时候选择 mongodb
在上述的应用场景中,数据操作方面有如下一些共同的特点:
1)数据量大;
2)写入操作频繁(读写可能都很频繁);
3)价值较低的数据,对事务性要求不高;
对于这样的数据,我们更适合使用MongoDB来实现数据的存储。在实际架构选型上,除了上述的三个特点外,如果你还犹豫是否要选择它?可以考虑以下的一些问题:
1、应用不需要事务及复杂 join 支持;
2、新应用,需求会变,数据模型无法确定,想快速迭代开发;
3、应用需要2000-3000以上的读写QPS(更高也可以);
4、应用需要TB甚至 PB 级别数据存储;
5、应用发展迅速,需要能快速水平扩展;
6、应用要求存储的数据不丢失;
7、应用需要99.999%高可用;
8、应用需要大量的地理位置查询、文本查询;
如果上述有1个符合,可以考虑 MongoDB,2个及以上的符合,选择 MongoDB肯定不会错。
四、快速部署 mongodb
为方便后面代码整合使用,下面通过docker快速部署起一个mongodb的服务,按照下面的操作步骤执行;
4.1 搭建过程
4.1.1 拉取镜像
docker pull mongo:4.4

4.1.2 启动镜像
在启动镜像之前先创建一个数据目录的映射
mkdir data
使用下面的命令启动镜像
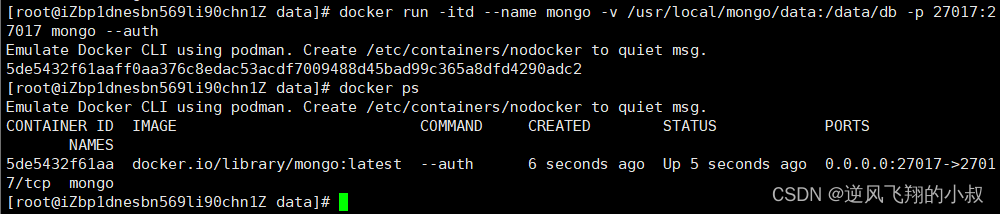
docker run -itd --name mongo -v /usr/local/mongo/data:/data/db -p 27017:27017 mongo:4.4 --auth
参数说明:
1)-p 27017:27017,映射容器服务的 27017 端口到宿主机的 27017 端口,外部可以直接通过 宿主机 ip:27017 访问到 mongo 的服务;
2)--auth:需要密码才能访问容器服务;
4.2 创建账户
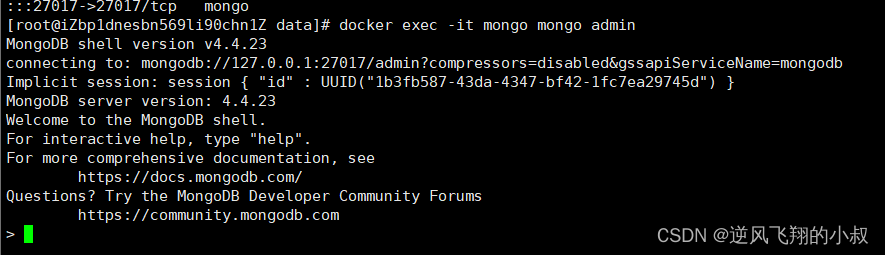
4.2.1 登录mongo容器,并进入到【admin】数据库
docker exec -it mongo mongo admin
4.2.2 创建一个用户
mongo 默认是没有用户的,这里root只是自己指定的用户名,可以自己命名
db.createUser({ user:'root',pwd:'123456',roles:[ { role:'userAdminAnyDatabase', db: 'admin'},'readWriteAnyDatabase']});
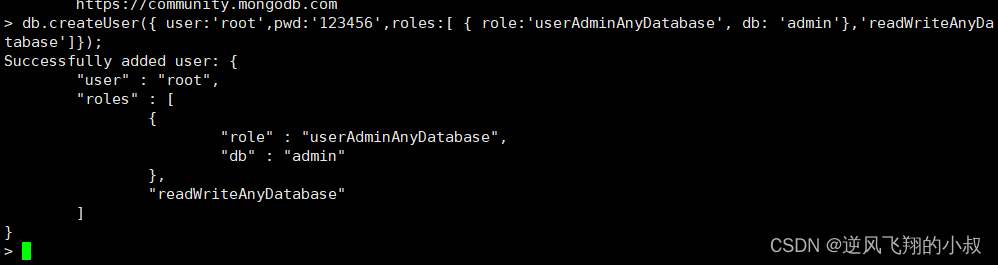
参数说明:
- 【user:‘root’ 】:设置用户名为root;
- 【pwd:‘123456’】:设置密码为123456;
- 【role:‘userAdminAnyDatabase’】:只在admin数据库中可用,赋予用户所有数据库的userAdmin权限;
- 【db: ‘admin’】:可操作的数据库;
- 【‘readWriteAnyDatabase’】:赋予用户读写权限;
dbAdmin:允许用户在指定数据库中执行管理函数,如索引创建、删除,查看统计或访问system.profile
4.3 连接与测试
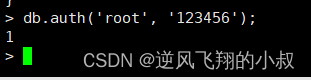
4.3.1连接mongo数据库
db.auth('root', '123456');
4.3.2 插入与查询数据
db.user.insert({"name":"zhangsan","age":18});
db.user.find();

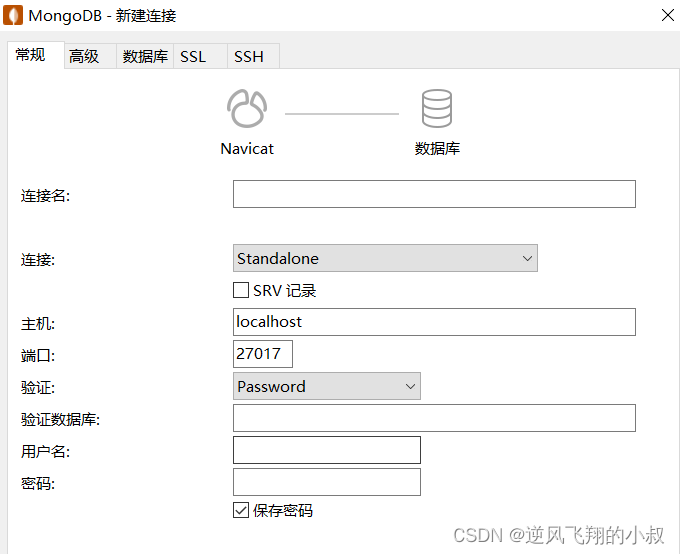
4.3.3 使用客户端连接
使用客户端工具连接,如下图所示,在下面填写自己的连接信息即可;
五、整合springboot使用
5.1 前置说明
springboot与mongodb整合使用通常有两种方式,这两种方式在开发过程中结合实际需要都可以选择;
5.1.1 jpa方式整合
使用过spingboot的jpa操作mysql的同学应该不陌生,这种方式的好处很明显,就是jpa中针对常用的对于数据库的CRUD操作相关的API做了封装,开发者对于常用的增删改查功能开发起来效率很高,缺点是如果业务操作比较复杂,需要编写比较复杂的sql语句时,使用jpa就不太方便了,尽管jpa也可以通过注解编写部分类sql语句,但是语法还是有一定上手成本的。
5.1.2 MongoTemplate 方式整合
很多第三方组件都与springboot做了整合集成,比如像redis提供了redisTemplate,kafka集成springboot时提供了kafkaTemplate等类似,mongodb也提供了MongoTemplate ,MongoTemplate 提供了满足日常开发需要的丰富的API,基本上涵盖了大部分的场景需求,学习成本较低,网上可以参阅的资料也比较丰富。可以作为第一选择。
为了更好的满足日常开发中的需要,下面将这两种方式的使用做一个详细的介绍。
5.2 准备一个数据库
为了方便后文中代码的测试,基于上面已经搭建完成的mongodb服务,使用root账户登录进去之后,创建一个名为 book的collection集合,创建也比较简单,使用上面的root用户登录进客户端之后,直接输入下面的命令即可创建;
use 你的数据库名称
5.3 jpa方式整合使用
5.3.1 创建一个springboot的工程
创建一个空的springboot工程,目录结构如下:

5.3.2 导入核心依赖
为了接口测试方便,引入了swagger的相关依赖;
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
<!--swagger API获取-->
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.9.2</version>
</dependency>
<!--swagger-ui API获取-->
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.9.2</version>
</dependency>
</dependencies>5.3.3 application 配置文件
application.yml中添加如下配置
spring:
data:
mongodb:
uri: mongodb://root:123456@IP地址:27017/book?authSource=admin&authMechanism=SCRAM-SHA-1
server:
port: 80825.3.4 实体数据对象
创建一个Book类,作为与mongo中的book这个collection集合的映射,对象中的属于对应着数据库中的collection的各个字段;
@Document(collection="book")
@Data
@AllArgsConstructor
@NoArgsConstructor
public class BookInfo {
@Id
private String id;
@Field("name")
private String name;
@Field("price")
private Integer price;
@Field("publish_time")
private String publishTime;
@Field("comment")
private String comment;
}5.3.5 jpa数据持久层
添加一个与mongodb集合交互的jpa接口,继承MongoRepository接口,使用过jpa的同学对此应该不陌生;
public interface BookRepository extends MongoRepository<BookInfo,String> {
}5.3.6 核心操作接口
为方便测试,创建一个接口类,由于基本的增删改查逻辑相对比较简单,直接调用MongoRepository即可,下面贴出基本的增删改查接口
@Autowired
private BookService bookService;
@PostMapping("/save")
public String save(BookInfo bookInfo) {
return bookService.saveBook(bookInfo);
}
@PostMapping("/update")
public String update(BookInfo bookInfo) {
return bookService.update(bookInfo);
}
@GetMapping("/delete")
public String deleteById(String id) {
return bookService.deleteById(id);
}
@PostMapping("/detail")
public BookInfo findById(String id) {
return bookService.findById(id);
}业务实现
@Autowired
private BookRepository bookRepository;
/**
* 保存
* @param bookInfo
* @return
*/
public String saveBook(BookInfo bookInfo){
bookInfo.setId(IdUtil.generateId());
bookRepository.save(bookInfo);
return "save book info success";
}
/**
* 修改
* @param bookInfo
* @return
*/
public String update(BookInfo bookInfo) {
if(StringUtils.isEmpty(bookInfo.getId())){
throw new RuntimeException("ID不能为空");
}
bookRepository.save(bookInfo);
return "save book info success";
}
/**
* 根据ID删除
* @param id
* @return
*/
public String deleteById(String id) {
bookRepository.deleteById(id);
return "delete success";
}
/**
* 查询所有
* @return
*/
public List<BookInfo> findList() {
return bookRepository.findAll();
}
/**
* 根据ID获取
* @param id
* @return
*/
public BookInfo findById(String id) {
Optional<BookInfo> bookInfoOptional = bookRepository.findById(id);
return bookInfoOptional.isPresent() ? bookInfoOptional.get() : null;
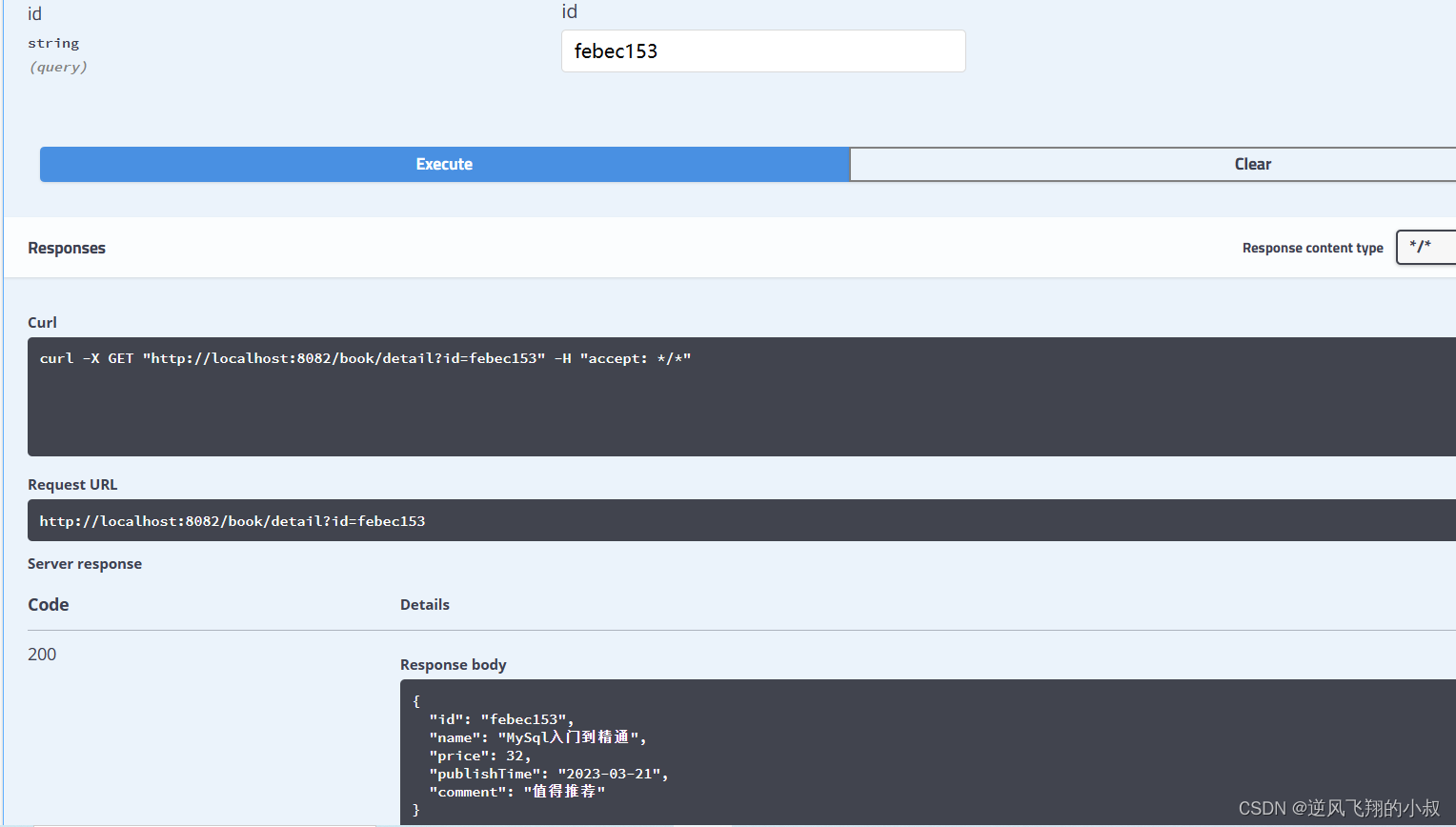
}以查询详情接口为例,在swagger中做一下测试,效果如下:
5.3.7 常用复杂查询接口
相信很多项目使用mongodb的一个重要的原因就是使用mongo进行查询时性能很高,尤其是针对一些复杂的查询场景时优势很明显,下面结合开发中其他比较常用的几个查询场景做一下补充;
模糊查询
主要用到了ExampleMatcher这个匹配对象,类似于mysql的: like '%关键字%';
/**
* 模糊查询
* @param name
* @return
*/
public List<BookInfo> query(String name) {
//构建匹配器对象
ExampleMatcher matcher = ExampleMatcher.matching()
.withStringMatcher(ExampleMatcher.StringMatcher.CONTAINING) //设置默认字符串匹配方式:模糊查询
.withIgnoreCase(true); //设置默认大小写忽略方式:true为忽略大小写
BookInfo bookInfo = new BookInfo();
bookInfo.setName(name);
Example<BookInfo> bookInfoExampleExample = Example.of(bookInfo,matcher);
List<BookInfo> bookInfos = bookRepository.findAll(bookInfoExampleExample);
return bookInfos;
}分页查询
public Page<BookInfo> pageQuery(Integer pageNo,Integer pageSize,String name) {
//构造排序器,设置排序字段
Sort sort = Sort.by(Sort.Direction.ASC,"price");
Pageable pageable = null;
if(Objects.isNull(pageNo) || Objects.isNull(pageSize)){
pageNo = 0;
pageSize=10;
}
pageable = PageRequest.of(pageNo, pageSize, sort);
//创建匹配器,设置查询条件
ExampleMatcher matcher = ExampleMatcher.matching() //构建匹配器对象
.withStringMatcher(ExampleMatcher.StringMatcher.CONTAINING) //设置默认字符串匹配方式:模糊查询
.withIgnoreCase(true); //设置默认大小写忽略方式:true为忽略大小写
//设置查询条件
BookInfo bookInfo = new BookInfo();
bookInfo.setName(name);
Example<BookInfo> bookExample = Example.of(bookInfo,matcher);
//查询
Page<BookInfo> page = bookRepository.findAll(bookExample, pageable);
return page;
}sql方式查询
某些情况下可能已有的API并不能很好的满足,就需要通过编写sql的方式实现了,在使用jpa操作mysql的时候俗称hql语言,关于使用MongoRepository编写类sql的相信资料可以参阅相关资料,网上可以搜到很多,其核心语法仍然是mongodb自身的那些操作语句,只是需要遵照Java中的编写规范;
下面提供了几个常用的查询,提供参考
public interface BookRepository extends MongoRepository<BookInfo,String> {
//根据名称查询
@Query("{name: ?0}")
List<BookInfo> findByBookName(String name);
//查询价格大于某个数的集合
@Query(value = "{price: { $gt: ?0 }}")
List<BookInfo> findByBookPriceThan(int price);
//查询ID在某个集合中,类似mysql 的 in ()语法
@Query(value = "{'_id':{$in:?0}}")
List<BookInfo> findAllByIdIn(List<String> ids);
}5.4 MongoTemplate 方式整合使用
MongoTemplate相对于MongoRepository来说,从API的使用上来说,选择更丰富,编码也更友好,同时API的使用也更加符合编码的习惯,下面再使用MongoTemplate 的方式做一下操作演示
配置文件等信息暂时不用修改
5.4.1 核心增删接口
接口层
@RestController
@RequestMapping("/template")
public class BookTemplateController {
@Autowired
private BookTemplateService bookTemplateService;
@PostMapping("/save")
public BookInfo save(BookInfo bookInfo){
return bookTemplateService.save(bookInfo);
}
@PostMapping("/update")
public BookInfo update(BookInfo bookInfo){
return bookTemplateService.update(bookInfo);
}
@GetMapping("/delete")
public String delete(String id){
return bookTemplateService.delete(id);
}
@GetMapping("/details")
public BookInfo details(String id){
return bookTemplateService.findById(id);
}
}业务实现
@Service
public class BookTemplateService {
@Autowired
private MongoTemplate mongoTemplate;
public BookInfo save(BookInfo bookInfo) {
bookInfo.setId(IdUtil.generateId());
BookInfo book = mongoTemplate.save(bookInfo);
return book;
}
public BookInfo update(BookInfo bookInfo) {
if(StringUtils.isEmpty(bookInfo.getId())){
throw new RuntimeException("ID为空");
}
Query query = Query.query(Criteria.where("_id").is(bookInfo.getId()));
BookInfo dbBook = mongoTemplate.findOne(query, BookInfo.class);
if(Objects.isNull(dbBook)){
return null;
}
Update update = new Update();
if(!StringUtils.isEmpty(bookInfo.getName())){
update.set("name",bookInfo.getName());
}
if(!StringUtils.isEmpty(bookInfo.getComment())){
update.set("comment",bookInfo.getComment());
}
if(Objects.nonNull(bookInfo.getPrice())){
update.set("price",bookInfo.getPrice());
}
mongoTemplate.updateFirst(query,update,BookInfo.class);
return bookInfo;
}
public String delete(String id) {
Query query = new Query(Criteria.where("_id").is(id));
mongoTemplate.remove(query,BookInfo.class);
return "deleted";
}
public BookInfo findById(String id) {
BookInfo bookInfo = mongoTemplate.findById(id, BookInfo.class);
return bookInfo;
}
}5.4.2 复杂查询接口
在实际业务开发中,更多的情况下会用到mongodb较复杂的查询,下面列举一些常用的复杂查询的场景提供参考
json字符串方式查询
如果在API调用过程中觉得书写不习惯的话,也支持原生的json语句查询,即将在客户端命令行中的查询语句转为json作为一个完整的语句进行查询
public List<BookInfo> queryByJson(String name,String type,Integer price) {
//String json1 = "{name:'" + name +"'}";
String json2 = "{$or:[{price:{$gt: '" +price+"'}},{type: '"+type+"'}]}";
Query query = new BasicQuery(json2);
//查询结果
List<BookInfo> employees = mongoTemplate.find(query, BookInfo.class);
return employees;
}模糊查询
类似于mysql中的like
//模糊查询
public List<BookInfo> queryLike(String key){
Query query = new Query(Criteria.where("name").regex(key));
List<BookInfo> bookInfos = mongoTemplate.find(query, BookInfo.class);
return bookInfos;
}范围查询
//查询价格大于某个值
public List<BookInfo> queryMoreThan(Integer price){
Query query = new Query(Criteria.where("price").gte(price));
List<BookInfo> bookInfos = mongoTemplate.find(query, BookInfo.class);
return bookInfos;
}多条件查询
类似于mysql中的多个条件通过and的查询
//多条件查询
public List<BookInfo> queryMultiParams(String name,String type,Integer price){
//or 条件查询
Criteria criteria = new Criteria();
/*criteria.orOperator(
Criteria.where("name").regex(name),
Criteria.where("price").gte(price),
Criteria.where("type").is(type)
);*/
//and 条件查询
criteria.andOperator(
Criteria.where("price").gte(price),
Criteria.where("type").is(type)
);
Query query = new Query(criteria);
List<BookInfo> bookInfos = mongoTemplate.find(query, BookInfo.class);
return bookInfos;
}
分页查询
//分页查询
public PageInfo<BookInfo> pageQuery(Integer pageIndex,Integer pageSize,String type){
Criteria criteria = new Criteria();
if(!StringUtils.isEmpty(type)){
criteria = Criteria.where("price").gte(type);
}
//TODO 如果有更多的查询条件,继续拼接 ...
Query query = new Query(criteria);
if(Objects.isNull(pageIndex) || Objects.isNull(pageSize)){
pageIndex = 1;
pageSize = 2;
}
//查询总数
long total = mongoTemplate.count(query, BookInfo.class);
System.out.println(total);
//查询结果根据价格排个序
query.with(Sort.by(Sort.Order.desc("price")))
.skip((pageIndex-1) * pageSize) //指定跳过记录数
.limit(pageSize); //每页显示记录数
List<BookInfo> bookInfos = mongoTemplate.find(query, BookInfo.class);
PageInfo<BookInfo> pageInfo = new PageInfo(pageIndex,pageSize,total,bookInfos);
return pageInfo;
}
5.4.3 聚合查询
聚合操作处理数据记录并返回计算结果(诸如统计平均值,求和等)。聚合操作组值来自多个文档,可以对分组数据执行各种操作以返回单个结果。聚合操作包含三类:单一作用聚合、聚合管道、MapReduce。
单一作用聚合
提供了对常见聚合过程的简单访问,操作都从单个集合聚合文档;
聚合管道
聚合管道是一个数据聚合的框架,模型基于数据处理流水线的概念。文档进入多级管道,将文档转换为聚合结果;
MapReduce
MapReduce操作具有两个阶段:处理每个文档并向每个输入文档发射一个或多个对象的map阶段,以及reduce组合map操作的输出阶段。
5.4.4 聚合统计查询案例
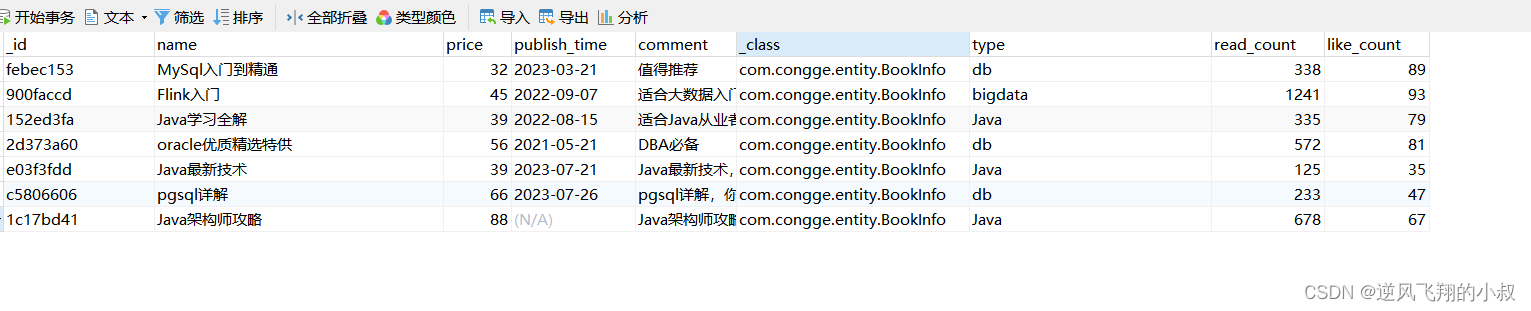
关于分组聚合统计的内容比较多,限于篇幅这里不做展开,我们将book这个collection集合的字段进行扩展(为了进行分组聚合使用),并插入一些数据,如下所示
下面我们要实现的需求是,
按照book的type字段进行分组,
1)统计每个type类型下的book的阅读总数,平均阅读数;
2)统计每个type类型下的book的喜欢总数,平均喜欢的数量;
完整的代码如下
public void groupQuery(){
// 查询条件
Criteria criteria = new Criteria();
MatchOperation matchOperation = Aggregation.match(criteria);
// 查询包括的字段
ProjectionOperation projectionOperation = Aggregation.project("id", "name","price", "type","readCount","likeCount");
// 分组统计
GroupOperation groupOperation = Aggregation.group("type")
//.first("type").as("type")
.count().as("typeCount")
.sum("likeCount").as("totalLike")
.avg("likeCount").as("avgLikeCount")
.sum("readCount").as("totalReadCount")
.sum("readCount").as("avgReadCount");
AggregationResults<Map> totalAuthorResult = mongoTemplate.aggregate(Aggregation.newAggregation(BookInfo.class,
matchOperation, projectionOperation, groupOperation), Map.class);
//获取分类总数
int typeCount = (int) totalAuthorResult.getMappedResults().size();
System.out.println(typeCount);
//得到最终分组聚合的结果
List<Map> mappedResults = totalAuthorResult.getMappedResults();
for(Map map :mappedResults){
System.out.println(map.keySet());
}
}通过debug,可以看到查询得到的结果如下

如果你需要获取最终的各个分组的统计结果,只需遍历上述的结果集即可。
六、结语
关于mongodb的技术体系是比较庞大的,本文只是冰山一角,要深入学习和掌握mongodb还需要实际开发过程中通过经验的积累才能加深对mongodb的理解和运用,随着技术的发展,mongodb在越来越多的领域都有着不错的运用,因此感兴趣的同学可以在此基础上深入研究。
以上就是springboot整合mongodb使用详解的详细内容,更多关于springboot整合mongodb的资料请关注脚本之家其它相关文章!